[論文レビュー] Prompt Pre-Training with Twenty-Thousand Classes for Open-Vocabulary Visual Recognition
POMP は ImageNet-21K で普遍的なソフトプロンプトを事前訓練し、画像分類、意味的セグメンテーション、物体検出におけるゼロショットのオープン語彙認識を達成します。高い転移性能と効率性の向上を実現します。
This work proposes POMP, a prompt pre-training method for vision-language models. Being memory and computation efficient, POMP enables the learned prompt to condense semantic information for a rich set of visual concepts with over twenty-thousand classes. Once pre-trained, the prompt with a strong transferable ability can be directly plugged into a variety of visual recognition tasks including image classification, semantic segmentation, and object detection, to boost recognition performances in a zero-shot manner. Empirical evaluation shows that POMP achieves state-of-the-art performances on 21 datasets, e.g., 67.0% average accuracy on 10 classification datasets (+3.1% compared to CoOp) and 84.4 hIoU on open-vocabulary Pascal VOC segmentation (+6.9 compared to ZSSeg). Our code is available at https://github.com/amazon-science/prompt-pretraining.
研究の動機と目的
- オープン・ボキャブラリビジュアル認識を動機づけ、タスクを横断して一般化する普遍的で転移可能なプロンプトの必要性を示す。
- 大規模で細粒度なクラス集合に対して、メモリと計算効率の良いプロンプト事前訓練法(POMP)を提案する。
- 事前訓練済みのソフトプロンプトを微調整なしに下流タスクへ組み込み、ゼロショット性能を向上させることを示す。
提案手法
- 多数のクラスを含む ImageNet-21K で事前訓練された普遍的なソフトプロンプト POMP を導入する。
- 各画像から局所対比を用いて K 個の負クラスのサブセットをサンプリングし、メモリと計算を削減する。
- ネガティブサンプリングによるバイアスを補正する適応マージン m を用いた局所補正を適用する(m = -log((K-1)/(N-1)))。
- 事前訓練済みプロンプトを下流タスク(分類、セグメンテーション、検出)へゼロショットで転送する。
- CoOp、CoCoOp、MaPLe、CLIP に基づくゼロショット手法などのベースラインと比較したメモリ/訓練効率と性能を評価する。
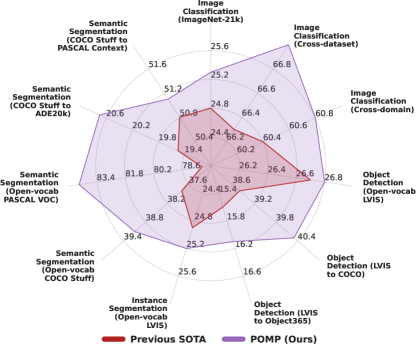
実験結果
リサーチクエスチョン
- RQ1ImageNet-21K で事前訓練された普遍的なソフトプロンプトは、タスク固有の微調整を行わずに、オープンボキャブラリ分類、セグメンテーション、検出へ一般化できるか?
- RQ2局所対比と局所補正によって、>20k クラスでのメモリ効率の良いプロンプト事前訓練を可能にし、転移性能を維持または向上させるか?
- RQ3局所補正の適応マージンは、データセット横断およびドメイン横断の一般化にどのような影響を与えるか?
- RQ4複数データセットにわたる最先端のプロンプトチューニングおよびオープンボキャブラリ手法と比較した、POMP の性能と訓練効率はどうか?
- RQ5POMP プロンプトは、学習済み特徴空間の整列を維持し、オープンボキャブラリ認識の頑健性を高める均一性を改善できるか?
主な発見
- POMP は pre-training 後、ViT-B/16 で ImageNet-21K において最大 25.3% の精度を達成し、メモリ制限は 16 GB 未満。
- 10 件の下流画像分類データセットで、POMP は平均 67.0% の精度を達成し、CoOp を 3.1% 上回る。
- オープンボキャブラリ意味的セグメンテーションでは、POMP は COCO Stuff で 39.1 hIoU、Pascal VOC で 84.4 hIoU を達成し、ZSSeg をそれぞれ 1.3, 6.9 hIoU 上回る。
- オープンボキャブラリ LVIS 物体検出では、POMP は 37.2 AP および 57.9 AP50 に達し、対応設定で Detic をそれぞれ 1.9 AP50 および 0.8 AP50 上回る。
- POMP はデータセット横断およびドメイン横断の転移において強力な性能を示し、タスク間の一般化と頑健性を改善した最先端の精度を達成する。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。