[論文レビュー] Probing out-of-distribution generalization in machine learning for materials
本論文は、材料科学の機械学習におけるヒューリスティックなOODテストが多く補間を調べ、真の外挿ではないことを示している;多くのモデルは多様なOODタスクに対して一般化が良好であり、表現的にOODな場合にはスケーリングがむしろ性能を落とすこともある。
Scientific machine learning (ML) endeavors to develop generalizable models with broad applicability. However, the assessment of generalizability is often based on heuristics. Here, we demonstrate in the materials science setting that heuristics based evaluations lead to substantially biased conclusions of ML generalizability and benefits of neural scaling. We evaluate generalization performance in over 700 out-of-distribution tasks that features new chemistry or structural symmetry not present in the training data. Surprisingly, good performance is found in most tasks and across various ML models including simple boosted trees. Analysis of the materials representation space reveals that most tasks contain test data that lie in regions well covered by training data, while poorly-performing tasks contain mainly test data outside the training domain. For the latter case, increasing training set size or training time has marginal or even adverse effects on the generalization performance, contrary to what the neural scaling paradigm assumes. Our findings show that most heuristically-defined out-of-distribution tests are not genuinely difficult and evaluate only the ability to interpolate. Evaluating on such tasks rather than the truly challenging ones can lead to an overestimation of generalizability and benefits of scaling.
研究の動機と目的
- 材料MLにおけるOODタスクの定義におけるバイアスを暴く。
- 複数のデータセットとモデルにわたり、700超のOODタスクを体系的に評価する。
- 表現的OODと統計的(ドメイン)OODを区別し、それらが一般化へ与える影響を評価する。
- トレーニングデータ量と時間がOOD性能およびニューラルスケーリングの主張にどう影響するかを調査する。
提案手法
- JARVIS、Materials Project (MP)、Open Quantum Materials Database (OQMD) を横断して6つのOOD基準を評価する。
- Matminer 記述子を用いたランダムフォレストと XGBoost、GMP Gaussian multipole neural network、ALIGNN Graph Neural Network、結晶テキスト記述を用いた LLMベースの LLM-Prop を訓練する。
- 要素・族・空間群などの leave-one-X タスクに対して MAE と R^2 指標で性能を評価する。
- SHAP に基づく補正を用いて成分(組成)と構造のバイアス源を分離する。
- UMAP を適用して表現空間を可視化し、カーネル密度に基づくドメイン識別を行う。
- OOD 対 ID データのために、トレーニング時間とデータセットサイズを変えてニューラルスケーリングを検討する。
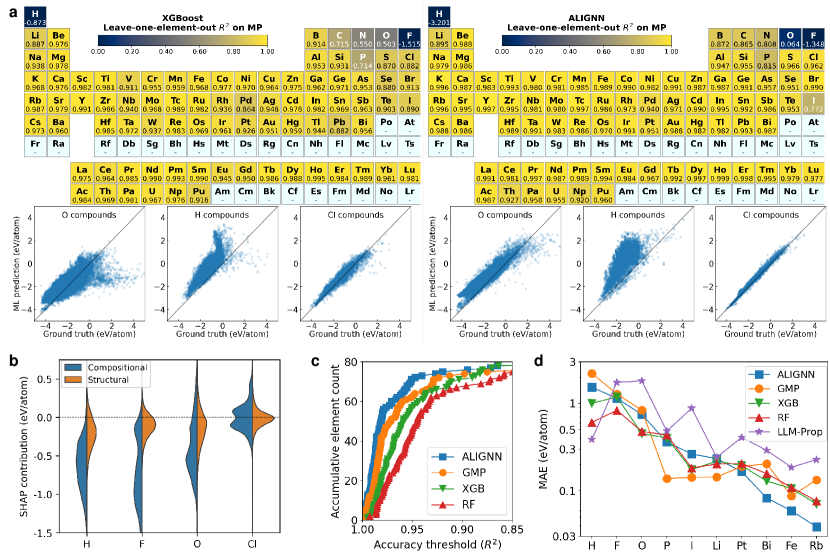
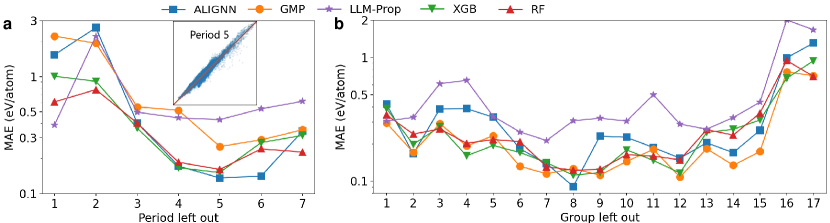
実験結果
リサーチクエスチョン
- RQ1訓練データを超えた真の外挿に関して、OODタスクを定義する際の一般的なヒューリスティックはどのように関連するか?
- RQ2化学的・構造的グループが訓練から除外された場合、MLモデルは一般化できるか?
- RQ3OOD予測に体系的なバイアスは存在するか、組成的要因や構造要因で説明できるか?
- RQ4表現的ドメイン(ID対OOD in embedding space)が、観測されたスケーリング則にどのような影響を与えるか?
- RQ5堅牢な一般化を達成するための材料MLモデルの評価と設計に対する影響は何か?
主な発見
| Metric | Dataset | ALIGNN | GMP | LLM-Prop | XGB | RF |
|---|---|---|---|---|---|---|
| MAE | MP | 0.033 | 0.052 | 0.063 | 0.078 | 0.090 |
| MAE | JARVIS | 0.036 | 0.081 | 0.068 | 0.074 | 0.099 |
| MAE | OQMD | 0.020 | 0.038 | 0.045 | 0.070 | 0.065 |
| R^2 | MP | 0.996 | 0.992 | 0.981 | 0.979 | 0.970 |
| R^2 | JARVIS | 0.995 | 0.985 | 0.982 | 0.981 | 0.968 |
| R^2 | OQMD | 0.998 | 0.995 | 0.995 | 0.987 | 0.985 |
- 単純な木ベースのアンサンブルを含む多くのモデルは、化学と構造に基づく大半のOODタスクで一般化が良好である。
- OODテストデータの多くが表現空間の訓練分布内にあり、真の外挿ではなく補間を意味する。
- H、F、O のような非金属は、データ不足だけでなく化学的相違によりOOD性能が劣ることが多く、識別可能な組成バイアスが存在する。
- 構造ベースのOODタスクは化学ベースのものより難易度が高い傾向にあるが、中〜高対称性クラスで依然として強い一般化を示す;三斎晶系はより難しい。
- ニューラルスケーリング則は表現的ID一般化には成立するが、表現的OODタスクではしばしば失敗するか逆方向になる。これにより真のOOD一般化に対するスケーリングの利益は過大評価される可能性がある。
- Density-based domain identification (via UMAP and kernel density) can distinguish representationally ID/OOD points and correlate with prediction errors, though not perfectly.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。