[論文レビュー] Proactive Detection of Voice Cloning with Localized Watermarking
AudioSealは、AI生成スピーチを検出・サンプルレベルで局在化し、属性づける積極的な局所音声ウォーターマークシステムであり、単一パスの高速検出器を用いて従来のウォーターマーク法より優れている。
In the rapidly evolving field of speech generative models, there is a pressing need to ensure audio authenticity against the risks of voice cloning. We present AudioSeal, the first audio watermarking technique designed specifically for localized detection of AI-generated speech. AudioSeal employs a generator/detector architecture trained jointly with a localization loss to enable localized watermark detection up to the sample level, and a novel perceptual loss inspired by auditory masking, that enables AudioSeal to achieve better imperceptibility. AudioSeal achieves state-of-the-art performance in terms of robustness to real life audio manipulations and imperceptibility based on automatic and human evaluation metrics. Additionally, AudioSeal is designed with a fast, single-pass detector, that significantly surpasses existing models in speed - achieving detection up to two orders of magnitude faster, making it ideal for large-scale and real-time applications.
研究の動機と目的
- 音声のボイスクローン作成や生成モデルの悪用に対して音声を認証する必要性を動機づける。
- 検出・局在化・AI生成音声の帰属を可能にする局所的ウォーターマーク手法(AudioSeal)を提案する。
- 不可聴なウォーターマークを埋め込み高精度で検出するために、ジェネレータとディテクタを共同訓練する。
- 不可知覚性とサンプルレベルの局在化を改善する新規の知覚損失および局在化損失を取り入れる。
- 実際の音声編集に対する頑健性、局在化精度、および計算効率を評価する。
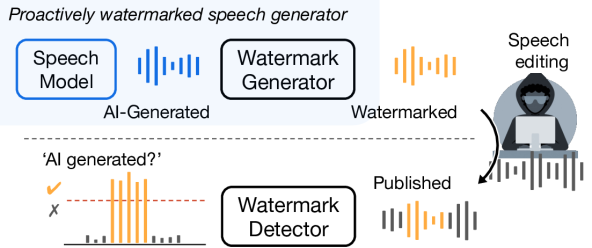
提案手法
- ジェネレータが音声に加法的なウォーターマークを付加する共通のジェネレータ-ディテクタアーキテクチャ。
- ディテクタはウォーターマークの有無を示すサンプルレベルの検出ロジットを出力する。
- 訓練はマスクされた局在化戦略を用い、正確なサンプルレベルの局在化を可能にする。
- 聴覚マスキングに着想を得た新規のTF-Loudness知覚損失で不可聴性を向上させる。
- ウォーターマークマスキング拡張と頑健な音声編集拡張を組み合わせた4段階訓練。
- モデル/バージョンに音声を帰属させるためのオプションのマルチビットウォーターマーキング。
実験結果
リサーチクエスチョン
- RQ1局所化ウォーターマーキングは、長い音声内でAI生成スピーチをサンプルレベルで検出可能にするか。
- RQ2提案されたAudioSealアプローチは、一般的な現実世界の音声操作・編集に対してどれだけ頑健か。
- RQ3ディテクタはブルートフォース同期なしの高速・リアルタイム検出に対応しているか。
- RQ4マルチビットメッセージは検出を妨げることなく特定のモデル版本への帰属を可能にするか。
- RQ5従来の手法と比較してウォーターマーク付与が知覚音声品質に与える影響はどの程度か。
主な発見
- AudioSealは幅広い音声編集に対して最先端の頑健性を達成し、ほぼ完璧な検出率を示す。
- ディテクタは単一パスで実行され、リアルタイム検出のためにすべての時間ステップでロジットを出力する。
- 局在化精度は高く、短いウォーターマーク付きセグメントでサンプルレベルの局在化(1/16k秒)とIoUが約0.99に達する。
- AudioSealは検出で従来法のWavMarkなどより最大100倍速く、生成も約14倍高速。
- マルチビットウォーターマーキングは高精度でモデル/versionへの帰属を可能にし、編集下でも検出は頑健。
- 実証分析は、ディテクタの重みを非公開に保つことが敵対的なウォーターマーク除去への耐性に重要であることを示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。