[論文レビュー] ParaTransCNN: Parallelized TransCNN Encoder for Medical Image Segmentation
この論文は ParaTransCNN を提案します。CNN と Transformer をパイプライン化した並列エンコーダを、pyramid structure と channel attention を用いて局所特徴と全体特徴を統合し、医療画像分割を実現します。特に複数データセットにおいて小さな臓器で優れた結果を達成します。
The convolutional neural network-based methods have become more and more popular for medical image segmentation due to their outstanding performance. However, they struggle with capturing long-range dependencies, which are essential for accurately modeling global contextual correlations. Thanks to the ability to model long-range dependencies by expanding the receptive field, the transformer-based methods have gained prominence. Inspired by this, we propose an advanced 2D feature extraction method by combining the convolutional neural network and Transformer architectures. More specifically, we introduce a parallelized encoder structure, where one branch uses ResNet to extract local information from images, while the other branch uses Transformer to extract global information. Furthermore, we integrate pyramid structures into the Transformer to extract global information at varying resolutions, especially in intensive prediction tasks. To efficiently utilize the different information in the parallelized encoder at the decoder stage, we use a channel attention module to merge the features of the encoder and propagate them through skip connections and bottlenecks. Intensive numerical experiments are performed on both aortic vessel tree, cardiac, and multi-organ datasets. By comparing with state-of-the-art medical image segmentation methods, our method is shown with better segmentation accuracy, especially on small organs. The code is publicly available on https://github.com/HongkunSun/ParaTransCNN.
研究の動機と目的
- 局所的な文脈と全体的な文脈の両方を捉えることで医療画像分割の改善を動機付けること。
- CNN と Transformer の表現を複数スケールで融合する並列エンコーダを開発すること。
- pyramid-structured Transformer と channel attention モジュールを組み込み、効果的な特徴融合を図ること。
- AVT、ACDC、Synapse などの多部位データセットで、最先端手法と比較してアプローチを評価すること。
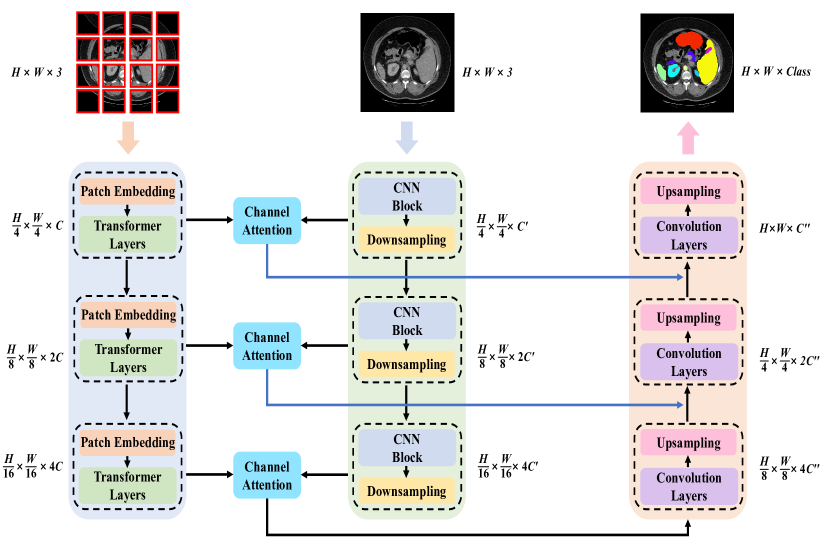
提案手法
- 局所特徴のための CNN(ResNet)と全体特徴のための Transformer(ViT)という二系統のエンコーダ。
- 複数解像度でグローバル情報を学習する Pyramid Transformer(下採点ファクター 4、8、16 のステージ)を採用。
- CNN と Transformer の特徴を整合させるための stage ごとのパッチサイズによるパッチ埋め込み。
- 各ステージで CNN と Transformer の特徴を統合する Channel attention モジュールをデコーダへ渡す前に適用。
- Skip 連結と畳み込みデコーダを持つ U-Net ライクな encoder–decoder アーキテクチャ。
- Dice と Cross-Entropy の結合損失(重みは等しく 0.5)を用いる。
![Figure 1: Conceptual comparison of the three most popular models used for medical image segmentation, where (a) classical U-Net [ 39 ] ; (b) Swin U-Net [ 8 ] ; (c) TransUNet [ 10 ] ; (d) Our parallelized TransCNN encoder.](https://ar5iv.labs.arxiv.org/html/2401.15307/assets/x1.png)
実験結果
リサーチクエスチョン
- RQ1並列の CNN+Transformer エンコーダと pyramid global features は、単一ブランチモデルより分割精度を改善するか。
- RQ2チャンネルアテンションは、マルチスケールの局所・全体特徴を効果的に融合して小さな臓器を含む正確な分割を達成できるか。
- RQ3パッチ埋め込み戦略と Transformer の深さが分割性能に与える影響はどの程度か。
- RQ4ParaTransCNN は AVT、ACDC、Synapse のようなマルチセンター医用画像データセットで、最先端手法と比べてどの程度優れているか。
主な発見
- ParaTransCNN は AVT、ACDC、Synapse データセット全体で最先端または競合的な結果を達成します。
- AVT では ParaTransCNN が DSC = 87.82% および 95% HD = 4.70 を達成し、DSC および HD の二つの指標で第2位の手法を上回ります。
- ACDC では ParaTransCNN が DSC = 91.31% および HD = 1.16 を達成し、複数のベースラインを両指標で上回ります。
- Synapse では ParaTransCNN が DSC = 83.86% および HD = 15.86 を達成し、膵臓と胃のセグメントで顕著な改善を示します。
- アブレーション研究は、 pyramid Transformer と channel attention が最良の性能のために重要である一方、パッチ重複や第4段階のより深い下採点は有益ではないことを示します。
- 定性的な結果は、ベースラインと比較してより連続的な血管構造と小さな臓器(膵臓と脾臓)のセグメンテーションが改善されることを示します。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。