[論文レビュー] pixelNeRF: Neural Radiance Fields from One or Few Images
pixelNeRF は、ピクセル整列画像特徴を条件付け、複数のビューを集約することで、テスト時の最適化を行わずに、1 枚または数枚の入力画像から新規ビューを合成できる、フィードフォワードの画像条件付き NeRF を学習します。
We propose pixelNeRF, a learning framework that predicts a continuous neural scene representation conditioned on one or few input images. The existing approach for constructing neural radiance fields involves optimizing the representation to every scene independently, requiring many calibrated views and significant compute time. We take a step towards resolving these shortcomings by introducing an architecture that conditions a NeRF on image inputs in a fully convolutional manner. This allows the network to be trained across multiple scenes to learn a scene prior, enabling it to perform novel view synthesis in a feed-forward manner from a sparse set of views (as few as one). Leveraging the volume rendering approach of NeRF, our model can be trained directly from images with no explicit 3D supervision. We conduct extensive experiments on ShapeNet benchmarks for single image novel view synthesis tasks with held-out objects as well as entire unseen categories. We further demonstrate the flexibility of pixelNeRF by demonstrating it on multi-object ShapeNet scenes and real scenes from the DTU dataset. In all cases, pixelNeRF outperforms current state-of-the-art baselines for novel view synthesis and single image 3D reconstruction. For the video and code, please visit the project website: https://alexyu.net/pixelnerf
研究の動機と目的
- 複数のシーンに跨るシーン事前知識を学習することによって、非常に少ない入力ビューから新規ビュー合成を動機付け、実現する。
- 各シーンごとの最適化を、未見の物体やカテゴリへ一般化するフィードフォワードモデルに置換する。
- ビュー空間でピクセル整列の画像特徴を条件付けて NeRF の空間的配置を保持する。
- テスト時に可変数の入力ビューを許容し、テスト時最適化を必要としない。
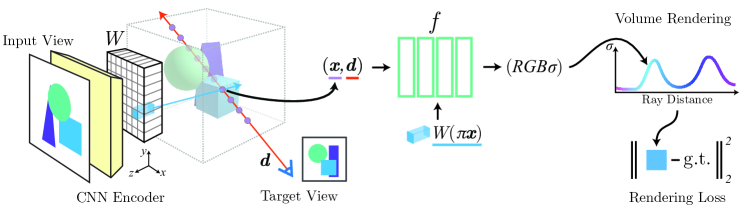
提案手法
- 入力画像から完全畳み込みの画像特徴グリッドを計算し、射影と双線形補間を用いてクエリ点ごとのピクセル特徴をサンプリングする。
- NeRF ネットワークを空間的画像特徴で条件付けるため、それらを NeRF MLP の各層へ残差として追加する。
- 複数の入力ビューの場合、各ビューを特徴体積にエンコードし、各ビューへ射影して初期の NeRF ブロックで個別に処理し、その後最終層前に平均化して密度と色を予測する。
- 未見のカテゴリや複数オブジェクトのシーンへの一般化を改善するため、 canonical scene space よりもカメラ/ビュー空間で動作する。
- レンダリング画像と実画像を比較するボリュームレンダリング損失でエンドツーエンドに訓練し、明示的な 3D 監督を必要としない。
- シングルビューからマルチビュー入力へ拡張し、ビューを横断して情報を集約することで少数ショット再構成を可能にする。
実験結果
リサーチクエスチョン
- RQ1多数のシーンを横断して訓練した場合、単一または少数の入力画像だけで、シーンの整合性のある NeRF 表現を予測できるか?
- RQ2ピクセル整列画像特徴で NeRF を条件付けることは、明示的な 3D 監督なしに未見のカテゴリや複数オブジェクトのシーンへ一般化を可能にするか?
- RQ3ビュー空間条件付けとマルチビュー集約は、ShapeNet および実世界データセットの新規ビュー合成品質にどう影響するか?
- RQ4このアプローチは、テスト時に入力ビューの数を変化させてもテスト時最適化なしで対応できるか?
主な発見
- PixelNeRF は few-shot novel-view 合成ベンチマークにおいて、SRN および DVR ベースラインと比較して最新鋭に近い性能を達成する。
- この方法は、合成データと限られたシーンで訓練されつつも、未見の物体カテゴリおよび実画像(DTU)へ一般化する。
- 局所的でピクセル整列した画像特徴を用い、視線方向を組み込むことで、グローバル潜在コードより再構成品質とディテールを向上させる。
- マルチビュー条件付けはマルチオブジェクトシーンで正確な 360 度再構成を可能にし、車の画像で sim-to-real 移行が実証されている。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。