QUICK REVIEW
[論文レビュー] OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models
Anas Awadalla, Irena Gao|arXiv (Cornell University)|Aug 2, 2023
Multimodal Machine Learning Applications被引用数 70
ひとこと要約
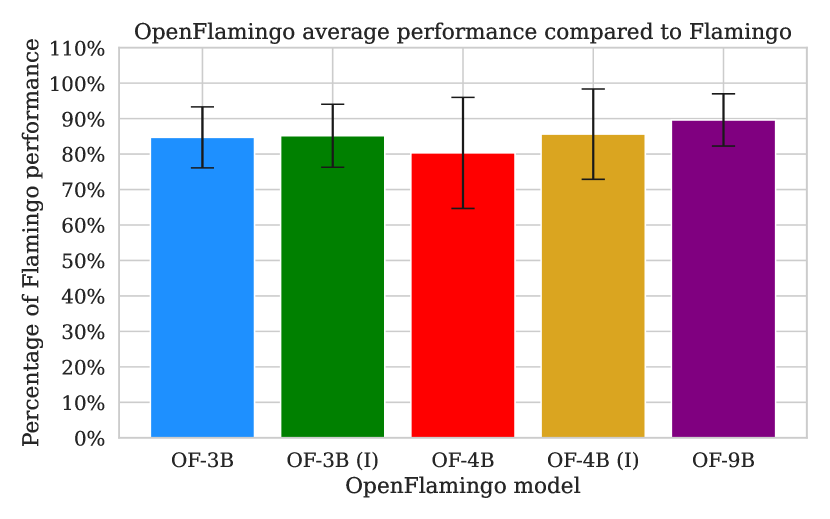
OpenFlamingo はウェブデータで訓練されたオープンソースの自己回帰型視覚言語モデル(3B–9B)で、イン・コンテキスト・デモンストレーションを用いて、7 つのデータセットにおける Flamingo の性能の約 80–89% を達成します。
ABSTRACT
We introduce OpenFlamingo, a family of autoregressive vision-language models ranging from 3B to 9B parameters. OpenFlamingo is an ongoing effort to produce an open-source replication of DeepMind's Flamingo models. On seven vision-language datasets, OpenFlamingo models average between 80 - 89% of corresponding Flamingo performance. This technical report describes our models, training data, hyperparameters, and evaluation suite. We share our models and code at https://github.com/mlfoundations/open_flamingo.
研究の動機と目的
- オープンソースの自己回帰型視覚言語フレームワークの創出を動機づけ、独自の重みやデータなしで研究を可能にする。
- 公開エンコーダとデコーダを使用して Flamingo スタイルのクロスアテンション視覚言語アーキテクチャを再現する。
- インコンテキスト・デモンストレーションを用いて多様な視覚言語タスクでオープンモデルを評価し、一般化と少数ショット能力を評価する。
- クローズド系モデルとの性能差を理解するため、データソースと訓練選択を分析する。
提案手法
- クロスアテンションを用いて凍結された言語モデルを凍結された視覚エンコーダに対して訓練可能なクロスアテンション・モジュールで結合し、Flamingo アーキテクチャを再現する。
- 凍結された視覚エンコーダ(CLIP ViT-L/14)を介して画像を埋め込み、画像埋め込みのための Perceiver リサンプリングを訓練する。
- オープンウェブ上のデータセット LAION-2B(画像-テキスト対)と MMC4(Multimodal C4)と、モデルの一部には ChatGPT が生成したシーケンスを用いて訓練する。
- <image> および <|endofchunk|> トークンでシーケンスを前処理し、AdamW 最適化で次のトークン予測を行う。
- 3B、4B、9B のパラメータスケールを用いた実験を行い、標準と言語バックボーンの指示学習(instruction-tuned)を含む。
- いくつかの設定でインコンテキスト例の数を0、4、8、16、32と変化させ、RICES(Retrieval-based In-Context Example Selection)を用いて評価する。
実験結果
リサーチクエスチョン
- RQ1オープンソースの自己回帰型視覚言語モデルは、さまざまな視覚言語タスクで Flamingo の性能にどれだけ近づけることができるか?
- RQ2モデルサイズ(3B、4B、9B)と言語モデルのバックボーン(標準 vs 指示学習)によるゼロショットおよびインコンテキスト学習の性能にどのような影響があるか?
- RQ3オープントレーニングデータ(LAION-2BおよびMMC4)とデータ処理の選択は、インコンテキスト学習と VQA 風タスクにどのような影響を与えるか?
- RQ4訓練可能な埋め込みと凍結された画像埋め込み、およびエンド・オブ・チャンク埋め込みは、下流の性能にどのような役割を果たすか?
- RQ5オープンソースモデルは、ファインチューニングされた最先端(SoTA)と比較して、インコンテキスト・デモンストレーションを使用して競争力のある結果を達成できるか?
主な発見
| Benchmark | Shots | Fl-3B | Fl-9B | OF-3B | OF-3B (I) | OF-4B | OF-4B (I) | OF-9B |
|---|---|---|---|---|---|---|---|---|
| COCO | 0 | 73.0 | 79.4 | 74.9 (0.2) | 74.4 (0.6) | 76.7 (0.2) | 81.2 (0.3) | 79.5 (0.2) |
| COCO | 4 | 85.0 | 93.1 | 77.3 (0.3) | 82.7 (0.7) | 81.8 (0.4) | 85.8 (0.5) | 89.0 (0.3) |
| COCO | 32 | 99.0 | 106.3 | 93.0 (0.6) | 94.8 (0.3) | 95.1 (0.3) | 99.2 (0.3) | 99.5 (0.1) |
| Flickr-30K | 0 | 60.6 | 61.5 | 52.3 (1.0) | 51.2 (0.2) | 53.6 (0.9) | 55.6 (1.3) | 59.5 (1.0) |
| Flickr-30K | 4 | 72.0 | 72.6 | 57.2 (0.4) | 59.1 (0.3) | 60.7 (1.2) | 61.2 (0.5) | 65.8 (0.6) |
| Flickr-30K | 32 | 71.2 | 72.8 | 61.1 (1.3) | 64.5 (1.3) | 56.9 (0.7) | 53.0 (0.5) | 61.3 (0.7) |
| VQAv2 | 0 | 49.2 | 51.8 | 44.6 (0.0) | 44.1 (0.1) | 45.1 (0.1) | 46.9 (0.0) | 52.7 (0.2) |
| VQAv2 | 4 | 53.2 | 56.3 | 45.8 (0.0) | 45.7 (0.1) | 49.0 (0.0) | 49.0 (0.0) | 54.8 (0.0) |
| VQAv2 | 32 | 57.1 | 60.4 | 47.0 (0.1) | 44.8 (0.1) | 43.0 (0.2) | 47.3 (0.0) | 53.3 (0.1) |
| OK-VQA | 0 | 41.2 | 44.7 | 28.2 (0.2) | 28.7 (0.1) | 30.7 (0.1) | 31.7 (0.1) | 37.8 (0.2) |
| OK-VQA | 4 | 43.3 | 49.3 | 30.3 (0.5) | 30.6 (0.2) | 35.1 (0.0) | 34.6 (0.0) | 40.1 (0.1) |
| OK-VQA | 32 | 45.9 | 51.0 | 31.0 (0.1) | 30.6 (0.1) | 26.4 (0.2) | 34.7 (0.3) | 42.4 (0.0) |
| TextVQA | 0 | 30.1 | 31.8 | 24.2 (0.2) | 23.1 (0.2) | 21.0 (0.3) | 21.1 (0.4) | 24.2 (0.5) |
| TextVQA | 4 | 32.7 | 33.6 | 27.0 (0.3) | 28.1 (0.4) | 25.9 (0.0) | 27.2 (0.3) | 28.2 (0.4) |
| TextVQA | 32 | 30.6 | 32.6 | 28.3 (0.2) | 28.5 (0.1) | 14.1 (0.2) | 23.2 (0.2) | 23.8 (0.2) |
| VizWiz | 0 | 28.9 | 28.8 | 23.7 (0.5) | 23.4 (0.3) | 18.8 (0.1) | 21.5 (0.2) | 27.5 (0.2) |
| VizWiz | 4 | 34.0 | 34.9 | 27.0 (0.3) | 27.7 (0.1) | 26.6 (0.5) | 26.5 (0.4) | 34.1 (0.7) |
| VizWiz | 32 | 45.5 | 44.0 | 39.8 (0.1) | 39.3 (0.4) | 23.1 (1.1) | 31.3 (0.2) | 44.0 (0.5) |
| HatefulMemes | 0 | 53.7 | 57.0 | 51.2 (2.5) | 50.1 (2.2) | 52.3 (2.3) | 53.1 (2.2) | 51.6 (1.8) |
| HatefulMemes | 4 | 53.6 | 62.7 | 50.6 (0.8) | 49.5 (0.6) | 51.5 (1.4) | 54.9 (1.1) | 54.0 (2.0) |
| HatefulMemes | 32 | 56.3 | 63.5 | 50.2 (1.8) | 47.8 (2.2) | 52.2 (1.2) | 54.9 (1.1) | 53.8 (2.1) |
- OpenFlamingo-3B および -9B は、7つのデータセット全体で Flamingo の性能の平均約 85% および 89% をそれぞれ達成する。
- 0-shot および 4-shot 設定では、OpenFlamingo-9B はいくつかのデータセットで Flamingo-9B に近づき、COCO、VQAv2、VizWiz で 4-shot の性能をほぼ同等に近づける。
- OpenFlamingo-4B モデルはしばしば 3B モデルより劣り、画像関連の埋め込みを凍結すると性能が大幅に低下する(例:COCOと VQAv2)。
- 言語指示学習(language-instruction-tuning)はいくつかの OpenFlamingo バリアントの性能を改善し、RedPajama-3B バックボーンで顕著な成果を示す。
- OpenFlamingo-9B は実質的な改善を示すが最先端には至らず、ファインチューニングされた SoTA 論文と比較すると、32 RICES デモンストレーションで平均約 62% のファインチューン SoTA に達する。
- データセットごとに性能傾向は異なり、VQAv2 は言語モデルの選択に大きく敏感である一方、COCO ベースの CIDEr スコアはインコンテキスト例を増やすにつれて着実に改善する。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。