[論文レビュー] PaDeLLM-NER: Parallel Decoding in Large Language Models for Named Entity Recognition
PaDeLLM-NER は、LLMs におけるすべてのラベル-メンションペアを並列デコードすることで NER 推論を高速化し、出力長と待機時間を削減しつつ予測品質を維持します。
In this study, we aim to reduce generation latency for Named Entity Recognition (NER) with Large Language Models (LLMs). The main cause of high latency in LLMs is the sequential decoding process, which autoregressively generates all labels and mentions for NER, significantly increase the sequence length. To this end, we introduce Parallel Decoding in LLM for NE} (PaDeLLM-NER), a approach that integrates seamlessly into existing generative model frameworks without necessitating additional modules or architectural modifications. PaDeLLM-NER allows for the simultaneous decoding of all mentions, thereby reducing generation latency. Experiments reveal that PaDeLLM-NER significantly increases inference speed that is 1.76 to 10.22 times faster than the autoregressive approach for both English and Chinese. Simultaneously it maintains the quality of predictions as evidenced by the performance that is on par with the state-of-the-art across various datasets.
研究の動機と目的
- 大規模言語モデルを用いた Named Entity Recognition の生成待機時間を低減する。
- 新しいモジュールやアーキテクチャの変更を追加せずに並列デコードを統合する。
- 英語および中国語の NER データセットにおいて予測品質を維持するか、上回る。
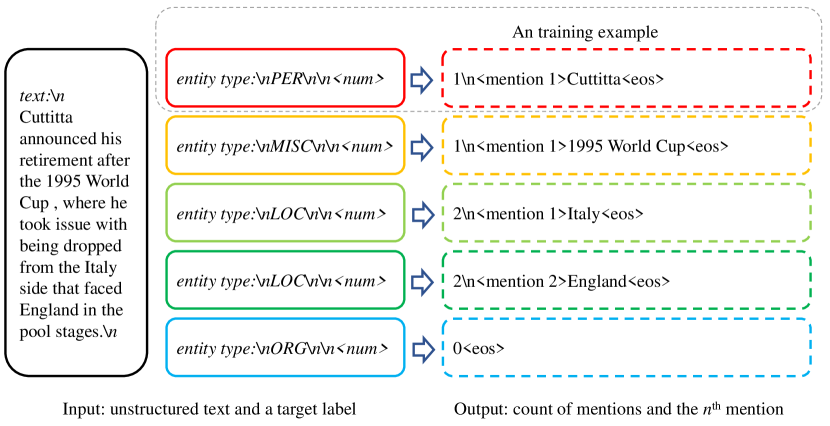
- ラベルごとの出現回数を数え、n番目の出現を識別することを支援するようにトレーニングを再構成する。
- 並列デコードされたラベル-メンションペアの集約と重複排除を可能にする。
提案手法
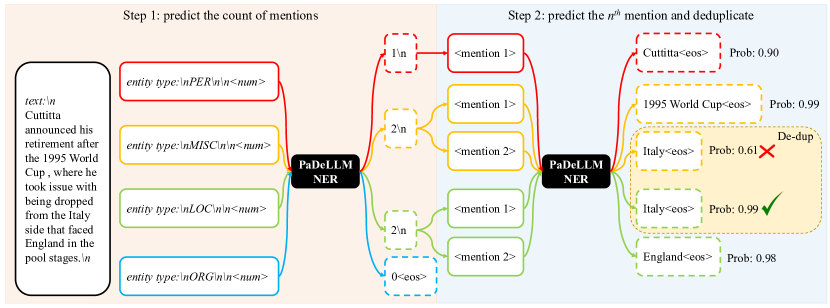
- 入力内の各ラベルの出現数と n 番目の出現を予測するように、指示調整を再構成する。
- 推論時にはまずラベルごとの出現数を予測し、次にすべてのラベル-メンションペアを並列生成して結果を集約する。
- ユニークなテキストごとに最高確率のインスタンスを保持して、ラベル間の出現を重複排除する。
- 2つの推論モードを使用する: PaDeLLM Multi(マルチGPU、シーケンスごとのGPU)と PaDeLLM Batch(バッチ処理付きの単一GPU)。
- カウント予測に続くシーケンストークンに対してクロスエントロピーロスを用いて訓練し、アブレーションの所見に基づき、出現範囲トークンを適切に無視する。
実験結果
リサーチクエスチョン
- RQ1ラベル-メンションペアの並列デコードは、精度を損なうことなく NER 推論待機時間を削減できますか?
- RQ22ステップのカウントとメンション戦略は、英語および中国語の NER データセットの予測品質にどう影響しますか?
- RQ3重複排除が多ラベル NER 出力の精度(precision)、再現率(recall)、および全体の F1 に及ぼす影響は?
- RQ4PaDeLLM-NER の高速化は、言語を跨ぐ平坦およびネストした NER タスクにおいて、自動回帰ベースラインとどのように比較されますか?
主な発見
- PaDeLLM-NER は自動回帰ベースラインと比較して推論待機時間を大幅に削減(1.76倍〜10.22倍のスピードアップ)。
- 1件あたりの平均シーケンス長は自動回帰法の約13%に削減され、これが速度向上に寄与している。
- PaDeLLM-NER は平均 micro-F1 約84.79を達成し、英語および中国語のデータセットのいくつかでベースラインを上回る(9データセット中4データセットで最高)。
- 2段階のカウントとメンションのアプローチにより、ラベル-メンションペアをバッチで並列デコードできる。
- ラベルを横断して最高確率のインスタンスを選択する重複排除は、再現率を大きく落とすことなく精度を向上させる。
- この手法は多くのデータセットで最先端手法と互角であり、特に Weibo、Youku、ACE2005 で優れている。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。