[論文レビュー] Paxion: Patching Action Knowledge in Video-Language Foundation Models
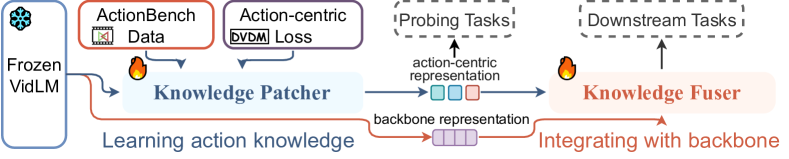
Paxion は Knowledge Patcher と Knowledge Fuser を用いて action knowledge を凍結した video-language モデルへパッチし、Discriminative Video Dynamics Modeling の新規目的で action 理解を改善しつつ object レベルの能力を保持します。
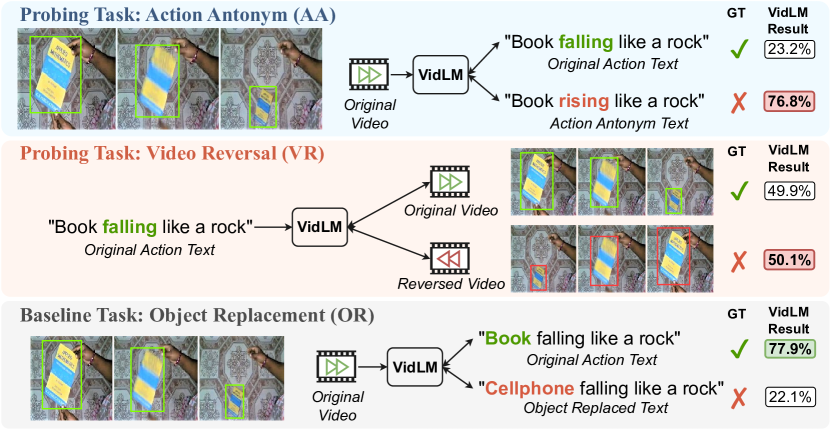
Action knowledge involves the understanding of textual, visual, and temporal aspects of actions. We introduce the Action Dynamics Benchmark (ActionBench) containing two carefully designed probing tasks: Action Antonym and Video Reversal, which targets multimodal alignment capabilities and temporal understanding skills of the model, respectively. Despite recent video-language models' (VidLM) impressive performance on various benchmark tasks, our diagnostic tasks reveal their surprising deficiency (near-random performance) in action knowledge, suggesting that current models rely on object recognition abilities as a shortcut for action understanding. To remedy this, we propose a novel framework, Paxion, along with a new Discriminative Video Dynamics Modeling (DVDM) objective. The Paxion framework utilizes a Knowledge Patcher network to encode new action knowledge and a Knowledge Fuser component to integrate the Patcher into frozen VidLMs without compromising their existing capabilities. Due to limitations of the widely-used Video-Text Contrastive (VTC) loss for learning action knowledge, we introduce the DVDM objective to train the Knowledge Patcher. DVDM forces the model to encode the correlation between the action text and the correct ordering of video frames. Our extensive analyses show that Paxion and DVDM together effectively fill the gap in action knowledge understanding (~50% to 80%), while maintaining or improving performance on a wide spectrum of both object- and action-centric downstream tasks. The code and data will be made publicly available for research purposes at https://github.com/MikeWangWZHL/Paxion.git.
研究の動機と目的
- ActionBench を定義して、マルチモーダルおよび時間的次元にわたる action knowledge を評価する。
- 最先端 VidLM の action 理解が object bias によって欠陥を抱えるか診断する。
- VL パフォーマンスを損なうことなく frozen VidLM バックボーンへ action knowledge をパッチする Paxion フレームワークを提案する。
- Discriminative Video Dynamics Modeling (DVDM) 損失を導入して action-text とフレーム動態をより良く学習する。
- action-centric な下流タスクでの性能向上を示しつつ object-centric な能力を保持する。
提案手法
- Perceiver ベースの Knowledge Patcher (KP) を導入し、凍結された VidLM バックボーン の軽量な action-centric feature 増強を実現する。
- Video-Action Contrastive (VAC) および Action-Temporal Matching (ATM) 損失を用いた Discriminative Video Dynamics Modeling (DVDM) を開発し、action dynamics を学習する。
- VTC のみでは action knowledge に対する十分性がないことを示し、DVDM が必要な識別信号を提供する。
- KP を Knowledge Fuser (KF) と統合し、クロスアテンションを用いて action-centric 表現と object-centric 表現を下流タスクへ統合する。
- ActionBench および Video-Text Retrieval、Video-to-Action Retrieval、NExT-QA などの下流タスクを zero-shot ドメイン転移の観点で Paxion を評価する。
実験結果
リサーチクエスチョン
- RQ1最先端の VidLM が object 認識を超えた robust な action knowledge を示せるか。
- RQ2patch ベースの frozen バックボーンアプローチと discriminative dynamics 目的が action 理解を改善し、VL パフォーマンスを犠牲にしないか。
- RQ3 action-centric patch をバックボーン表現と統合することが、object-, action-, temporel に焦点を当てた幅広い下流タスクへどのような影響を与えるか。
主な発見
| バックボーン | 手法 [パッチャー訓練損失] | 学習可能パラメータ数 | AA | VR | 平均 | |
|---|---|---|---|---|---|---|
| InternVideo | バックボーン | - | 58.8 | 46.2 | 51.3 | |
| InternVideo | KP-Transformer [VTC] | 8.4M (1.8%) | 68.2 | 62.8 | 64.3 | |
| InternVideo | KP-Perceiver [VTC] | 4.2M (0.9%) | 66.5 | 63.6 | 67.7 | |
| InternVideo | KP-Perceiver [VTC+ DVDM] | 4.2M (0.9%) | 90.1 | 75.5 | 85.9 | |
| Clip-ViP | バックボーン | - | 49.3 | 55.0 | 57.0 | |
| Clip-ViP | KP-Transformer [VTC] | 3.9M (2.6%) | 61.9 | 53.4 | 60.5 | |
| Clip-ViP | KP-Perceiver [VTC] | 2.4M (1.6%) | 61.9 | 54.6 | 59.2 | |
| Clip-ViP | KP-Perceiver [VTC+ DVDM] | 2.4M (1.6%) | 89.3 | 56.9 | 75.4 | |
| Singularity | バックボーン | - | 47.0 | 50.1 | 48.9 | |
| Singularity | KP-Transformer [VTC] | 3.9M (1.8%) | 61.9 | 48.2 | 55.9 | |
| Singularity | KP-Perceiver [VTC] | 1.3M (0.6%) | 60.3 | 46.1 | 55.3 | |
| Singularity | KP-Perceiver [VTC+ DVDM] | 1.3M (0.6%) | 83.8 | 58.9 | 73.5 | |
| Human | - | - | - | 92.0 | 78.0 | 89.0 |
- ActionBench は Action Antonym および Video Reversal で leading VidLMs がほぼランダムに近い性能を示し、action knowledge が弱く object に偏っていることを示唆する。
- Paxion + DVDM は action 理解(AA と VR)を大幅に改善し、オブジェクトベースのタスク性能を維持または向上させる。
- KP と VTC+DVDM の組み合わせは AA/VR スコアを劇的に向上させ(例:InternVideo 系で 58.8/46.2 から 90.1/75.5 へ)、総合的な Avg 増分を大きく生む。
- Knowledge Fuser (KF) は downstream タスクの性能を向上させ、特に Temporal-SSv2 や NExT-QA のような時間的集約タスクの改善を促進する。
- KF を使用した場合、ドメインシフトへの頑健性とゼロショット設定での正の転移を示し、一般化能の向上を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。