[論文レビュー] PharmacyGPT: The AI Pharmacist
PharmacyGPTは薬局業務のためにChatGPTとGPT-4を調査し、動的 prompting と反復最適化を用いてICUデータから患者クラスタ、死亡率と APACHE II の予測、および薬物療法計画を生成します。結果として、動的文脈を取り入れたGPT-4が検討されたアプローチの中で最も良い性能を示しましたが、顕著な限界もあります。
In this study, we introduce PharmacyGPT, a novel framework to assess the capabilities of large language models (LLMs) such as ChatGPT and GPT-4 in emulating the role of clinical pharmacists. Our methodology encompasses the utilization of LLMs to generate comprehensible patient clusters, formulate medication plans, and forecast patient outcomes. We conduct our investigation using real data acquired from the intensive care unit (ICU) at the University of North Carolina Chapel Hill (UNC) Hospital. Our analysis offers valuable insights into the potential applications and limitations of LLMs in the field of clinical pharmacy, with implications for both patient care and the development of future AI-driven healthcare solutions. By evaluating the performance of PharmacyGPT, we aim to contribute to the ongoing discourse surrounding the integration of artificial intelligence in healthcare settings, ultimately promoting the responsible and efficacious use of such technologies.
研究の動機と目的
- LLM(ChatGPTとGPT-4)を薬学関連タスクで活用する能力を探る。
- ファインチューニングなしでLLMを臨床薬学へ適応させるための動的 promptingと反復最適化を開発する。
- LLMの埋め込みとクラスタリングを用いて解釈可能な患者クラスタを生成する。
- ICUデータにおける患者転帰予測と薬剤計画生成のLLM評価を行う。
提案手法
- 患者データから1536次元のGPT-3埋め込みを生成し、階層的クラスタリングを適用して解釈可能な患者クラスタを作成する。
- モデル出力の評価スコアに基づいてプロンプトを更新する反復最適化アルゴリズムを採用する。
- GPT-4/ChatGPTの性能を向上させるために動的コンテキストアプローチを用いてプロンプト構築を行う。
- さまざまな few-shot prompting 戦略(rand_5-shot、freq_5-shot、bcat_rand_5-shot、sim_5-shot、および GPT-4派生版)を用いて死亡率と APACHE II スコア予測性能を評価する。
- GPT-4で生成された薬剤計画を専門家レビューと比較し、ROUGE様の指標を超えた実用性と評価要件を議論する。
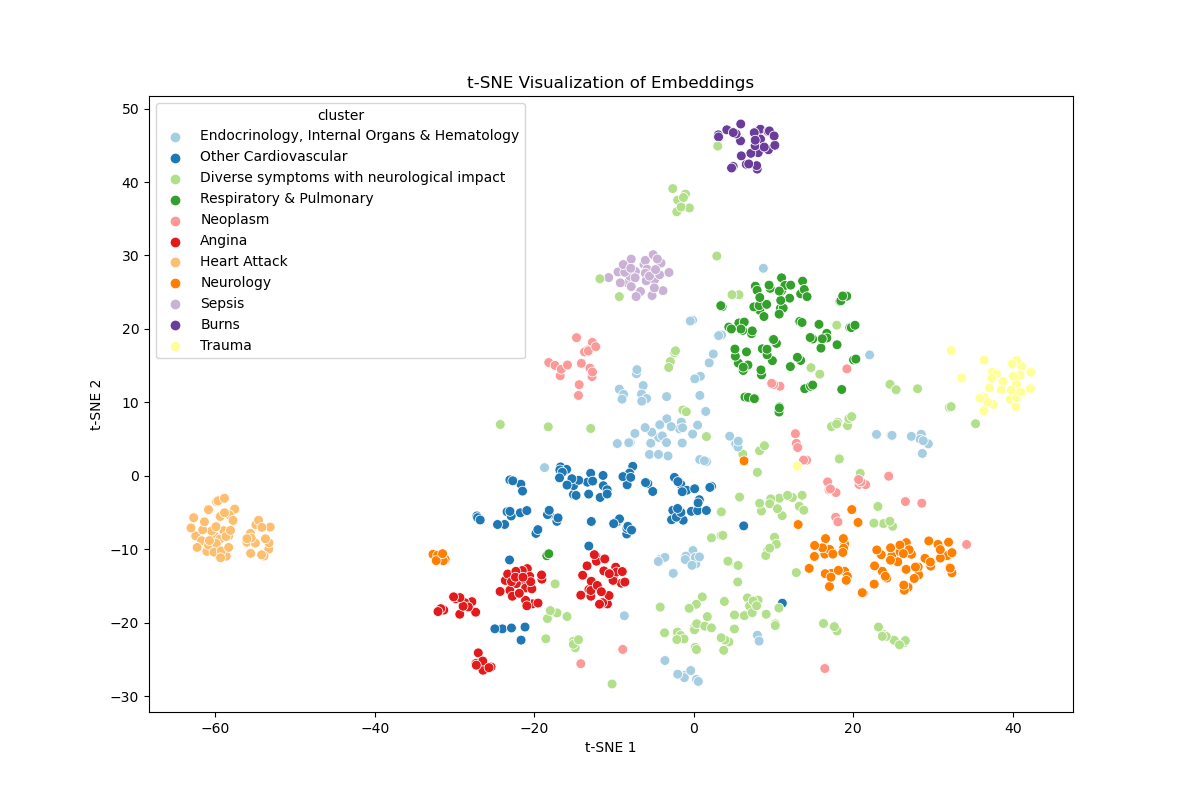
実験結果
リサーチクエスチョン
- RQ1LLMは埋め込みとクラスタリングを用いてICUデータから解釈可能な患者クラスタを生成できるか。
- RQ2動的プロンプトと few-shot デモンストレーションを用いて、ChatGPTとGPT-4は院内死亡率とAPACHE IIスコアをどれほど予測できるか。
- RQ3GPT-4/ChatGPTがICU薬剤計画を生成する際の可能性と限界は何か、どのように評価すべきか。
- RQ4反復的プロンプト最適化はモデルのファインチューニングなしでLLMの性能を向上させられるか。
主な発見
| Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| rand_5-shot | 0.7549 | 0.3750 | 0.7095 | 0.4898 |
| freq_5-shot | 0.6455 | 0.1667 | 0.6364 | 0.2642 |
| bcat_rand_5-shot | 0.6602 | 0.2051 | 0.7647 | 0.4262 |
| sim_5-shot | 0.6699 | 0.2821 | 0.6471 | 0.3929 |
- クラスタリングはICD-10カテゴリと整合するグループを示し、専門家による解釈性が確認された。
- 動的コンテキストと類似サンプルを用いたGPT-4は、アウトカム予測において検討モデルの中で最高の精度を達成した。
- 死亡率予測の精度とF1は、データの不均衡(生存9:死9:1)と死亡例の小さいサンプル数(テストセット46例)によって影響を受けた。
- APACHE IIスコア予測ではGPT-4ベースのプロンプトが他の手法を上回り、初日データの強い関連性を示した。
- GPT-4が生成した薬剤計画は専門の薬剤師レビューを必要とし、ROUGEに類似した指標を超えた新しいタスク特異的評価指標が必要である。
- 患者の不均衡と時間的変化により、静的な初日データからの死亡予測可能性と評価が制限される。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。