[論文レビュー] PaLM 2 Technical Report
PaLM 2 は、PaLM に対して多言語対応・推論・効率性の改善を備えた Transformer ベースの言語モデルであり、事前学習目的の混成、多言語データ、および推論時の毒性制御を特徴とする。
We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
研究の動機と目的
- PaLM 2 を用いた英語および多言語タスクにおいて、最先端の言語モデリングを実証する。
- スケーリング法則とデータミックスが性能と効率に与える影響を評価する。
- 多様なデータセットにわたる多言語能力、推論、コーディング、翻訳、生成を評価する。
- メモリ、毒性制御、偏りなどの責任あるAIの側面を検討する。
- 下流の研究者向けの設計上の考慮事項、学習データ、評価方法論を説明する。
提案手法
- UL2 に触発された事前学習目的の調整混成を備えた Transformer ベースのアーキテクチャを用いる。
- ウェブ、書籍、コード、数学、および並列多言語データを含む多様な多言語前訓練コーパスで学習する。
- FLOPs 予算全体で最適なモデルサイズとデータ要件を推定する計算最適化スケーリング分析を適用する。
- 言語能力試験、分類/QA、推論、コーディング、翻訳、生成のベンチマークで評価する。
- 他の機能を犠牲にせず毒性を管理するための推論時制御トークンを組み込む。
- 付録および D セクションで記憶化、偏り、責任あるAIの考慮事項の詳細分析を提供する。
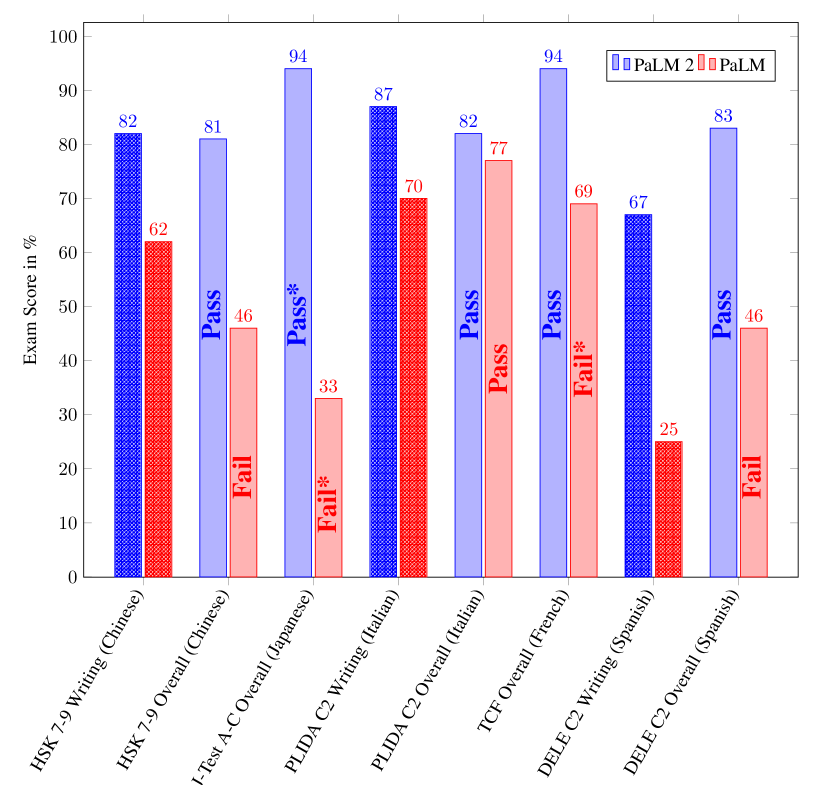
実験結果
リサーチクエスチョン
- RQ1固定計算量でデータサイズとモデルサイズをどのように拡大して PaLM 2 の性能を最適化するか?
- RQ2より多言語的な前訓練ミックスは、多言語と英語の性能を向上させつつ英語能力を損なわないか?
- RQ3PaLM 2 の推論、コーディング、翻訳、生成の能力は言語横断でどのようで、PaLM や GPT-4 のような以前のモデルとどう比較されるか?
- RQ4実世界のタスクにおける推論時毒性制御やその他の責任あるAI対策の有効性はどの程度か?
- RQ5PaLM 2 の前訓練データの記憶化、偏り、およびデータセットのスペクトラムの影響は何か?
主な発見
- PaLM 2 は、モデルサイズにかかわらず言語、推論、翻訳、コーディングのタスクで PaLM を上回る。
- スケーリング法則は、固定計算量の下で最適な性能を得るには学習データとモデルサイズをほぼ同等の割合で拡大すべきであることを示している。
- より大きな PaLM 2 バリアントは、多言語 TyDi QA および zero-shot/no-context 設定で強力な結果を達成し、特に低リソース言語で顕著である。
- 推論時制御トークンは他の機能への影響を最小限に抑えつつ毒性を調整できる。
- PaLM 2 は専門的な言語試験および BIG-Bench Hard タスクで堅牢な性能を示し、多言語および推論ベンチマークで顕著な向上を示す。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。