[論文レビュー] Planting a SEED of Vision in Large Language Model
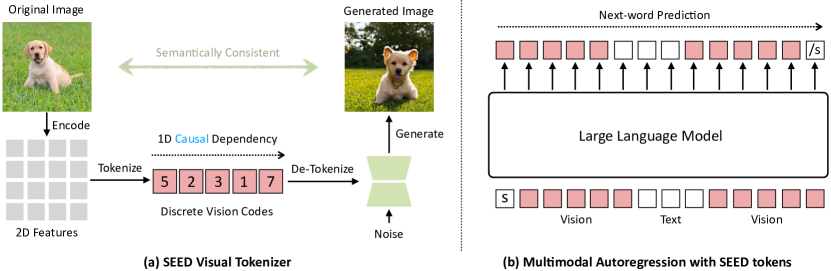
SEED は、離散的な画像トークナイザーを導入し、オフ・ザ・シェルLLMsが LoRA 微調整済みのマルチモーダルモデルを介して画像→テキストおよびテキスト→画像生成を行えるようにする。5M枚の画像-テキストペアと1D 因果トークン設計を使用。
We present SEED, an elaborate image tokenizer that empowers Large Language Models (LLMs) with the emergent ability to SEE and Draw at the same time. Research on image tokenizers has previously reached an impasse, as frameworks employing quantized visual tokens have lost prominence due to subpar performance and convergence in multimodal comprehension (compared to BLIP-2, etc.) or generation (compared to Stable Diffusion, etc.). Despite the limitations, we remain confident in its natural capacity to unify visual and textual representations, facilitating scalable multimodal training with LLM's original recipe. In this study, we identify two crucial principles for the architecture and training of SEED that effectively ease subsequent alignment with LLMs. (1) Image tokens should be independent of 2D physical patch positions and instead be produced with a 1D causal dependency, exhibiting intrinsic interdependence that aligns with the left-to-right autoregressive prediction mechanism in LLMs. (2) Image tokens should capture high-level semantics consistent with the degree of semantic abstraction in words, and be optimized for both discriminativeness and reconstruction during the tokenizer training phase. As a result, the off-the-shelf LLM is able to perform both image-to-text and text-to-image generation by incorporating our SEED through efficient LoRA tuning. Comprehensive multimodal pretraining and instruction tuning, which may yield improved results, are reserved for future investigation. This version of SEED was trained in 5.7 days using only 64 V100 GPUs and 5M publicly available image-text pairs. Our preliminary study emphasizes the great potential of discrete visual tokens in versatile multimodal LLMs and the importance of proper image tokenizers in broader research.
研究の動機と目的
- 自己回帰型LLMのために視覚的表現とテキスト表現を統一するトークナイザ設計を動機づける。
- 1D 因果依存性と高レベル意味トークンを持つVQベースの画像トークナイザを開発する。
- SEED を LoRA 経由で LLM と統合することで vision-to-language および language-to-vision のタスクを有効にすることを実証する。
- 既存のマルチモーダルベースラインと比較して、ゼロショットの検索と生成性能が競争力があることを示す。
- 限定的な計算資源と公開の画像-テキストデータを用いたスケーラブルな訓練手順を概説する。
提案手法
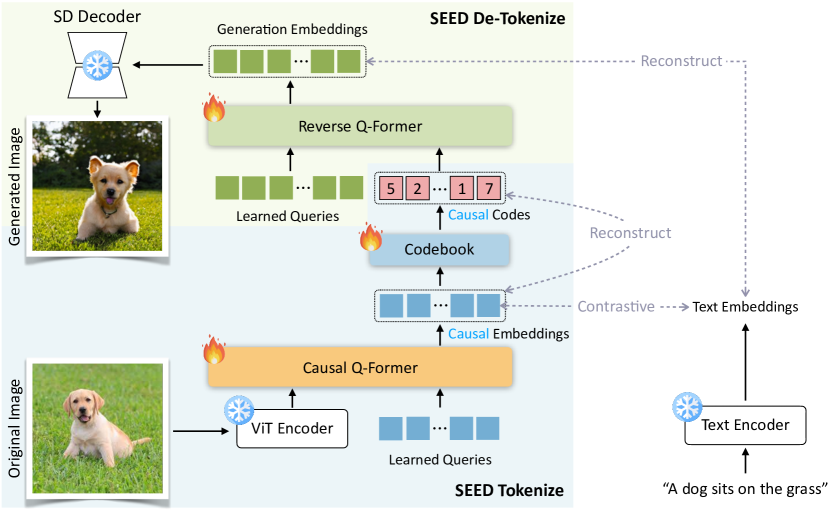
- SEED を ViT エンコーダ、因果性 Q-Former、VQ コードブック、Reverse Q-Former、UNet デコーダを備えた VQ ベースの画像トークナイザとして設計する。
- 1D 因果注意と画像-テキストコントラスト損失を用いて、16×16 の ViT 特徴から 32 の因果埋め込みを生成するように Causal Q-Former を訓練する。
- 因果埋め込みを VQ コードブックで量子化し、因果依存性を持つ 32 の離散ビジュアルコードを生成する。
- 離散コードを Stable Diffusion 潜在空間と整合する生成埋め込みにマッピングするために Reverse Q-Former を用い、画像合成を可能にする。
- 離散コードから連続埋め込みを再構築するデコーダを訓練し、生成埋め込みをテキスト特徴と二重再構成損失で整合させる。
- SEED-OPT 2.7B モデルを LoRA で微調整し、5M の画像-テキストペアで画像→テキストおよびテキスト→画像の自己回帰タスクを実行。
実験結果
リサーチクエスチョン
- RQ1離散化され意味的に豊富な画像トークナイザは LLM のテキストトークンと密接に整列し、統一されたマルチモーダル自己回帰を可能にするか?
- RQ21D 因果性の高レベル意味 image tokens は、LLM フレームワーク内で画像理解と画像生成の両方を促進するか?
- RQ3LoRA 経由で事前訓練済み LLM と統合した場合、SEED の検索と生成機能は確立されたマルチモーダル基準と比べてどうか?
- RQ4このようなトークナイザとマルチモーダルモデルを、意味的整合性を保ちながら控えめな計算資源とデータ規模で効率的に訓練することは可能か?
- RQ5SEED は LLM と組み合わせた場合、ゼロショットの画像キャプション生成と視覚的質問応答をどの程度サポートするか?
主な発見
- SEED トークンは BLIP-2 と比較可能なゼロショットの画像-テキスト検索能力を標準ベンチマークで発揮する。
- 離散的な SEED トークンは Stable Diffusion と比較して競争力のある画像生成性能を CLIP ベースの意味的整列とともに示す。
- LoRA を介して 5M の画像-テキストペアで訓練された SEED-OPT 2.7B は、画像→テキストおよびテキスト→画像の自己回帰を実証する。
- SEED は、離散トークンを Reverse Q-Former でデコードして SD-UNet 潜在空間に結び付けることにより、現実的な画像生成を可能にする。
- 定性的なデモンストレーションは、SEED が監視付き VQA の微調整なしでキャプションを生成し、オープンエンドの視覚的質問に答えられることを示す。
- このアプローチは、離散的な視覚トークンが LLM における新たなマルチモーダル能力を効果的に支える可能性を示唆している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。