[論文レビュー] PanoGen: Text-Conditioned Panoramic Environment Generation for Vision-and-Language Navigation
PanoGen は BLIP-2 キャプションと拡散ベースのアウトペインティングを介して無限のテキスト条件付きパノラミックな室内環境を生成し、それらを使用して VLN エージェントを事前学習およびファインチューニングし、R2R、R4R、CVDN で SOTA を達成します。
Vision-and-Language Navigation (VLN) requires the agent to follow language instructions to navigate through 3D environments. One main challenge in VLN is the limited availability of photorealistic training environments, which makes it hard to generalize to new and unseen environments. To address this problem, we propose PanoGen, a generation method that can potentially create an infinite number of diverse panoramic environments conditioned on text. Specifically, we collect room descriptions by captioning the room images in existing Matterport3D environments, and leverage a state-of-the-art text-to-image diffusion model to generate the new panoramic environments. We use recursive outpainting over the generated images to create consistent 360-degree panorama views. Our new panoramic environments share similar semantic information with the original environments by conditioning on text descriptions, which ensures the co-occurrence of objects in the panorama follows human intuition, and creates enough diversity in room appearance and layout with image outpainting. Lastly, we explore two ways of utilizing PanoGen in VLN pre-training and fine-tuning. We generate instructions for paths in our PanoGen environments with a speaker built on a pre-trained vision-and-language model for VLN pre-training, and augment the visual observation with our panoramic environments during agents' fine-tuning to avoid overfitting to seen environments. Empirically, learning with our PanoGen environments achieves the new state-of-the-art on the Room-to-Room, Room-for-Room, and CVDN datasets. Pre-training with our PanoGen speaker data is especially effective for CVDN, which has under-specified instructions and needs commonsense knowledge. Lastly, we show that the agent can benefit from training with more generated panoramic environments, suggesting promising results for scaling up the PanoGen environments.
研究の動機と目的
- Vision-and-Language Navigation (VLN) のための制限された非スケーラブルな3Dトレーニング環境に対処する。
- 人手の注釈なしに、テキスト記述に条件付けされた多様で整合性のあるパノラマ環境を生成する。
- 生成されたパノラマをVLNの事前学習とファインチューニングに活用して、未見の環境への一般化を向上させる。
- テキスト条件付きの再帰的アウトペインティングによってパノラマの意味的整合性を維持する。
提案手法
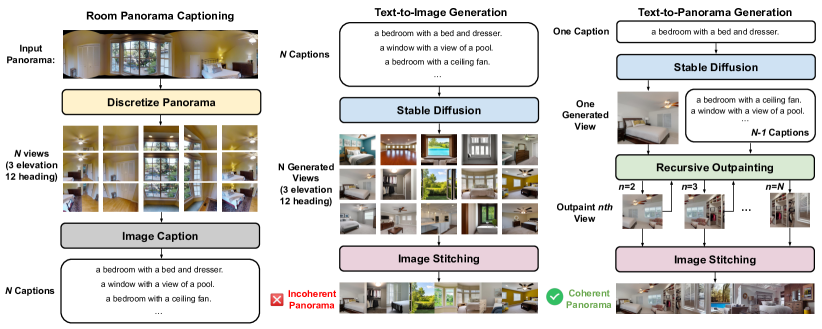
- Matterport3D のパノラマをBLIP-2でキャプション付けして部屋の記述を収集する。
- キャプションに条件付けられた36ビューの離散化された部屋の画像を拡散モデルを用いて生成する。
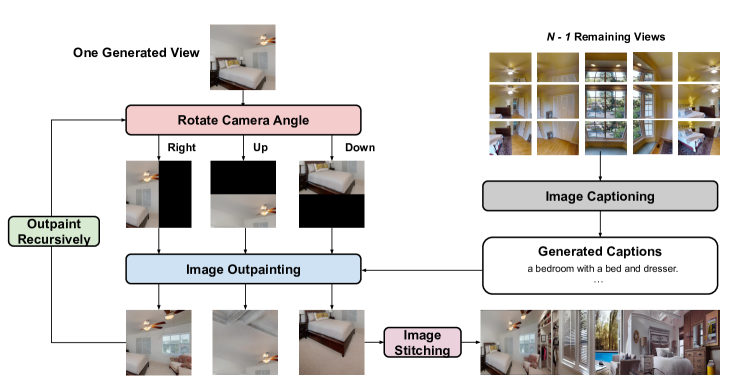
- 初期ビューからの再帰的アウトペインティングとカメラ角度の回転を通じて一貫した360度パノラマを作成する。
- VLN事前学習のために、PanoGenパノラマ内の経路の指示を生成するため、mPLUGをベースにしたスピーカーを訓練する。
- PanoGenと元データからの指示-軌跡ペアでVLNエージェントを事前トレーニングする。
- 過剰適合を減らすために観測の一部を生成されたパノラマに置き換えることでVLNエージェントをファインチューニングする。
実験結果
リサーチクエスチョン
- RQ1人間の常識知識と意味的整合性を保ちながら、スケールに応じてテキスト条件付きのパノラマ環境を生成することは可能か?
- RQ2生成されたパノラマはVLNの事前学習とファインチューニングを改善し、未見の環境への一般化を向上させるか?
- RQ3ファインチューニング時の生成パノラマの組み込み(観測の置換)が、R2R、R4R、CVDN のVLNパフォーマンスにどう影響するか?
- RQ4VLNの一般化に対する生成パノラマの数の影響は何か?
主な発見
- PanoGen は Room-to-Room (R2R) および CVDN テストセットで新しいSOTAを達成。
- PanoGenスピーカーデータを用いた事前学習は顕著な向上をもたらし、特に指示が不明確なCVDNで顕著である。
- パノラマ観測置換を用いたファインチューニングは、R2R、R4R、およびCVDNデータセット全体の性能を向上させる。
- ファインチューニング時に生成パノラマの量を増やすと継続的な向上が得られ、スケーラブルなメリットを示唆する。
- PanoGen は訓練データを効果的に置換または補強し、指示と観察の整合性を損なうことなく実行できる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。