[論文レビュー] Plan-Seq-Learn: Language Model Guided RL for Solving Long Horizon Robotics Tasks
PSL は、LLM ベースの高レベル計画と vision ベースのシーケンスおよび RL を統合し、 predefined skill library なしで長期的なロボットタスクをゼロから解決します。最大10段階まで、25以上のタスクに渡って高い成果を達成します。
Large Language Models (LLMs) have been shown to be capable of performing high-level planning for long-horizon robotics tasks, yet existing methods require access to a pre-defined skill library (e.g. picking, placing, pulling, pushing, navigating). However, LLM planning does not address how to design or learn those behaviors, which remains challenging particularly in long-horizon settings. Furthermore, for many tasks of interest, the robot needs to be able to adjust its behavior in a fine-grained manner, requiring the agent to be capable of modifying low-level control actions. Can we instead use the internet-scale knowledge from LLMs for high-level policies, guiding reinforcement learning (RL) policies to efficiently solve robotic control tasks online without requiring a pre-determined set of skills? In this paper, we propose Plan-Seq-Learn (PSL): a modular approach that uses motion planning to bridge the gap between abstract language and learned low-level control for solving long-horizon robotics tasks from scratch. We demonstrate that PSL achieves state-of-the-art results on over 25 challenging robotics tasks with up to 10 stages. PSL solves long-horizon tasks from raw visual input spanning four benchmarks at success rates of over 85%, out-performing language-based, classical, and end-to-end approaches. Video results and code at https://mihdalal.github.io/planseqlearn/
研究の動機と目的
- LLM計画を活用してRLを導くことで、固定スキルライブラリなしに長期的なロボットタスクの完遂を可能にする。
- 抽象的な言語計画と低レベル制御を、視覚ベースのシーケンスモジュールと動作計画を通じて橋渡しする。
- 段階間で共有ポリシーを用い、カリキュラム様の段階終了条件によって学習速度と安定性を向上させる。
- 視覚入力のみを用いて、複数のベンチマーク(25+タスク、最大10段階)で最先端の性能を示す。
提案手法
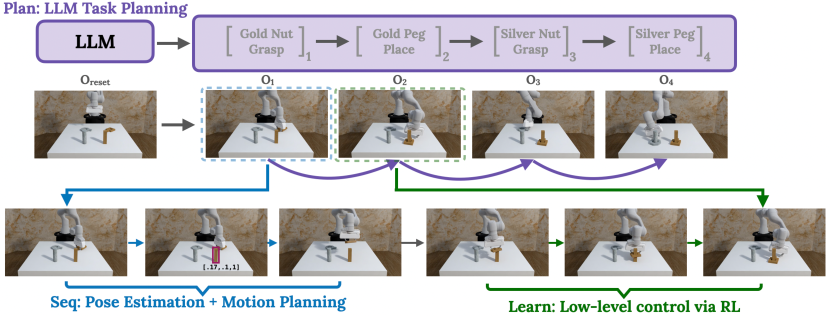
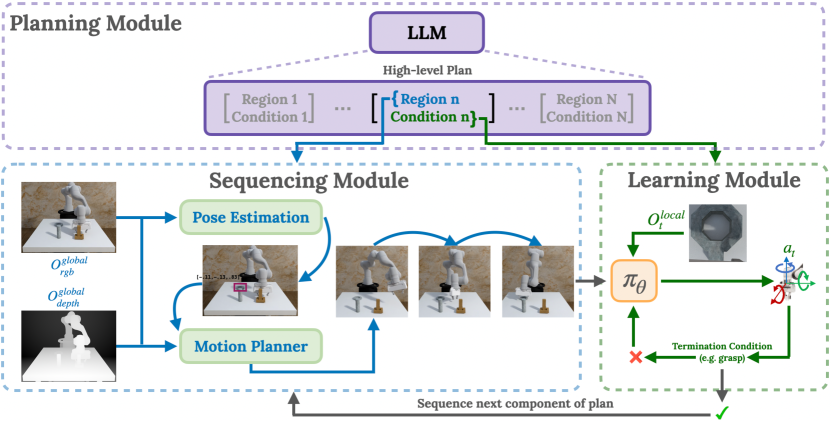
- タスクを言語生成によるリージョン-ステージペアに分解する(Plan) via LLM計画。
- RGB-D観測からターゲット領域を推定し、モーションプランニングでターゲット姿勢を計算する視覚ベースのシーケンスモジュールを使用(Seq)。
- 全段階にまたがる単一のRLポリシーを訓練して局所的な相互作用戦略を学習する(Learn)。
- 計画実行中の迷いを防ぎ、カリキュラムを導くために段階終了条件を適用する。
- DRQ-v2で訓練し、局所観測を活用してデータ効率と一般化を向上させる。
- 長期計画の誤差に対処するため、段階間でポリシーと価値関数を共有する。
実験結果
リサーチクエスチョン
- RQ1LLM は、事前に定義されたスキルライブラリなしで、長期的なロボットタスクに対して有用なゼロショットの高レベル計画を提供できるか?
- RQ2LLM計画を視覚ベースのシーケンスと単一のRLポリシーと結びつけることで、長期タスクにおける学習効率とタスク成功率が向上しますか?
- RQ3局所観測と段階終了の手がかりを使用することが、学習速度と姿勢ノイズに対する頑健性にどう影響しますか?
- RQ4この PSL フレームワークは、異なるベンチマークに跨る最大10段階のマルチステージタスクへスケールできますか?
主な発見
| タスク | E2E | RAPS | TAMP | SayCan | PSL |
|---|---|---|---|---|---|
| RS-Bread | 0.52 ± 0.49 | 0.32 ± 0.44 | 0.90 ± 0.01 | 0.93 ± 0.09 | 1.0 ± 0.0 |
| RS-Can | 0.32 ± 0.44 | 0.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.0 ± 0.0 |
| RS-Milk | 0.02 ± 0.04 | 0.00 ± 0.00 | 0.85 ± 0.06 | 0.90 ± 0.05 | 1.0 ± 0.0 |
| RS-Cereal | 0.00 ± 0.00 | 0.00 ± 0.00 | 1.00 ± 0.00 | 0.63 ± 0.09 | 1.0 ± 0.0 |
| RS-NutRound | 0.06 ± 0.13 | 0.00 ± 0.00 | 0.40 ± 0.30 | 0.56 ± 0.25 | 0.98 ± 0.04 |
| RS-NutSquare | 0.02 ± 0.045 | 0.00 ± 0.00 | 0.35 ± 0.20 | 0.27 ± 0.21 | 0.97 ± 0.02 |
- PSL は、視覚入力のみを用いて、最大10段階の4つのベンチマークで85%以上の成功を達成します。
- Robosuite の2段階タスクでは、PSL はベースラインが遅れるところで1.0の成功を達成し、PSL はほぼ1.0に近い平均を取り、他は大きく低い。
- PSL は複数段階タスクでエンドツーエンドおよび階層 RL のベースラインを大幅に上回り、他が低下する場面でも高い成功を維持します。
- このアプローチは、計画(モーションプランニング)と相互作用(RL)を分離することで、妨害を受けるタスクや接触が多いタスクを効果的に扱います。
- 段階終了の手がかりと段階間での共有ポリシーは、学習速度と姿勢推定ノイズに対する頑健性を大幅に改善します。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。