[論文レビュー] PredRNN: A Recurrent Neural Network for Spatiotemporal Predictive Learning
PredRNNは時空間的なメモリフローとデカップルメモリセル(ST-LSTM)を導入し、カリキュラム学習戦略とともに未来フレームを予測することで、複数のデータセットで競争力のある性能を達成します。
The predictive learning of spatiotemporal sequences aims to generate future images by learning from the historical context, where the visual dynamics are believed to have modular structures that can be learned with compositional subsystems. This paper models these structures by presenting PredRNN, a new recurrent network, in which a pair of memory cells are explicitly decoupled, operate in nearly independent transition manners, and finally form unified representations of the complex environment. Concretely, besides the original memory cell of LSTM, this network is featured by a zigzag memory flow that propagates in both bottom-up and top-down directions across all layers, enabling the learned visual dynamics at different levels of RNNs to communicate. It also leverages a memory decoupling loss to keep the memory cells from learning redundant features. We further propose a new curriculum learning strategy to force PredRNN to learn long-term dynamics from context frames, which can be generalized to most sequence-to-sequence models. We provide detailed ablation studies to verify the effectiveness of each component. Our approach is shown to obtain highly competitive results on five datasets for both action-free and action-conditioned predictive learning scenarios.
研究の動機と目的
- 時空間系列の予測学習を動機づけ、歴史的文脈から未来のフレームを生成する。
- 短期と長期の依存性の両方を扱う、メモリ拡張リカレントアーキテクチャで時空間ダイナミクスをモデル化する。
- 文脈フレームから長期ダイナミクスを学習し、一般化を改善するための学習戦略を導入する。
- モデルをアクション条件付きのビデオ予測へ拡張し、その有効性を評価する。
提案手法
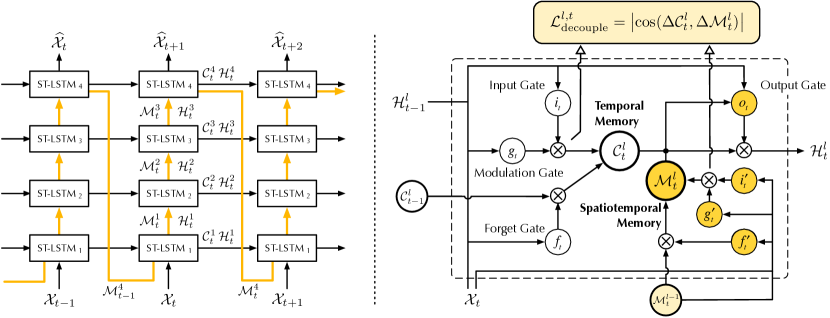
- ジグザグの経路で層間にメモリを伝播させる時空間メモリフローを導入する。
- 長期・短期ダイナミクスを別々にモデル化するため、2つのデカップリングメモリセル(CとM)を備えたSpatiotemporal LSTM(ST-LSTM)を提案する。
- CとMの間で冗長でない特徴を促進するためにメモリデカップリング損失を適用する。
- コンテキストフレームから長期ダイナミクスの学習を強化するためにReverse Scheduled Samplingを組み込む。
- エージェント主導の環境のシミュレーションのために、アクション統合を備えたアクション条件付きPredRNNへ拡張する。
- フレーム再構成目的とデカップリング損失を用いてエンドツーエンドで訓練する;要素の検証のためにアブレーションを提供する。
![Figure 1: Left: the spatiotemporal memory flow architecture that uses ConvLSTM as the building block. The orange arrows show the deep-in-time path of memory state transitions. Right: the original ConvLSTM network proposed by Shi et al. [ 1 ] .](https://ar5iv.labs.arxiv.org/html/2103.09504/assets/x1.png)
実験結果
リサーチクエスチョン
- RQ1ジグザグの時空間メモリフローは、フレーム予測のための層間情報共有を改善できるか?
- RQ2メモリセルを長期と短期の成分にデカップリングすることは予測モデリングを強化するか?
- RQ3提案されたカリキュラム学習(Reverse Scheduled Sampling)は、文脈フレームから長期ダイナミクスの学習に役立つか?
- RQ4アクション条件付けは時空間予測の性能にどう影響するか?
- RQ5アブレーションは、全体の性能への各要素の寄与を確認できるか?
主な発見
- アクションなしおよびアクション条件付きの予測学習シナリオの両方で、5つのデータセットにおいて最先端の性能を達成します。
- メモリフロー、デカップリングを備えたST-LSTM、そしてRSSトレーニングスキームの有効性を検証する詳細なアブレーション研究を提供します。
- Moving MNIST、KTH、レーダーエコー降水予測、Traffic4Cast、BAIRデータセットで競争力のある結果を示します。
- ロボットと物体の相互作用シナリオのためのアクション条件付きバリアントでアプローチを拡張します。
- 再現性を促進するためのコードを公開します(論文にGitHubリンクが含まれています)。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。