[論文レビュー] PromptBench: A Unified Library for Evaluation of Large Language Models
PromptBench は、プロンプト、データセット、敵対的プロンプト、ダイナミック・プロトコル、分析ツールを横断して LLM を評価する統一的な Python ライブラリです。
The evaluation of large language models (LLMs) is crucial to assess their performance and mitigate potential security risks. In this paper, we introduce PromptBench, a unified library to evaluate LLMs. It consists of several key components that are easily used and extended by researchers: prompt construction, prompt engineering, dataset and model loading, adversarial prompt attack, dynamic evaluation protocols, and analysis tools. PromptBench is designed to be an open, general, and flexible codebase for research purposes that can facilitate original study in creating new benchmarks, deploying downstream applications, and designing new evaluation protocols. The code is available at: https://github.com/microsoft/promptbench and will be continuously supported.
研究の動機と目的
- 能力とセキュリティリスクを評価するために、LLMs の統一的で拡張可能な評価フレームワークの必要性を喚起する。
- 多様なモデル、データセット、プロンプト、および評価プロトコルを支持する、モジュラーで研究志向のライブラリを提供する。
- オープンソースのプラットフォームを通じて、プロンプトエンジニアリング、敵対的プロンプト攻撃、ダイナミック評価の探索を促進する。
提案手法
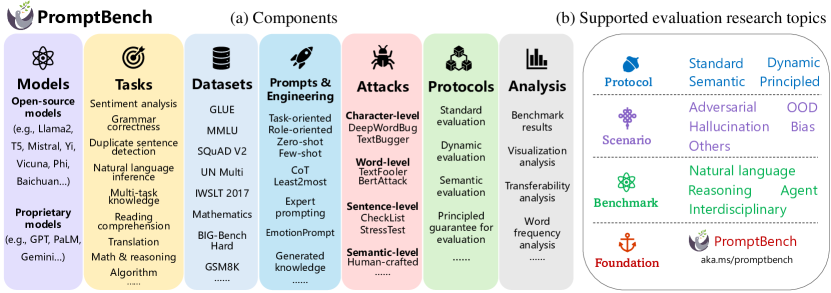
- モデル、データセット、プロンプト、敵対的プロンプト、ダイナミック評価、分析ツールのコンポーネントを備えたモジュラーな Python ライブラリを導入する。
- 容易なパイプライン構築のための統一 LLMModel インターフェースと DatasetLoader を提供する。
- 柔軟な実験のために、4 種類のプロンプトタイプとプロンプト・インターフェース、および6つのプロンプトエンジニアリング手法を組み込む。
- 7 種類の敵対的プロンプト攻撃タイプと、ダイナミック評価およびセマンティック評価を含む複数の評価プロトコルを統合する。
- 結果の解釈と比較のためのリーダーボードと拡張可能な分析ツールを提供する。
- コミュニティの貢献を支援するドキュメントとチュートリアルを備えたオープンソース提供。
実験結果
リサーチクエスチョン
- RQ1統一的で拡張可能なフレームワークは、プロンプト、タスク、プロトコルを横断した多様な LLM の包括的評価をどのように効率化できるか?
- RQ2標準化されたライブラリ内で、プロンプトエンジニアリングと敵対的プロンプトは LLM の堅牢性評価にどのような役割を果たすか?
- RQ3ダイナミック評価プロトコルとセマンティック評価プロトコルは、静的推論設定よりも堅牢なベンチマークを提供できるか?
- RQ4PromptBench は、モデルとデータセットを横断した評価パイプラインの構築、共有、比較を研究者にどれだけサポートするか?
主な発見
- PromptBench は、モジュラーなパイプラインで幅広いモデル、データセット、タスク、プロンプト、および評価プロトコルをサポートする。
- このライブラリには、堅牢性とプロンプトの有効性を研究するための敵対的プロンプト攻撃とプロンプトエンジニアリング技術が含まれている。
- データ汚染と直接推論を超える堅牢性に対応するため、ダイナミック評価とセマンティック評価の機能が統合されている。
- 3 つのリーダーボード(敵対的プロンプト攻撃、プロンプトエンジニアリング、ダイナミック評価)により結果の比較が容易になる。
- このフレームワークは、オープンソースのコードとドキュメントを通じた研究志向の拡張性とオープンな協力を重視している。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。