[論文レビュー] Personalized Prediction of Recurrent Stress Events Using Self-Supervised Learning on Multimodal Time-Series Data
この論文は、個人の多感覚生体信号を用いた自律学習に基づく個別化フレームワークを提案し、注釈を最小限に抑えてストレスを予測するために事前学習を行い、WESADデータセットで評価します。
Chronic stress can significantly affect physical and mental health. The advent of wearable technology allows for the tracking of physiological signals, potentially leading to innovative stress prediction and intervention methods. However, challenges such as label scarcity and data heterogeneity render stress prediction difficult in practice. To counter these issues, we have developed a multimodal personalized stress prediction system using wearable biosignal data. We employ self-supervised learning (SSL) to pre-train the models on each subject's data, allowing the models to learn the baseline dynamics of the participant's biosignals prior to fine-tuning the stress prediction task. We test our model on the Wearable Stress and Affect Detection (WESAD) dataset, demonstrating that our SSL models outperform non-SSL models while utilizing less than 5% of the annotations. These results suggest that our approach can personalize stress prediction to each user with minimal annotations. This paradigm has the potential to enable personalized prediction of a variety of recurring health events using complex multimodal data streams.
研究の動機と目的
- Multimodal biosignals からのストレス予測におけるラベル不足とデータヘテロogeneityの課題に対処する。
- 個々の基準動的変化を捉えるため、ユーザーごとに学習する個別化モデルを開発する。
- 未ラベルデータから堅牢な表現を学ぶための自己教師付き事前学習を活用する。
- 改善されたストレス予測のため、六つの生体信号(EDA, ECG, EMG, TEMP, RESP, ACC)を統合する。
- 注釈要件を減らしつつ、性能を維持または向上させることを示す。
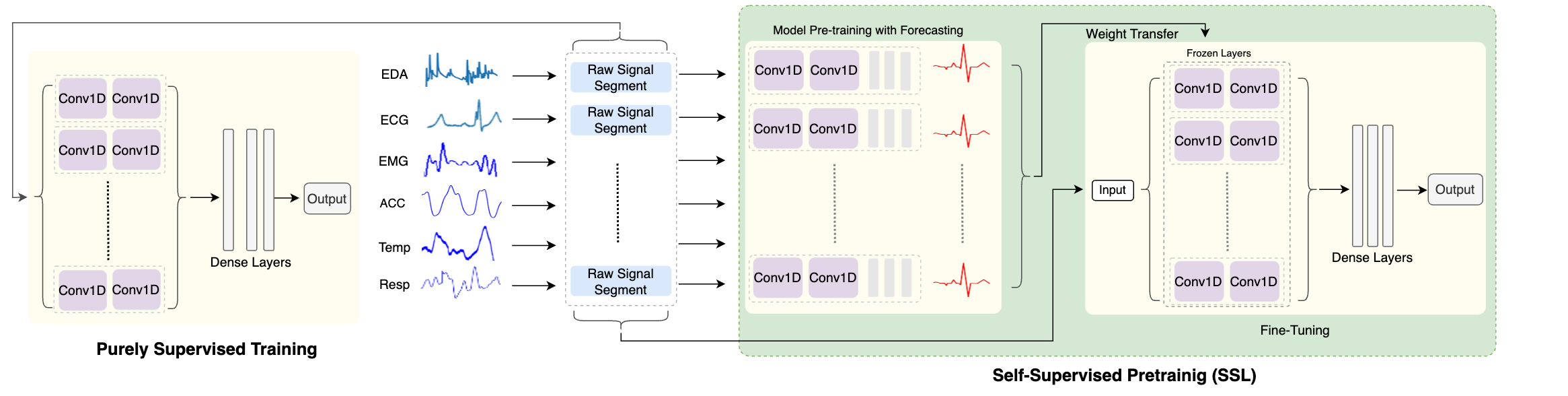
提案手法
- 生データの多感覚生体信号を、モデル入力として重複ウィンドウにセグメントする。
- ラベルなしデータから基準表現を学習する、 subject-specific な自己教師付き事前学習タスクを使用する。
- 下流のストレス予測タスクで、事前学習済みモデルをラベル付きデータでファインチューニングする。
- 六つのモダリティを late-stage fusion で統合し、ストレス予測の多感覚表現を生成する。
- 事前学習層を凍結したまま、タスク固有の密結合層を用いた二段階アーキテクチャを訓練する。
- RMSEで評価し、SSL事前学習と純粋な教師あり訓練を比較する。
実験結果
リサーチクエスチョン
- RQ1限られた注釈で、個人ごとの自己教師付き事前学習は非SSLアプローチよりストレス予測を改善できるか?
- RQ2マルチモーダルの個別化は、単一モダリティや非個別化モデルと比較して性能にどう影響するか?
- RQ3SSLは正確なストレス予測を達成するために必要なラベル付きデータ数を減らすか?
主な発見
- SSL事前学習は、すべての被験者と注釈タイプにおいて、純粋に教師付きモデルより有意に低いRMSEを示す。
- SSLモデルは、5件程度のランダムに抽出したデータポイントでも非SSLモデルを上回る。
- 個別化かつ多感覚のSSLは、注釈負担を減らしつつ予測精度を維持する。
- 六つの生体信号から得られる統合表現はストレス予測性能を向上させる。
- 本手法は、被験者ごとのベースラインを用いた制御されたデータセット(WESAD)で堅牢な改善を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。