[論文レビュー] Privacy Leakage on DNNs: A Survey of Model Inversion Attacks and Defenses
この論文は、視覚、テキスト、グラフモダリティ全体にわたる DNN の Model Inversion 攻撃と防御の包括的な調査を提供し、MI 研究のためのオープンソースツールボックスを導入します。
Deep Neural Networks (DNNs) have revolutionized various domains with their exceptional performance across numerous applications. However, Model Inversion (MI) attacks, which disclose private information about the training dataset by abusing access to the trained models, have emerged as a formidable privacy threat. Given a trained network, these attacks enable adversaries to reconstruct high-fidelity data that closely aligns with the private training samples, posing significant privacy concerns. Despite the rapid advances in the field, we lack a comprehensive and systematic overview of existing MI attacks and defenses. To fill this gap, this paper thoroughly investigates this realm and presents a holistic survey. Firstly, our work briefly reviews early MI studies on traditional machine learning scenarios. We then elaborately analyze and compare numerous recent attacks and defenses on Deep Neural Networks (DNNs) across multiple modalities and learning tasks. By meticulously analyzing their distinctive features, we summarize and classify these methods into different categories and provide a novel taxonomy. Finally, this paper discusses promising research directions and presents potential solutions to open issues. To facilitate further study on MI attacks and defenses, we have implemented an open-source model inversion toolbox on GitHub (https://github.com/ffhibnese/Model-Inversion-Attack-ToolBox).
研究の動機と目的
- 事前学習済みモデルがトレーニングデータを漏らす可能性を検証することで、プライバシー懸念を喚起する。
- コンピュータビジョン、NLP、グラフ学習にわたる MI 攻撃と防御を体系的に分析する。
- ホワイトボックスとブラックボックスの攻撃設定を比較し、モダリティ固有の課題を特定する。
- プライバシーとモデルの有用性のトレードオフを含む防御戦略を要約する。
- 未解決の課題を強調し、今後の研究の方向性を提案する。
提案手法
- MI 攻撃を、画像向けの生成的事前分布に基づく方式と最適化ベースの方式に分解し、GAN や拡散モデルを含む事前分布を考慮する。
- 攻撃設定をホワイトボックスまたはブラックボックスに分類し、目的関数と最適化レジームを説明する。
- 情報漏洩を減らすためのモデル出力処理と堅牢な訓練による防御機構を要約する。
- 埋め込み最適化、トークン探索、悪意あるプロンプト設計パラダイムを含む、NLP への MI 調査の拡張。
- 接続最適化と逆写像/関係推論に焦点を当てたグラフ MI 攻撃を論じ、対応する防御と共に検討する。
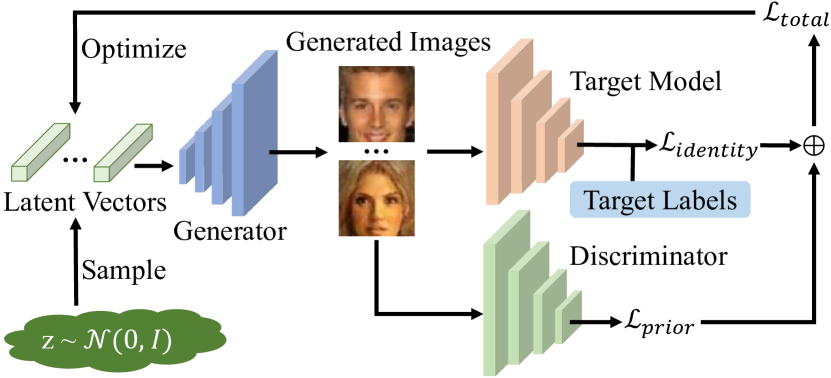
実験結果
リサーチクエスチョン
- RQ1DNN における画像、テキスト、グラフデータの主な MI 攻撃戦略は何か。
- RQ2防御は MI リスクをどのように軽減し、モダリティ間でのモデル性能へはどのような影響を与えるか。
- RQ3ホワイトボックスとブラックボックスの MI 設定の違いは何であり、攻撃者はそれぞれにどう適応するか。
- RQ4さまざまなデータモダリティにおける MI 攻撃からのプライバシー保護にはどのような未解決の課題が残っているか。
主な発見
- MI 攻撃は、生成的事前分布(GAN、拡散モデル)を用いるか、直接最適化によって private training samples を再構成できる。
- ホワイトボックス攻撃は勾配ベースの最適化に依存し、ブラックボックス攻撃は代替モデル、勾配推定、探索ベースの手法を用いる。
- 防御は主に出力処理と堅牢な訓練に分類され、情報漏洩を低減しタスク有用性を維持する。
- MI 研究は視覚、NLP、グラフにまたがり、モダリティ固有の攻撃・防御技術とトレードオフを含む。
- 再現とさらなる研究を促進するためのオープンソースツールボックスが提供されている。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。