[論文レビュー] Principled Weight Initialization for Hypernetworks
本論文は hyperfan initialization for hypernetworks を導入し、主ネットの活性化/勾配スケールを保存する原理的な分散ベースのスキーム(hyperfan-in および hyperfan-out)を提供する。任意の初期化よりも安定性と収束性を改善する。
Hypernetworks are meta neural networks that generate weights for a main neural network in an end-to-end differentiable manner. Despite extensive applications ranging from multi-task learning to Bayesian deep learning, the problem of optimizing hypernetworks has not been studied to date. We observe that classical weight initialization methods like Glorot & Bengio (2010) and He et al. (2015), when applied directly on a hypernet, fail to produce weights for the mainnet in the correct scale. We develop principled techniques for weight initialization in hypernets, and show that they lead to more stable mainnet weights, lower training loss, and faster convergence.
研究の動機と目的
- 古典的な重み初期化が hypernetworks が mainnet の重みを生成する場合に機能しない理由を特定する。
- hypernetworks に合わせた原理的な分散ベースの初期化ルールを開発する。
- 理論的および実証的に、hyperfan 初期化が活性化/勾配を安定化させ、収束性を向上させることを示す。
提案手法
- 分散分析を用いて hyperfan-in および hyperfan-out の初期化を hypernetworks に対して導出する。
- hypernet を mainnet の重みの生成器としてモデル化し、前方/後方の分散伝搬を分析する。
- mainnet の活性化/勾配の分散を保持するために H, h, G, g レイヤの特定の分散公式を提案する。
- hypernet が出力するのが重みのみか、重みとバイアスの両方かのケースを区別する。
- hypernet の重み分散を古典的な fan-in/fan-out の初期化意味論と整合させる初期化スキームを提供する。
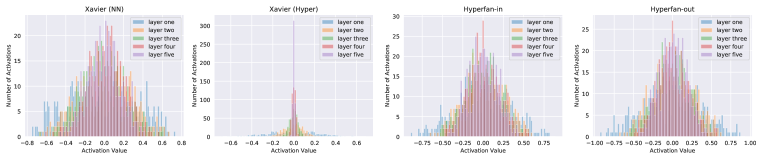
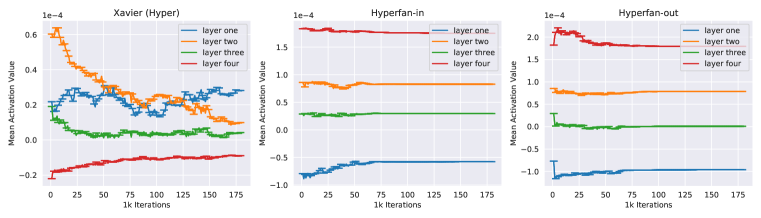
実験結果
リサーチクエスチョン
- RQ1主net の重みを生成する hypernetworks に古典的な初期化スキームを適用するとなぜ機能しないのか?
- RQ2深さを通じて mainnet の活性化と勾配の分散を安定に保つように hypernetworks をどのように初期化できるか?
- RQ3hyperfan-in および hyperfan-out の初期化は、異なる mainnet アーキテクチャやタスクで安定した訓練を可能にするか?
主な発見
- Hypernet に対する古典的な初期化は mainnet の活性化を爆発的にさせる。
- Hyperfan-in および hyperfan-out の初期化は mainnet の分散を保持し、安定した訓練を可能にする。
- Hyperfan 手法は MNIST のフィードフォワード実験で初期損失を低減し、収束を早める。
- Xavier/Kaiming が Hypernet で機能しない場合(CIFAR-10、ImageNet ベイズ設定など)にも Hyperfan 初期化は訓練を可能にする。
- 両方の hyperfan-in および hyperfan-out は Tasks にわたり SGD で機能し、実務的には特に強い好みはなかった。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。