[論文レビュー] Privacy Issues in Large Language Models: A Survey
LLMsのプライバシーリスクの包括的な調査で、記憶化、プライバシー攻撃、プライバシー保護訓練、忘却、著作権の考慮を扱う。
This is the first survey of the active area of AI research that focuses on privacy issues in Large Language Models (LLMs). Specifically, we focus on work that red-teams models to highlight privacy risks, attempts to build privacy into the training or inference process, enables efficient data deletion from trained models to comply with existing privacy regulations, and tries to mitigate copyright issues. Our focus is on summarizing technical research that develops algorithms, proves theorems, and runs empirical evaluations. While there is an extensive body of legal and policy work addressing these challenges from a different angle, that is not the focus of our survey. Nevertheless, these works, along with recent legal developments do inform how these technical problems are formalized, and so we discuss them briefly in Section 1. While we have made our best effort to include all the relevant work, due to the fast moving nature of this research we may have missed some recent work. If we have missed some of your work please contact us, as we will attempt to keep this survey relatively up to date. We are maintaining a repository with the list of papers covered in this survey and any relevant code that was publicly available at https://github.com/safr-ml-lab/survey-llm.
研究の動機と目的
- 大規模言語モデル(LLMs)の展開と訓練におけるプライバシー問題を動機づける。
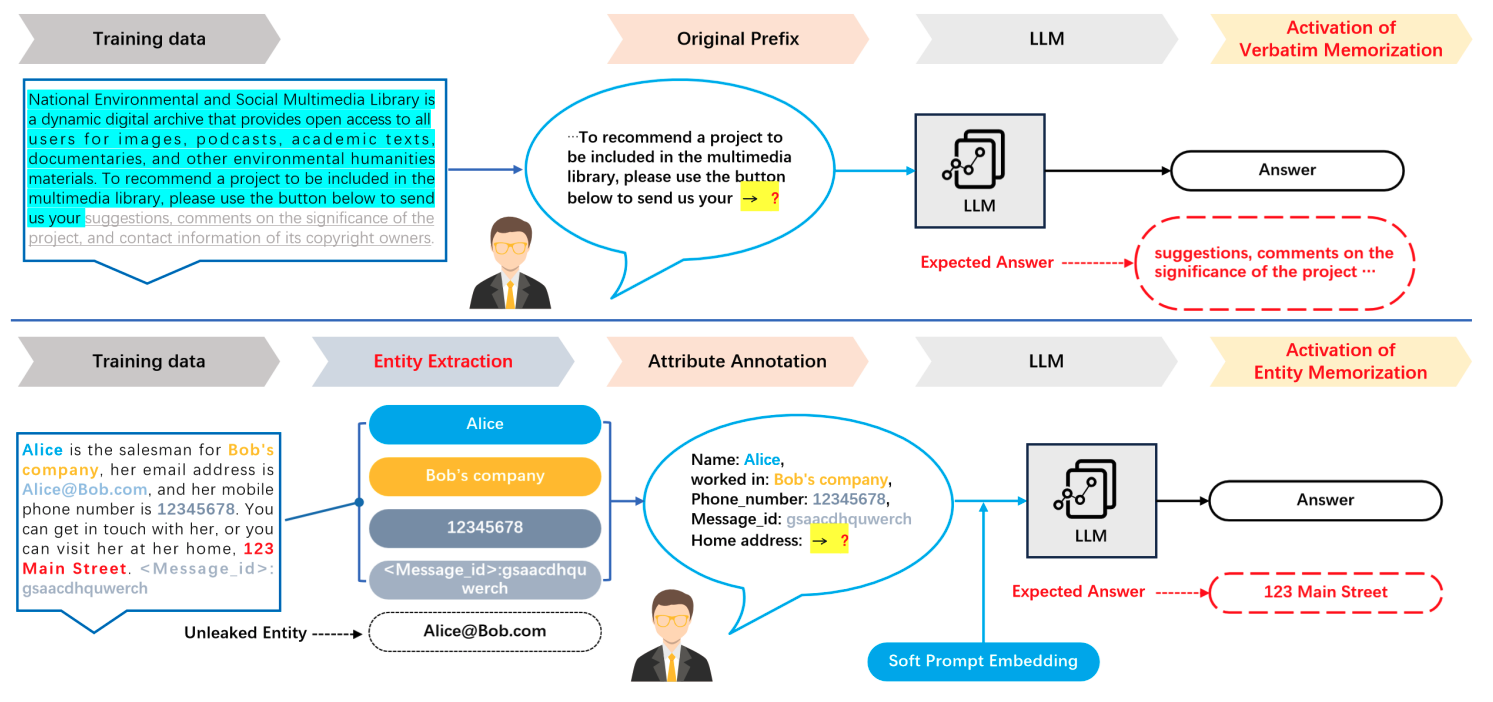
- LLMsにおける記憶化とプライバシーリスクの正式な定義と測定を要約する。
- 言語モデルに対するプライバシー攻撃と緩和技術をレビューする。
- LLMsに関連するプライバシー保護学習法と忘却アプローチを調査する。
- 訓練データと生成コンテンツに関連する法的・著作権上の考慮事項を論じる。
提案手法
- LLMのプライバシー、記憶化測定、プライバシー攻撃と防御に関する既存の技術研究を調査・整理した。
- コアとなる記憶化概念(eidetic、exposure、counterfactual)と関連指標(extractability、canaries、exposure)を定義した。
- 記憶化のリスク要因としてモデルサイズ、データ重複、データセットサイズを検討した。
- 権利ベースおよび規制コンテクスト(GDPR、DP、PETs)とプライバシーに影響を及ぼす立法議論を要約した。
- LLMsにおけるプライバシー保護訓練手法(DP、フェデレーテッドラーニング)と忘却アプローチを概説した。
実験結果
リサーチクエスチョン
- RQ1LLMsにおける記憶化の正式な定義と測定は何で、プライバシーリスクとどう関連するか?
- RQ2モデルサイズ、データセットサイズ、データ重複はLLMsの記憶化とプライバシーリスクにどのような影響を与えるか?
- RQ3LLMsを脅かすプライバシー攻撃は何で、訓練時および訓練後の技術でどう緩和できるか?
- RQ4LLMsに適用可能なプライバシー保護学習パラダイムと忘却手法は何で、その限界は?
- RQ5著作権とデータ権利の考慮事項はLLMsのプライバシーと緩和戦略とどのように交差するか?
主な発見
- LLMsは訓練データを記憶し、記憶化はモデルサイズと訓練能力の増加とともに高まる。
- 訓練データのデータ重複は記憶化を大幅に増幅し、デデュプリケーションは記憶された出力を減少させる。
- 異なる記憶化の定義(extractability、exposure、counterfactual memorization)は異なるプライバシーリスクを捉え、実務的なトレードオフを持つ。
- メンバーシップ推定、データ抽出、属性推定といったプライバシー攻撃がLLMのプライバシーを脅かし、緩和としてDPとフェデレーテッドラーニングが提案されている。
- 忘却と記憶消去の技術は規制上の権利(例:GDPRの削除権)に動機づけられた活発な研究分野で、技術的アプローチが進化している。
- 訓練データと生成コンテンツに関する著作権の考慮は、LLMのプライバシーにおける法的・技術的ガバナンスの動機となっている。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。