[論文レビュー] Prismatic VLMs: Investigating the Design Space of Visually-Conditioned Language Models
本論文は、標準化された評価スイートとモジュール型トレーニングフレームワークを通じて、視覚条件付き言語モデル(VLM)における設計選択を検証し、7B/13Bスケールでオープンベースラインを上回る Prism s を導入する。
Visually-conditioned language models (VLMs) have seen growing adoption in applications such as visual dialogue, scene understanding, and robotic task planning; adoption that has fueled a wealth of new models such as LLaVa, InstructBLIP, and PaLI-3. Despite the volume of new releases, key design decisions around image preprocessing, architecture, and optimization are under-explored, making it challenging to understand what factors account for model performance $-$ a challenge further complicated by the lack of objective, consistent evaluations. To address these gaps, we first compile a suite of standardized evaluations spanning visual question answering, object localization, and challenge sets that probe properties such as hallucination; evaluations that provide fine-grained insight VLM capabilities. Second, we rigorously investigate VLMs along key design axes, including pretrained visual representations and training from base vs. instruct-tuned language models, amongst others. We couple our analysis with three resource contributions: (1) a unified framework for evaluating VLMs, (2) optimized, flexible training code, and (3) checkpoints for all models, including a family of VLMs at the 7-13B scale that strictly outperform InstructBLIP and LLaVa v1.5, the state-of-the-art in open VLMs.
研究の動機と目的
- VLMs を網羅する VQA、局所化、および難易度の高いタスクを含む標準化され細粒度の評価スイートを提供する。
- VLM の主要な設計軸(最適化、画像処理、視覚表現、言語モデル)を体系的に分析する。
- 再現性と将来の研究を可能にする最適化され柔軟な VLM トレーニングコードベースとチェックポイントを提供する。
提案手法
- 事前学習済みのビジュアルバックボーン、ビジョン-ランゲージプロジェクター、および言語モデルを備えた、単純な patch-as-token VLM アーキテクチャを採用する。
- 完全に公開された事前学習データの混合(LLaVa v1.5 コンポーネント)と単段階トレーニングを用いて、マルチステージパイプラインと対比させる。
- Fully Sharded Data Parallel (FSDP) と BF16 混合精度を用いた PyTorch ベースの最適化済みトレーニングフレームワークを開発・公開する。
- 能力と幻視リスクを検証するため、VQA、局所化、および難易度別セットを横断する11のベンチマークを含むオープン評価スイートを構築する。
- 最適化手順、画像処理/視覚表現、言語モデル、スケーリング特性の4つの設計軸にわたって実験する。
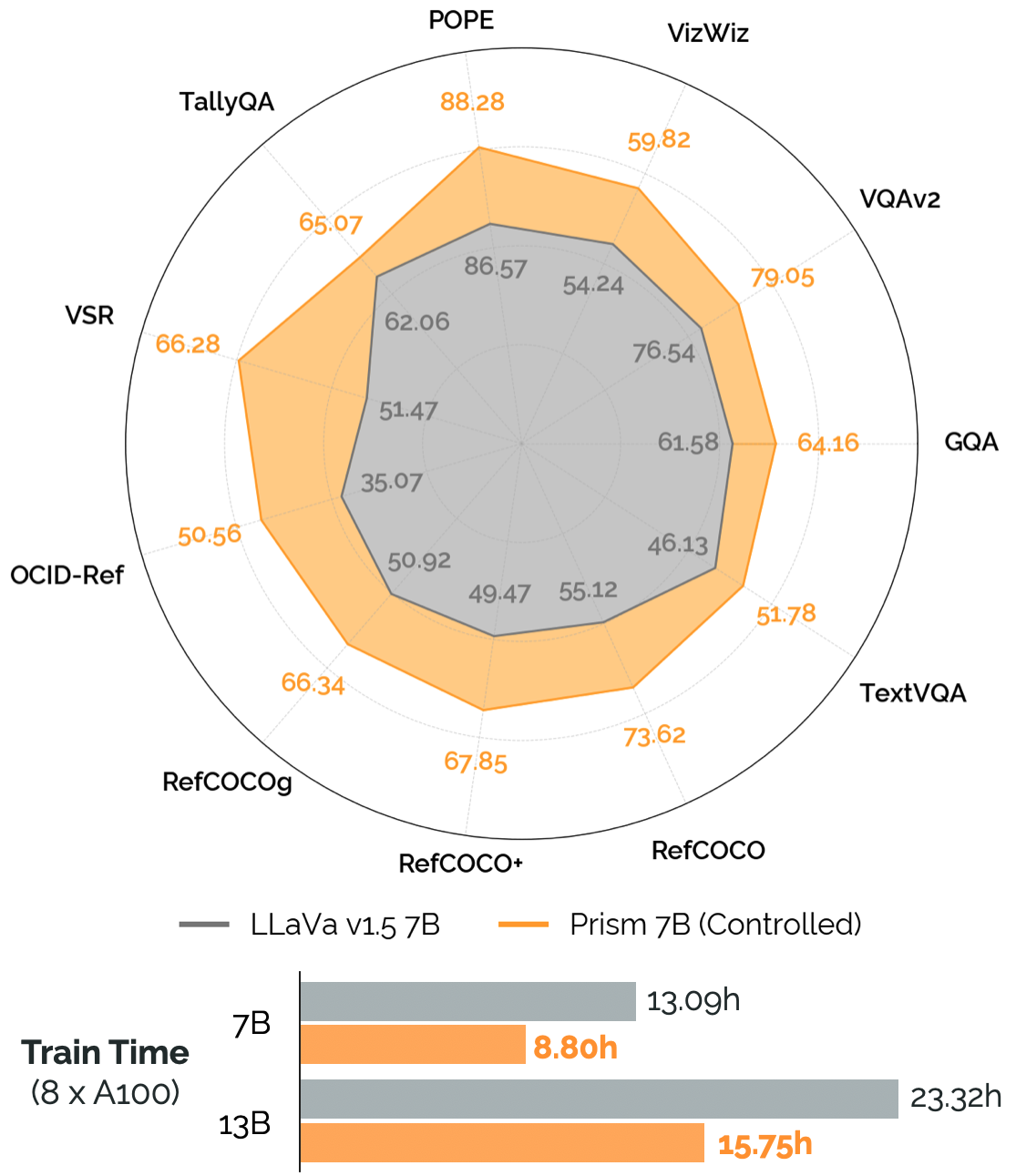
実験結果
リサーチクエスチョン
- RQ1画像処理、視覚表現、および言語モデルのどの設計選択が VLM の性能に最も影響を与えるか?
- RQ2マルチステージトレーニングは必要か、それともシングルステージトレーニングで同等またはより良い結果をより効率的に達成できるか?
- RQ3統合された視覚バックボーンとアンサンブリングは、タスク全体で VLM の能力を向上させるか?
- RQ4VLM におけるベース LM と instruct-tuned LM はどう比較されるか、言語のみのデータから生じる安全性への影響は何か?
- RQ5トレーニング時間と多様なデータソースは下流性能にどう影響するか?
主な発見
- シングルステージトレーニングは性能を維持または向上させつつ、計算コストを20-25%削減する。
- 初期トレーニング後のビジョンバックボーンの微調整は性能を低下させ、特に局所化タスクで顕著である。
- DINOv2 と SigLIP の視覚表現を統合すると性能が向上し、DINOv2 + SigLIP が多くの場合最も効果的である。
- ベースLM(例:Llama-2)は VLM で instruct-tuned LM と同等かそれ以上に性能を発揮し、幻視が少なくなる;言語のみの安全データは保全性を支援する。
- 画像解像度を336pxまたは384pxに上げると性能が大幅に向上するが、計算コストは高くなる。
- DINOv2をSigLIPまたはCLIP/SigLIPの特徴とアンサンブルすると、局所化と難易度タスクで顕著な利得を生み出す;素朴な画像リサイズは一部の設定でレターボックスパディングより上回ることがある。
- 多様なデータソース(LVIS-Instruct-4V、LRV-Instruct)を追加すると性能が向上し、特にLRV-Instructが大幅な改善をもたらす。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。