[論文レビュー] Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution
Promptbreeder は、LLM によって駆動される自己参照的な進化ループを用いて、ドメイン特化のプロンプトとその変異戦略を自動的に進化させ、いくつかの最先端プロンプト手法を、計算・常識・ヘイトスピーチ課題でパラメータの更新なしに上回る。
Popular prompt strategies like Chain-of-Thought Prompting can dramatically improve the reasoning abilities of Large Language Models (LLMs) in various domains. However, such hand-crafted prompt-strategies are often sub-optimal. In this paper, we present Promptbreeder, a general-purpose self-referential self-improvement mechanism that evolves and adapts prompts for a given domain. Driven by an LLM, Promptbreeder mutates a population of task-prompts, and subsequently evaluates them for fitness on a training set. Crucially, the mutation of these task-prompts is governed by mutation-prompts that the LLM generates and improves throughout evolution in a self-referential way. That is, Promptbreeder is not just improving task-prompts, but it is also improving the mutationprompts that improve these task-prompts. Promptbreeder outperforms state-of-the-art prompt strategies such as Chain-of-Thought and Plan-and-Solve Prompting on commonly used arithmetic and commonsense reasoning benchmarks. Furthermore, Promptbreeder is able to evolve intricate task-prompts for the challenging problem of hate speech classification.
研究の動機と目的
- モデルのパラメータを変更せずに、自動化されたドメイン適応型プロンプト設計を動機づけ、可能にする。
- プロンプトとその変異戦略が共進化する、自己参照的な進化メカニズムを提案する。
- プロンプトを進化させることが、算術、常識推論、ヘイトスピーチ課題において卓越した性能を生み出すことを示す。
- 自己参照的要素が性能向上に寄与する部分を調査する。
提案手法
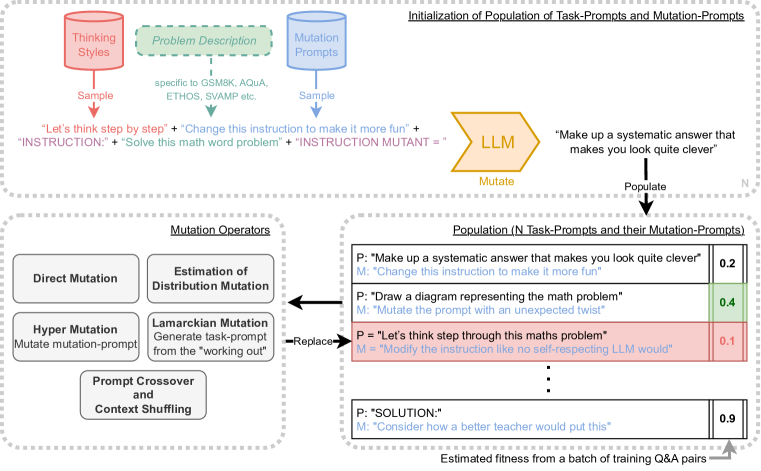
- それぞれが1つ以上のタスクプロンプトと関連する変異プロンプトを含む、進化ユニットの集団を維持する。
- 変異演算子として LLM を使用する: P' = LLM(M + P) ただし M は変異プロンプト、P はタスクプロンプト。
- 複数世代にわたって二分トーナメント遺伝アルゴリズムを用い、タスクプロンプトと変異プロンプトの両方を進化させる。
- 多様性と自己改善を促進するため、ゼロ次・一次プロンプト、分布推定、系統ベース、ハイパーミュテーション、ラマルキアン変異、クロスオーバー/コンテキストシャッフルを含む9つの変異演算子を適用する。
- 問題説明と変異プロンプトおよび思考スタイルを連結して、さまざまな種プロンプトを生み出すことでプロンプトを初期化する。
- そのドメインの訓練セットから100のQ&Aペアをサンプリングして、プロンプト駆動の性能を測定することで適合度を評価する。
実験結果
リサーチクエスチョン
- RQ1自己参照的なプロンプト進化は、算術・常識・倫理のベンチマークにおけるLLM推論を改善できますか?
- RQ2変異プロンプトとタスクプロンプトを共に進化させることは、タスクプロンプトだけを進化させるよりも、よりドメイン適応的な戦略を生み出しますか?
- RQ3多様な変異演算子とハイパーミュテーションが、プロンプトの質と性能に与える影響はどの程度ですか?
- RQ4パラメータの更新なしに、より大規模なLLMでプロンプトによる自己改善はスケーラブルですか?
主な発見
- PB は複数のベンチマークで Chain-of-Thought や Plan-and-Solve などの最先端のプロンプト戦略を上回る。
- PB は強力なゼロショット・少数ショット結果を達成し、基盤となる LLM として PaLM 2-L を使用した場合にも改善を含む。
- PB は、手順と記法を詳述する GSM8K 風プロンプトのような、複雑なドメイン特化プロンプトを進化させる。
- アブレーション分析は、自己参照演算子が数学データセットとETHOS ヘイトスピーチ分類の両方で有益に寄与することを示す。
- 9つの変異クラスすべてが性能に寄与し、ハイパーミュテーションが自己参照的改善を可能にする。
- PB はヘイトスピーチ分類における解決策を意識したプロンプト進化を示し、手設計プロンプトを上回る。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。