[論文レビュー] Orca 2: Teaching Small Language Models How to Reason
Orca 2 は、小規模言語モデルを一連の推論戦略と Prompt Erasing 手法で訓練し、慎重な推論者となる。ゼロショットでの性能は大規模モデルと競合するほど高い。ウェイトは公開リリースされている。
Orca 1 learns from rich signals, such as explanation traces, allowing it to outperform conventional instruction-tuned models on benchmarks like BigBench Hard and AGIEval. In Orca 2, we continue exploring how improved training signals can enhance smaller LMs' reasoning abilities. Research on training small LMs has often relied on imitation learning to replicate the output of more capable models. We contend that excessive emphasis on imitation may restrict the potential of smaller models. We seek to teach small LMs to employ different solution strategies for different tasks, potentially different from the one used by the larger model. For example, while larger models might provide a direct answer to a complex task, smaller models may not have the same capacity. In Orca 2, we teach the model various reasoning techniques (step-by-step, recall then generate, recall-reason-generate, direct answer, etc.). More crucially, we aim to help the model learn to determine the most effective solution strategy for each task. We evaluate Orca 2 using a comprehensive set of 15 diverse benchmarks (corresponding to approximately 100 tasks and over 36,000 unique prompts). Orca 2 significantly surpasses models of similar size and attains performance levels similar or better to those of models 5-10x larger, as assessed on complex tasks that test advanced reasoning abilities in zero-shot settings. make Orca 2 weights publicly available at aka.ms/orca-lm to support research on the development, evaluation, and alignment of smaller LMs
研究の動機と目的
- 小規模LMにおける推論を強化するため、模倣学習を超える方向性を動機づける。
- 小規模LMに複数の推論戦略(ステップバイステップ、リコール→生成、リコール→推論→生成、直接回答 など)を活用させる。
- タスクごとに最も効果的な戦略を選択できるようにする(タスク駆動型戦略選択)。
- 約100のタスクと15のベンチマークを横断して Orca 2 を評価し、より大きなベースラインと比較する。
- 小規模LMの開発、評価、整合性に関する研究を支援するため、Orca 2 のウェイトを公開する。
提案手法
- 有能な教師から豊かな推論信号を提供する Explanation Tuning を活用する。
- 元のプロンプトにアクセスできずとも戦略を推定する慎重な推論者を訓練するために Prompt Erasing を導入する。
- FLAN-v2、Orca 1、Orca 2 のソースから、段階的学習を用いて Orca 2 データセット(約817K 訓練例)を構築する。
- FLAN-v2 から始め、次に Orca 1 データ、そして GPT-4 データを混ぜたデータで、LLaMA-2 基盤上に段階的学習を適用する。
- パッキングと最大 4096 トークンのシーケンス長を用いて、32台の A100 GPU(bf16)での訓練を最適化する;損失は教師生成トークンのみで計算する。
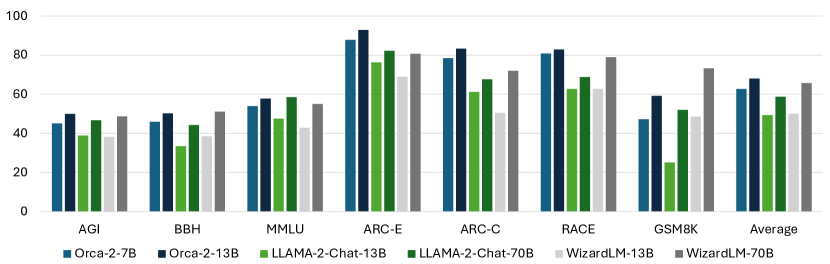
実験結果
リサーチクエスチョン
- RQ1小規模LMは、より大きなモデルの模倣を超えた推論戦略のレパートリーを学習し適用できるか?
- RQ2小規模LMは、与えられたタスクに対して最も効果的な推論戦略をどのように選択すべきか?
- RQ3Prompt Erasing を用いた慎重な推論は、標準的な模倣ベースのアプローチと比べてゼロショット性能を向上させるか?
- RQ4多様な推論ベンチマークにおいて Orca 2 のモデルは、より大きなモデルとどう比較されるか?
主な発見
| モデル | AGI | BBH | DROP | CRASS | RACE | GSM8K |
|---|---|---|---|---|---|---|
| Orca 2-7B | 45.10 | 45.93 | 60.26 | 84.31 | 80.79 | 47.23 |
| Orca 2-7B w/ cautious sm | 43.97 | 42.80 | 69.09 | 88.32 | 75.82 | 55.72 |
| Orca 2-13B | 49.93 | 50.18 | 57.97 | 86.86 | 82.87 | 59.14 |
| Orca 2-13B w/ cautious sm | 48.18 | 50.01 | 70.88 | 87.59 | 79.16 | 65.73 |
| Orca-1-13B | 45.69 | 47.84 | 53.63 | 90.15 | 81.76 | 26.46 |
| LLaMA-2-Chat-13B | 38.85 | 33.6 | 40.73 | 61.31 | 62.69 | 25.09 |
| WizardLM-13B | 38.25 | 38.47 | 45.97 | 67.88 | 62.77 | 48.60 |
| LLaMA-2-Chat-70B | 46.70 | 44.68 | 54.11 | 74.82 | 68.79 | 52.01 |
| WizardLM-70B | 48.73 | 51.08 | 59.62 | 86.13 | 78.96 | 73.24 |
| ChatGPT | 53.13 | 55.38 | 64.39 | 85.77 | 67.87 | 79.38 |
| GPT-4 | 70.40 | 69.04 | 71.59 | 94.53 | 83.08 | 85.52 |
- Orca 2-13B は、同じサイズのモデルと比べてゼロショット推論タスクで著しく上回る。
- Orca 2-13B は、いくつかの高度な推論ベンチマークで、5〜10倍大きいモデルと同等かそれ以上である。
- 慎重なシステムプロンプトを用いると、Orca 2 はいくつかのデータセット(例: CRASS、DROP、RACE、GSM8K)で顕著な改善を達成する。
- 全体として、Orca 2–13B は 70B パラメータのライバルに対して競争力の性能と、より強力なゼロショット推論能力を示す。
- この研究は AGIeval、BBH、DROP、CRASS、RACE、GSM8K などを横断した詳細なゼロショット結果を報告し、堅牢な推論能力を示している。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。