[論文レビュー] Perception Test: A Diagnostic Benchmark for Multimodal Video Models
この論文は Perception Test を紹介します。現実世界のマルチモーダル動画ベンチマークで、映像、音声、テキストに跨る memory、抽象化、物理、意味論を、記述的・説明的・予測的・反事実的推論に加え、 dense な注釈と公開のテストサーバを特徴とします。
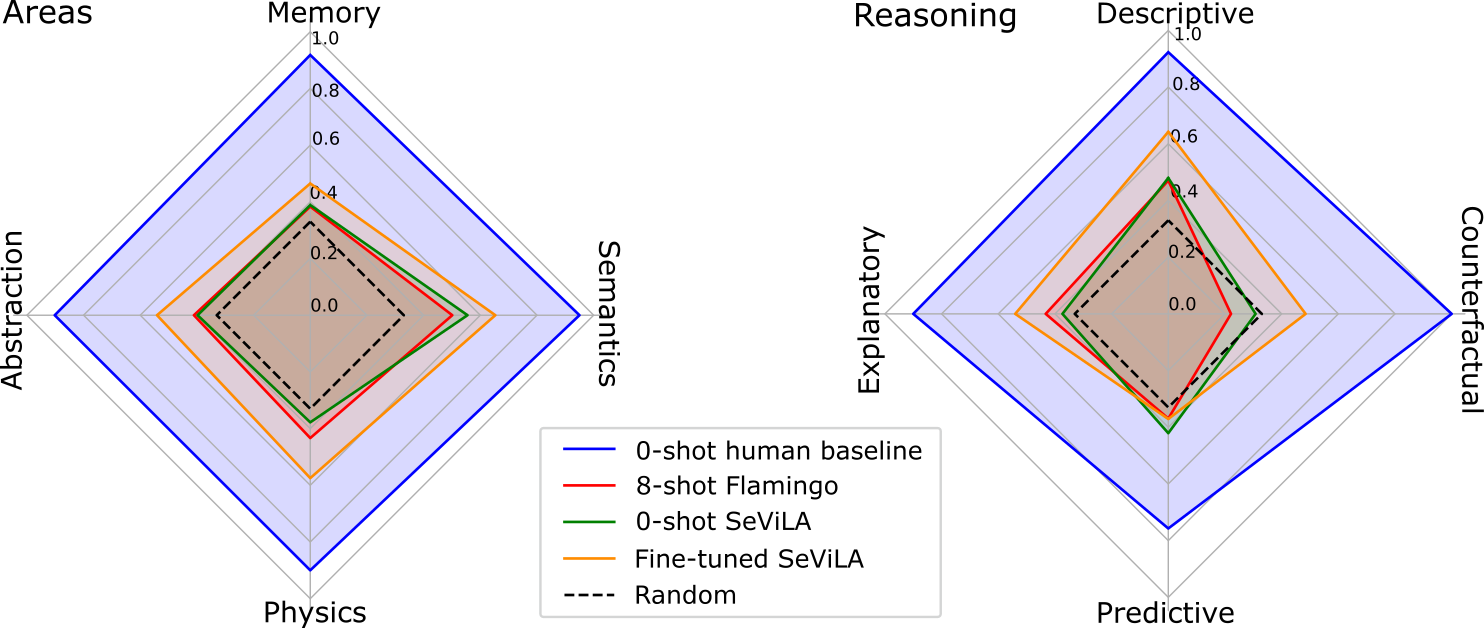
We propose a novel multimodal video benchmark - the Perception Test - to evaluate the perception and reasoning skills of pre-trained multimodal models (e.g. Flamingo, SeViLA, or GPT-4). Compared to existing benchmarks that focus on computational tasks (e.g. classification, detection or tracking), the Perception Test focuses on skills (Memory, Abstraction, Physics, Semantics) and types of reasoning (descriptive, explanatory, predictive, counterfactual) across video, audio, and text modalities, to provide a comprehensive and efficient evaluation tool. The benchmark probes pre-trained models for their transfer capabilities, in a zero-shot / few-shot or limited finetuning regime. For these purposes, the Perception Test introduces 11.6k real-world videos, 23s average length, designed to show perceptually interesting situations, filmed by around 100 participants worldwide. The videos are densely annotated with six types of labels (multiple-choice and grounded video question-answers, object and point tracks, temporal action and sound segments), enabling both language and non-language evaluations. The fine-tuning and validation splits of the benchmark are publicly available (CC-BY license), in addition to a challenge server with a held-out test split. Human baseline results compared to state-of-the-art video QA models show a substantial gap in performance (91.4% vs 46.2%), suggesting that there is significant room for improvement in multimodal video understanding. Dataset, baseline code, and challenge server are available at https://github.com/deepmind/perception_test
研究の動機と目的
- 事前学習済みマルチモーダルモデルの diverse perception skills に対する転移性能を評価する(ゼロショット、少数ショット、または制限付きファインチューニング)
- 記憶・抽象化・物理・意味論を探る密度の高い注釈付き現実世界動画データセットを提供する
- robust な一般化評価を可能とする公開のトレーニング/検証分割とheld-outテストサーバを提供する
- 複数の注釈タイプ(トラッキング、セグメント、Q&A)を用いたモデルの偏りとタスク間相関の分析を可能にする
提案手法
- 異なるスキルを probe し言語バイアスを避けるため、37 本の scripted な現実世界動画を設計する
- 動画に6種類のラベルを注釈付けする:物体トラック、ポイントトラック、時系列アクションセグメント、時系列サウンドセグメント、mc-vQA、 grounded vQA
- 6つの計算タスク(トラッキング、定位、動画QA)を定義し、タスク固有の評価指標を設定する
- 一般化を評価するためのゼロショットまたは少数ショット設定を用いた per-task ベースラインを提供する
- 再現性のある評価を促進するオープンソース動画・注釈・チャレンジサーバを提供する
- 人間の性能を文脈化するため mc-vQA に対する人間ベースラインを含める

実験結果
リサーチクエスチョン
- RQ1事前学習済みのマルチモーダル動画モデルは、ゼロショット・少数ショット・限定ファインチューニングのいずれの体制でも記憶・抽象化・物理・意味論タスクへ一般化できるか?
- RQ2マルチモーダルモデルは、記述的・説明的・予測的・反事実的という異なる種類の推論と、映像・音声・テキストというモダリティ間でどう性能を示すか?
- RQ3包括的な現実世界の診断ベンチマークにおける人間の性能と最先端モデルのギャップはどこにあるか?
- RQ4複合注釈(追跡・セグメント・QA)による組み合わせが、モデルの偏りと失敗モードについてどのような洞察を提供するか?
主な発見
| タスク | 出力 | 指標 | ベースライン | スコア |
|---|---|---|---|---|
| 物体追跡 | box track | Avg. IoU | SiamFC [8] | 0.67 |
| 点追跡 | point track | Avg. Jaccard | TAP-Net [19] | 0.401 |
| 時系列アクションロ localisation | list of action segments | mAP | ActionFormer [57] | 15.56 |
| 時系列サウンドロ localisation | list of sound segments | mAP | ActionFormer [57] | 15.46 |
| 複数選択動画QA | answer (1 out of 3) | top-1 accuracy | SeViLA [55] | 46.2 |
| Grounded videoQA | list of box tracks | HOTA | MDETR [34] + Stark [52] | 0.1 |
- 11.6k 本の現実世界動画(平均 23s)と dense な多種注釈により、マルチモーダル評価を徹底的に実行可能。
- 人間は mc-vQA で 91.4% を達成する一方、最先端モデルはゼロショット/少数ショット設定で 46.2% にとどまり、改善余地が大きいことを示す。
- Perception Test は、 memory・物理・抽象化領域でモデルの弱点を明らかにし、いくつかのタスクで単純なベースラインを下回ることがある。
- ベースラインの結果はタスク固有の最高値を示す:物体追跡 IoU 0.67、点追跡 Jaccard 0.401、アクションローカリゼーション mAP 15.56、サウンドローカリゼーション mAP 15.46、mc-vQA 正確度 46.2、 grounded vQA IoU 0.1。
- データセットは一般化重視の評価をサポートしており、train/validation 分割と held-out テストサーバを備え、タスク間の転移能力を検証できる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。