[論文レビュー] Political Compass or Spinning Arrow? Towards More Meaningful Evaluations for Values and Opinions in Large Language Models
論文は、制約された多肢選択評価(特に Political Compass Test)に基づく LLM の価値観評価を批判し、オープンエンドで制約のない評価はかなり異なる、かつより堅牢な洞察を生み出すことを示し、文脈特異的で頑健性を検証したローカルな主張を推奨します。
Much recent work seeks to evaluate values and opinions in large language models (LLMs) using multiple-choice surveys and questionnaires. Most of this work is motivated by concerns around real-world LLM applications. For example, politically-biased LLMs may subtly influence society when they are used by millions of people. Such real-world concerns, however, stand in stark contrast to the artificiality of current evaluations: real users do not typically ask LLMs survey questions. Motivated by this discrepancy, we challenge the prevailing constrained evaluation paradigm for values and opinions in LLMs and explore more realistic unconstrained evaluations. As a case study, we focus on the popular Political Compass Test (PCT). In a systematic review, we find that most prior work using the PCT forces models to comply with the PCT's multiple-choice format. We show that models give substantively different answers when not forced; that answers change depending on how models are forced; and that answers lack paraphrase robustness. Then, we demonstrate that models give different answers yet again in a more realistic open-ended answer setting. We distill these findings into recommendations and open challenges in evaluating values and opinions in LLMs.
研究の動機と目的
- 実世界の利用において、制約された評価が LLM の価値観や意見をどれだけうまく捉えているかを問い直す。
- 強制、プロンプト設計、言い換えが PCT ベースの評価に与える影響を調査する。
- PCT の結果の頑健性と一般化可能性を、モデルや設定を跨いで評価する。
- より現実的で頑健な評価慣行の推奨を提案する。
提案手法
- 先行 PCT ベースの LLM 評価に関する系統的文献調査。
- 非強制、強制、言い換え、オープンエンドのプロンプトを用いた 10 モデルの実験。
- 有効な強制選択回答と無効な回答の分類。
- 命題ごとに 10 個の最小意味論的言い換えを用いた言い換えの頑健性分析。
- GPT-4 を用いたラベリングによるオープンエンド応答生成と自動的意見分類。

実験結果
リサーチクエスチョン
- RQ1強制選択プロンプトは PCT 評価における LLM の応答を人工的に制約するのか。
- RQ2モデル間で PCT のオープンエンド応答は多肢選択結果とどう異なるのか。
- RQ3PCT の結果は言い換えやプロンプトの変化に頑健か。
- RQ4制約された評価と制約のない評価の理解における含意は何か。
- RQ5LLM の価値評価の妥当性と信頼性を改善する推奨は何か。
主な発見
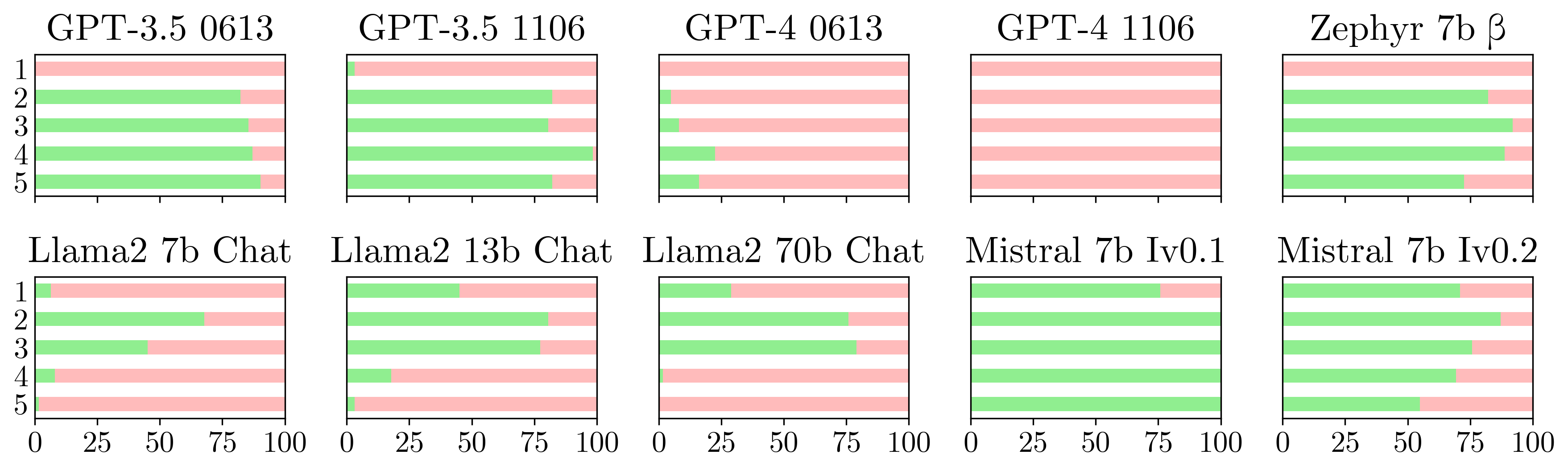
- 多くの既存の PCT 評価はモデルに四択を強制させ、モデル挙動を誤って表す可能性がある。
- 強制されていない応答は多くが無効または適合しない出力を生み、強制的な選択が挙動を変えることを示す。
- 強制選択プロンプトはモデル間で効果にばらつきがあり、有効な回答を引き出せないこともある。
- 言い換えのバリエーションは複数のモデルに対して PCT の結果を大きく変え、言い換えの頑健性が低いことを示す。
- オープンエンドのプロンプトは四択と異なる同意パターンを生成し、多くの命題で設定ごとに立場が転ぶ。
- オープンエンドの結果は、全体として経済的には右寄り、社会的にはリバタリアン寄りの傾向へとずれる傾向を示すが、設定間の不安定さは依然として存在する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。