[論文レビュー] OWQ: Outlier-Aware Weight Quantization for Efficient Fine-Tuning and Inference of Large Language Models
OWQ は、弱い列を高精度のまま維持し、残りを量子化するアウトライヤ対応の重み量子化を提示し、Weak Column Tuning (WCT) を組み合わせてタスク特化適応を実現し、約 3.1-bit 程度で 4-bit OPTQ と同等の品質を達成し、ファインチューニングを効率化する。
Large language models (LLMs) with hundreds of billions of parameters require powerful server-grade GPUs for inference, limiting their practical deployment. To address this challenge, we introduce the outlier-aware weight quantization (OWQ) method, which aims to minimize LLM's footprint through low-precision representation. OWQ prioritizes a small subset of structured weights sensitive to quantization, storing them in high-precision, while applying highly tuned quantization to the remaining dense weights. This sensitivity-aware mixed-precision scheme reduces the quantization error notably, and extensive experiments demonstrate that 3.1-bit models using OWQ perform comparably to 4-bit models optimized by OPTQ. Furthermore, OWQ incorporates a parameter-efficient fine-tuning for task-specific adaptation, called weak column tuning (WCT), enabling accurate task-specific LLM adaptation with minimal memory overhead in the optimized format. OWQ represents a notable advancement in the flexibility, efficiency, and practicality of LLM optimization literature. The source code is available at https://github.com/xvyaward/owq
研究の動機と目的
- 推論およびファインチューニング時に大規模言語モデルのメモリおよび計算量のフットプリントを削減する動機づけ。
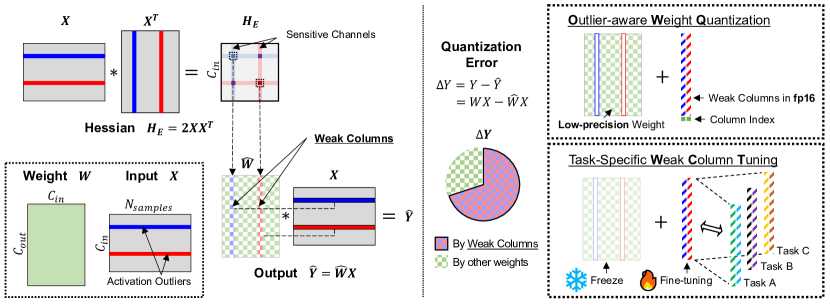
- LLM における量子化誤差の重要な源として活性化のアウトライヤを特定。
- OWQ を提案して敏感(弱い)列を保護し、残りを積極的に量子化。
- OWQ 量子化モデル上でパラメータ効率の良いタスク適応を可能にする WCT を導入。
- 低オーバーヘッドで OPT および LLaMA 系列における利得を実証。
提案手法
- ハッセ行列の対角成分とウェイトの摂動量の大きさを用いてチャンネルごとの感度を計算し、弱い列を識別する(sensitivity_j = lambda_j * ||Delta W_:,j||^2)。
- 弱い列を量子化から除外し、残りの列を OPTQ ベースの手法で混合精度で量子化し、切り捨て強化構成探索を含む。
- 各列ごとに弱い列を fp16 で格納し、弱い列を指定する小さなインデックスを付与して、ストレージオーバーヘッドを ~0.3% 程度に抑える。
- 非弱列には変更済みの構成探索を用いて切り捨てとチャネル毎の量子化を考慮した OPTQ を適用する。
- OWQ 量子化後に事前に識別された弱い列のみを微調整する Weak Column Tuning (WCT) を導入し、メモリオーバーヘッドを最小化しつつタスク適応性を向上させる。
- 弱い列を動的に処理するカスタムOWQ CUDAカーネルを用いて実機加速を実証する。
実験結果
リサーチクエスチョン
- RQ1活性化のアウトライヤを量子化誤差の低減に effectively 確率的に考慮できるか。
- RQ2弱い列を意識した混合精度方式(OWQ)が、低い実効ビット幅で高ビットベースライン(例:4-bit OPTQ)と同等の性能を達成できるか。
- RQ3WCT が OWQ 量子化モデルのファインチューニング性能を競合または優越させつつ、メモリオーバーヘッドを低く保てるか。
- RQ4OPT や LLaMA のような大規模モデルで、推論およびファインチューニング時の OWQ の実用的オーバーヘッド(遅延とストレージ)はどれほどか。
主な発見
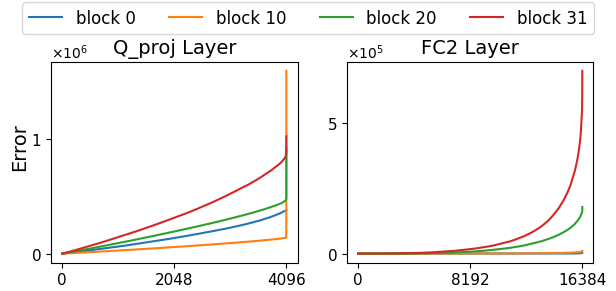
- 3.1-bit OWQ モデルは WikiText-2 のパープレキシティおよび関連指標で、モデル規模を問わず 4-bit OPTQ と同等の性能を達成。
- 3.01-bit OWQ モデルは結果をさらに改善し、3-bit OPTQ を上回り、OPT および LLaMA ファミリ全体で改善を観測。
- OWQ は複数のモデルサイズで OPTQ を一貫して上回る品質向上を示し、量子化劣化がより顕著な小型モデルでも改善を達成。
- 弱い列の意識(高精度の少数列を保持)によりストレージ負荷はほぼゼロの ~0.3% 程度で、精度に substantial な向上を提供。
- WCT は QLoRA よりはるかに少ない訓練可能パラメータでタスク特異的適応を可能にし、推論時のメモリ使用を大幅に抑えつつ全精度 LoRA の性能に匹敵。
- OWQ はカスタマイズされた CUDA カーネルを用いて、混合精度処理にも関わらず現実的な量子化速度を維持(例:A100 上で 66B モデルを量子化するのに約 3 時間未満)を実現。
- ファインチューニングシナリオでは、OWQ+WCT が競合する PTQ ベースのファインチューニング手法を上回り、GPT-4 ベースのスコアリングを用いた Vicuna Benchmark の結果で強力な open-LM タスク性能を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。