[論文レビュー] Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models
Prometheus 2 は、直接評価とペアワイズランキングの両方を実行するオープンソース evaluator LMs を提供し、異なる評価形式で訓練されたモデルの重みを統合することによって、従来のオープン評価者より人間およびプロプライエタリLMs との一致度を高めている。
Proprietary LMs such as GPT-4 are often employed to assess the quality of responses from various LMs. However, concerns including transparency, controllability, and affordability strongly motivate the development of open-source LMs specialized in evaluations. On the other hand, existing open evaluator LMs exhibit critical shortcomings: 1) they issue scores that significantly diverge from those assigned by humans, and 2) they lack the flexibility to perform both direct assessment and pairwise ranking, the two most prevalent forms of assessment. Additionally, they do not possess the ability to evaluate based on custom evaluation criteria, focusing instead on general attributes like helpfulness and harmlessness. To address these issues, we introduce Prometheus 2, a more powerful evaluator LM than its predecessor that closely mirrors human and GPT-4 judgements. Moreover, it is capable of processing both direct assessment and pair-wise ranking formats grouped with a user-defined evaluation criteria. On four direct assessment benchmarks and four pairwise ranking benchmarks, Prometheus 2 scores the highest correlation and agreement with humans and proprietary LM judges among all tested open evaluator LMs. Our models, code, and data are all publicly available at https://github.com/prometheus-eval/prometheus-eval.
研究の動機と目的
- オープンで透明性のある評価者の開発を促進し、プロプライエタリモデルに頼らずにLMの出力を評価する。
- 直接評価とペアワイズランキングという2つの一般的な評価形式の両方に対応できる統合評価LMを開発する。
- 異なる形式で訓練された評価者を統合するデータと訓練手順(重みのマージ)を提案する。
- 多様な評価基準を備えた細粒度のペアワイズランキングデータセットである Preference Collection を導入する。
- Prometheus 2 が、ベンチマーク全体で人間およびプロプライエタリ評価者と高い相関を達成することを示す。
提案手法
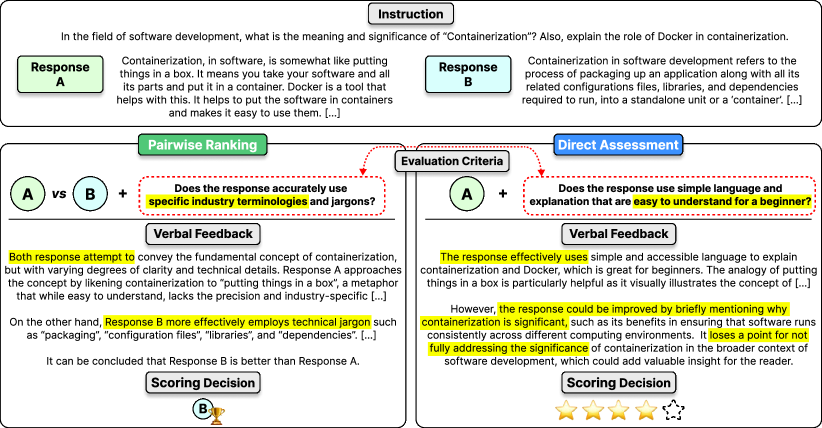
- 直接評価とペアワイズランキング評価パイプラインを、参照回答、口頭フィードバック、評価基準を含む明示的な入力要素とともに形式化する。
- 2つのデータセットを構築する:Feedback Collection(direct assessment)と Preference Collection(1K の評価基準を用いたペアワイズランキング)。
- 異なる形式で訓練された評価者を融合する重みマージ(theta_final = alpha * theta_d + (1 - alpha) * theta_p)を提案し、単一形式および jointly trained のベースラインと比較する。
- 代替のマージ戦略(Task Arithmetic、TIES、DARE)を探索し、線形マージが Prometheus 2 にとって有効であることを示し、最良の跨形式性能のために alpha を調整する。
- ベースラインおよびプロプライエタリLMs と比較して、4つの direct assessment ベンチマークと4つのペアワイズランキングベンチマークで Prometheus 2 を評価する。
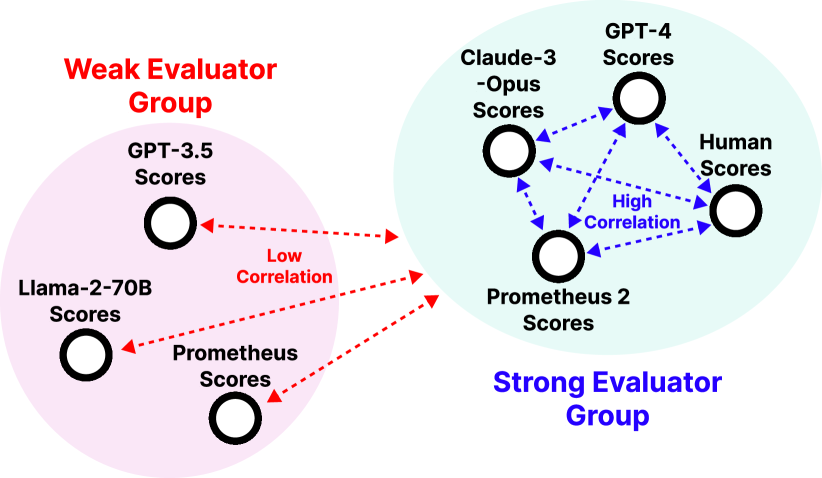
実験結果
リサーチクエスチョン
- RQ1オープンソースの evaluator LM は、direct assessment と pairwise ranking の両方で、人間の判断およびプロプライエタリ LM の判断者と高い整合性を達成できるか。
- RQ2direct assessment と pairwise ranking のそれぞれで別々に訓練された評価者の重みマージは、単一形式または jointly trained された評価者を上回るか。
- RQ3多様で基準豊富なデータセット(Preference Collection)が評価の忠実度向上にどのような役割を果たすか。
- RQ4Prometheus 2 は、インドメイン内・ドメイン外の評価設定でどれだけ堅牢か。
- RQ51つの評価形式での訓練が他方へ正の転移をもたらすか、またその程度はどれくらいか。
主な発見
- Prometheus 2 (7B & 8x7B) は、試験対象のオープン評価者の中で、4つの direct assessment ベンチマークと4つのペアワイズランキングベンチマークの両方で、人間およびプロプライエタリ LMs との相関が最も高い。
- 重みマージは、複数のベンチマークで単一形式および共同訓練済みの評価者を上回り、形式を統合することによる正のタスク転移を示唆する。
- Preference Collection は 1K の評価基準を用いた細粒度の評価を可能にし、ユーザー定義の基準に基づく評価能力を高める。
- Prometheus 2-8x7B は、従来のオープン評価者と比較して、ドメイン外テストでプロプライエタリ LMs との性能ギャップを約半分に縮める。
- Consistency across evaluation formats improves when using merged weights from direct assessment and pairwise ranking formats, demonstrating robustness.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。