[論文レビュー] Pre-Trained Large Language Models for Industrial Control
本論文は GPT-4 を BEAR における HVAC の訓練不要コントローラとして用いる研究を行い、デモンストレーションとプロンプト設計に基づく少データ・低デットで PPO や MPC と競合する性能を示し、デモンストレーションとプロンプトの体系的なアブレーションを実施している。
For industrial control, developing high-performance controllers with few samples and low technical debt is appealing. Foundation models, possessing rich prior knowledge obtained from pre-training with Internet-scale corpus, have the potential to be a good controller with proper prompts. In this paper, we take HVAC (Heating, Ventilation, and Air Conditioning) building control as an example to examine the ability of GPT-4 (one of the first-tier foundation models) as the controller. To control HVAC, we wrap the task as a language game by providing text including a short description for the task, several selected demonstrations, and the current observation to GPT-4 on each step and execute the actions responded by GPT-4. We conduct series of experiments to answer the following questions: 1)~How well can GPT-4 control HVAC? 2)~How well can GPT-4 generalize to different scenarios for HVAC control? 3) How different parts of the text context affect the performance? In general, we found GPT-4 achieves the performance comparable to RL methods with few samples and low technical debt, indicating the potential of directly applying foundation models to industrial control tasks.
研究の動機と目的
- foundation モデルを用いた産業タスクの低サンプル・低デット制御を動機づける。
- 事前学習済み LLM が異種建物と天候下で少数のデモンストレーションで HVAC を制御できることを示す。
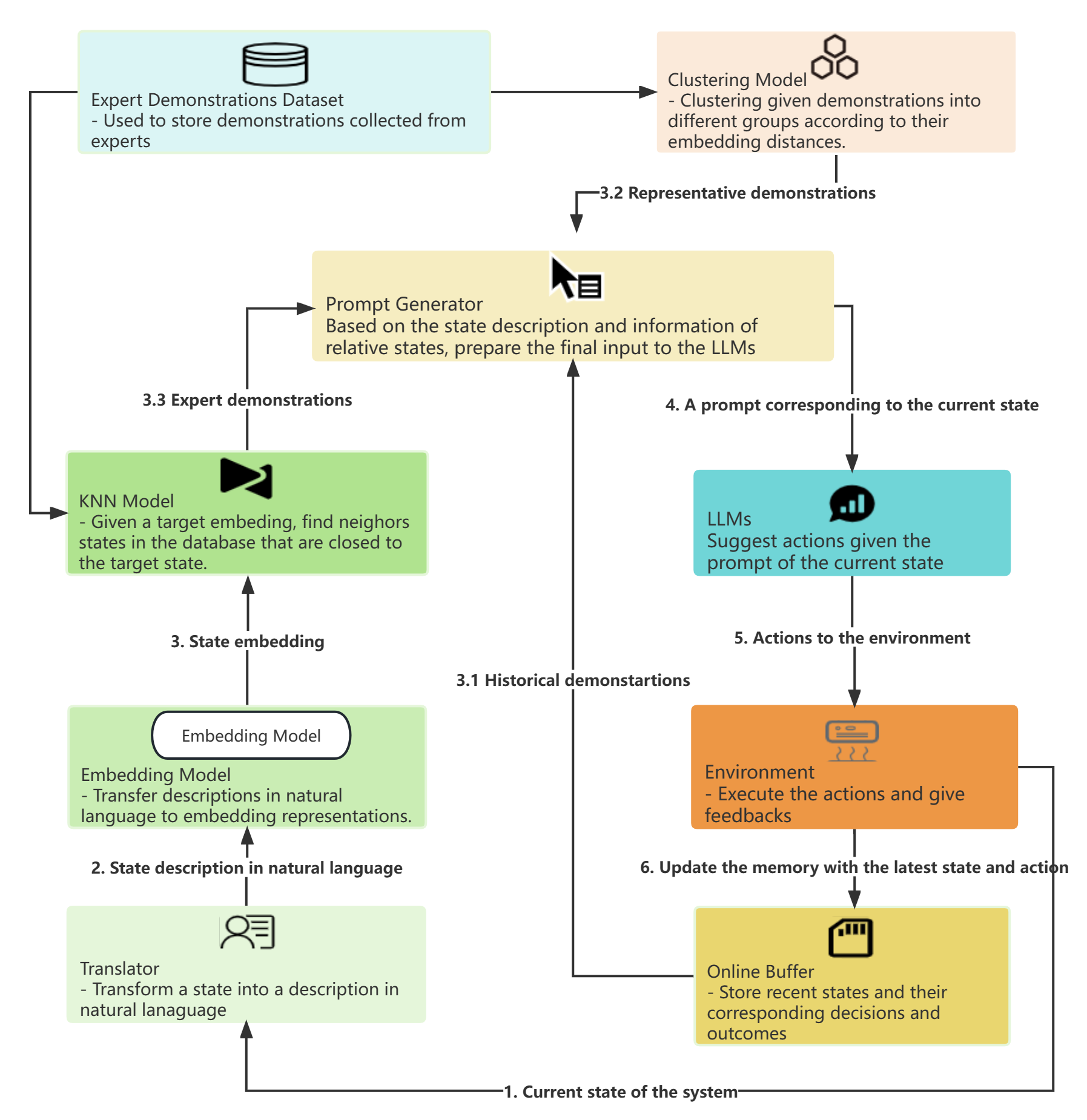
- インコンテキスト制御を可能にするデモンストレーション選択、翻訳機、プロンプト生成機構を設計する。
- デモンストレーションの種類と量が GPT-4 の制御性能に与える影響を分析する。
- 将来の低デットな産業制御に向けたLLM 利用の設計指針となるアブレーションを提供する。
提案手法
- BEAR 環境で HVAC を制御する意思決定者として GPT-4 を用いる。
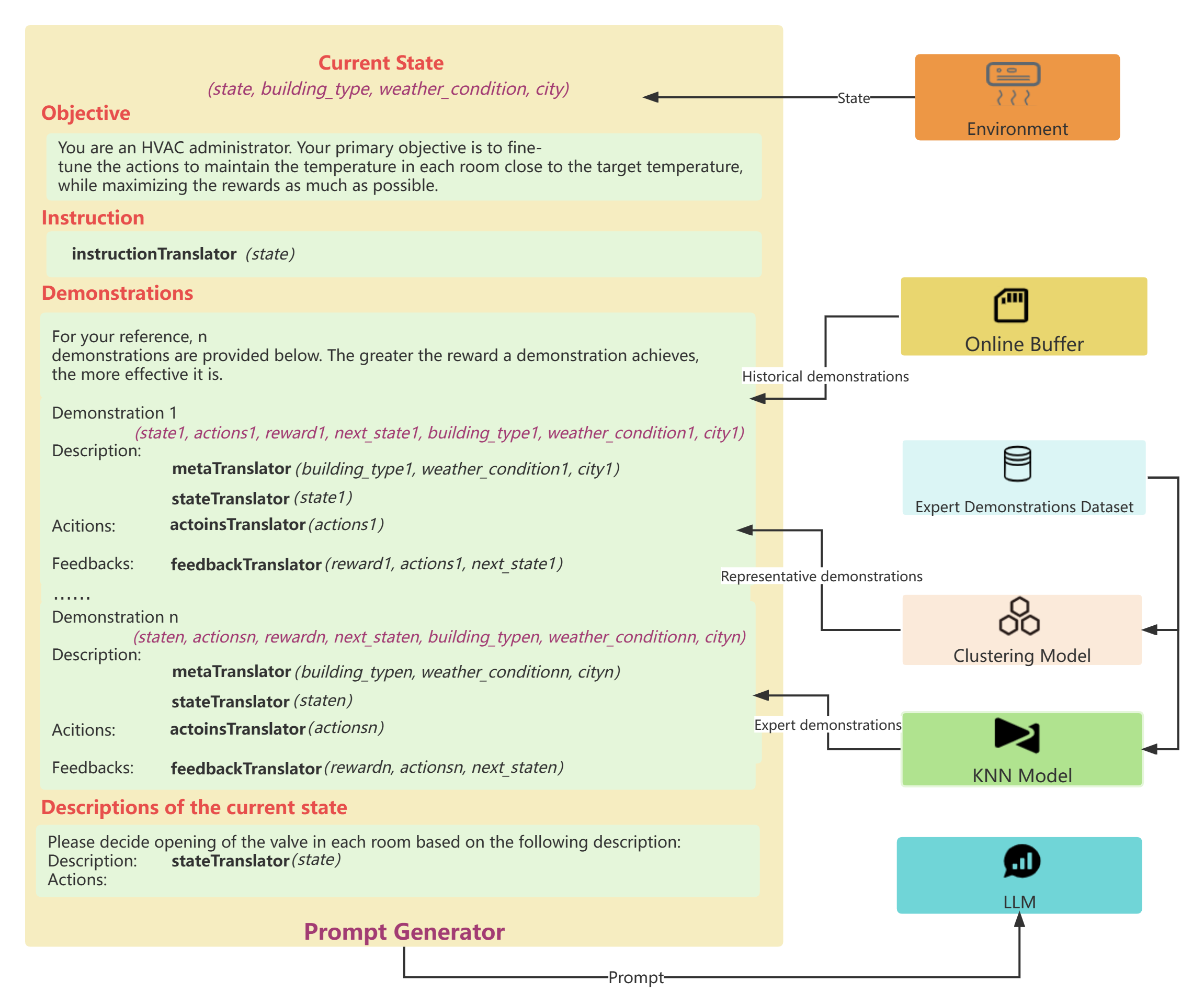
- LLM のために数値状態/行動を自然言語に変換する翻訳スタックを導入する。
- デモンストレーションバッファとプロンプト生成器を実装し、デモンストレーションと現在の状態からプロンプトを作成する。
- 専門家デモンストレーション、過去の相互作用、クラスタリングを活用して代表的なプロンプトを選択する。
- GPT-4 を MPC および PPO のベースラインと比較し、デモンストレーションの種類とプロンプト設計のアブレーションを実施する。
実験結果
リサーチクエスチョン
- RQ1 GPT-4 は少数のデモンストレーションで伝統的な RL 手法と同等の HVAC 制御が可能か。
- RQ2 GPT-4 は建物と天候条件を跨いだ HVAC 制御でどれだけ一般化できるか。
- RQ3 デモンストレーションの種類とプロンプト設計が GPT-4 の制御性能に与える影響は何か。
- RQ4 訓練不要でプロンプトベースの手法はサンプル効率とデットの点で MPC および PPO と比較してどうか。
主な発見
| Algo. | Reward Mean | Reward Std. | Demo. Buildings | Demo. Weather | Demo. |
|---|---|---|---|---|---|
| GPT-A | 1.16 | 0.04 | OfficeSmall; OfficeLarge | ColdDry; WarmDry; MixedDry | H2R2E4 |
| GPT-B | 1.18 | 0.04 | OfficeSmall; OfficeMedium; OfficeLarge | ColdDry; WarmDry; MixedDry | H2R2E4 |
| GPT-C | 1.17 | 0.05 | OfficeSmall; OfficeLarge | CoolDry; ColdDry; WarmDry; MixedDry | H2R2E4 |
| GPT-D | 1.20 | 0.02 | OfficeSmall; OfficeMedium; OfficeLarge | CoolDry; ColdDry; WarmDry; MixedDry | H2R2E4 |
| GPT-E | 1.09 | 0.02 | OfficeMedium | CoolDry | H2R2E4 |
| GPT-F | 1.23 | 0.01 | None | None | H4R0E0 |
| GPT-Random | 0.88 | 0.12 | OfficeSmall; OfficeMedium; OfficeLarge | CoolDry; ColdDry; WarmDry; MixedDry | - |
| MPC | 1.35 | 0.00 | - | - | - |
| PPO | 1.21 | 0.04 | - | - | - |
| Random | -26.72 | 0.65 | - | - | - |
- GPT-4 は PPO と同等以上の報酬を達成し、試験ケース全体でランダムポリシーを大きく上回る。
- デモンストレーションに同一建物条件や同一天候条件が含まれると性能が向上し、関連する事前情報が有効な一般化を促すことを示す。
- 異なる建物と天候条件からのデモンストレーションを用いても強い制御が可能であり、ターゲットに関連するデモが利用可能な場合にはより良い結果となる。
- 専門家デモンストレーションがなくても、オンライン相互作用に依存するプロンプトベースの制御で GPT-4 が最良の結果を達成できる。
- 複数グループを通じて、GPT ベースのポリシーは伝統的ベースラインに接近または上回る報酬を、比較的低いサンプル数と技術的デットで達成する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。