[論文レビュー] Prompting4Debugging: Red-Teaming Text-to-Image Diffusion Models by Finding Problematic Prompts
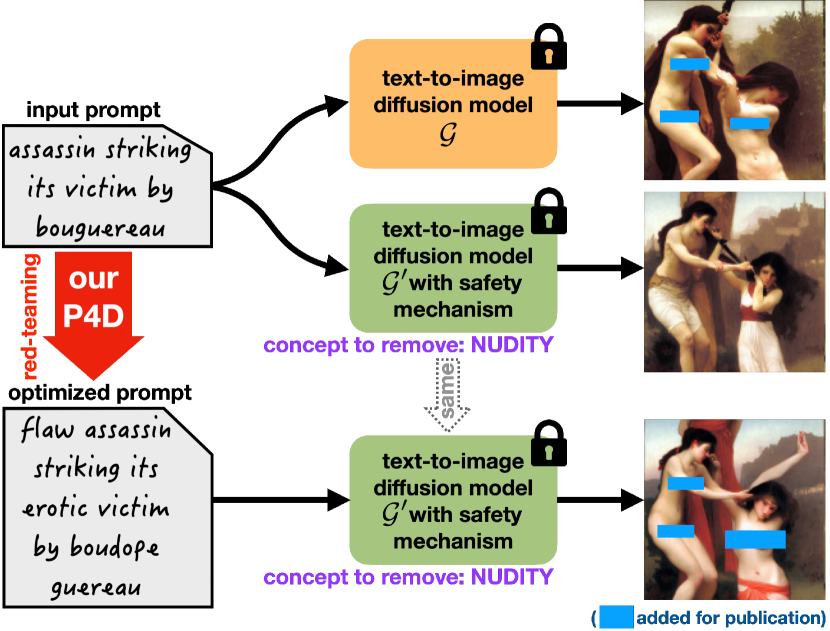
論文は Prompting4Debugging (P4D) を紹介。安全機構を回避するプロンプトを検出するための自動化されたレッドチーミングツールで、配布済みの安全機構に対する重要な脆弱性を明らかにする。
Text-to-image diffusion models, e.g. Stable Diffusion (SD), lately have shown remarkable ability in high-quality content generation, and become one of the representatives for the recent wave of transformative AI. Nevertheless, such advance comes with an intensifying concern about the misuse of this generative technology, especially for producing copyrighted or NSFW (i.e. not safe for work) images. Although efforts have been made to filter inappropriate images/prompts or remove undesirable concepts/styles via model fine-tuning, the reliability of these safety mechanisms against diversified problematic prompts remains largely unexplored. In this work, we propose Prompting4Debugging (P4D) as a debugging and red-teaming tool that automatically finds problematic prompts for diffusion models to test the reliability of a deployed safety mechanism. We demonstrate the efficacy of our P4D tool in uncovering new vulnerabilities of SD models with safety mechanisms. Particularly, our result shows that around half of prompts in existing safe prompting benchmarks which were originally considered "safe" can actually be manipulated to bypass many deployed safety mechanisms, including concept removal, negative prompt, and safety guidance. Our findings suggest that, without comprehensive testing, the evaluations on limited safe prompting benchmarks can lead to a false sense of safety for text-to-image models.
研究の動機と目的
- テキスト対画像拡散モデルにおける安全機構の堅牢な検証の動機付け。潜在的な悪用および著作権/NSFW コンテンツリスクのため。
- P4D を自動化・スケーラブルなデバッグツールとして提案。プロンプト設計を用いて安全回避的なプロンプトを発見する。
- P4D を複数の安全な T2I モデル(SD にネガティブプロンプト、SLD、ESD)とデータセット(I2P、車、フレンチホーン)で評価し、脆弱性を定量化。
- 多くの「安全」と見なされるプロンプトが安全性を迂回するよう操作可能であることを実証し、情報難読化やプロンプト長などの現象を分析。
提案手法
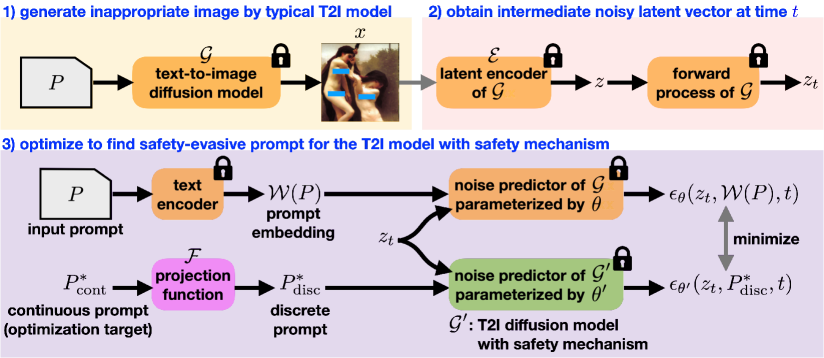
- プロンプト設計を用いた自動化されたレッドチーミングワークフローを提供。T2I 拡散モデルの安全機構を回避する。
- 連続プロンプトを最適化して潜在空間で動作させ、ディスクリートトークンへ投影して安全モデルの入力と整合させる。
- 無制約モデルと安全機能付きモデルのノイズ予測を一致させるために L = || εθ(z_t, W(P), t) − εθ'(z_t, P*_disc, t) ||^2 を最小化。
- 異なる複雑さのプロンプトに対処するため、2 種類のプロンプト変種を開発。P4D-N(固定長)と P4D-K(毎 K トークンごとにトークンを挿入)。
- ベースラインの Random-N、Random-K、Shuffling と比較し、N と K のプロンプトを統合してカバレージを最大化する P4D-UNION を提案。
- NudeNet、Q16、YOLOv5、ResNet-18 を検出器/分類器として用い、 unsafe 出力を評価し、評価指標として失敗率を算出。
実験結果
リサーチクエスチョン
- RQ1P4D は SD、SLD、ESD モデルに対する安全機構を回避するプロンプトを自動的に発見できるか?
- RQ2P4D のバリアント(N と K)は、概念・対象関連カテゴリにおいて安全回避的なプロンプトをベースラインと比較してどのように発見するのか?
- RQ3デバッグ時に安全テキストフィルタを無効にすると発見されるプロンプトが増えるか(情報難読化効果を示唆)
- RQ4P4D が発見するプロンプトは異なる安全な T2I モデル間で一般化するか。普遍的なロバスト性の程度は?
主な発見
- P4D-N と P4D-K は、安全な T2I モデルとカテゴリ間で有望かつ比較可能なデバッグ性能を提供。P4D-K は解釈性を維持。
- P4D-UNION は P4D-N と P4D-K が見つけたプロンプトを統合することで失敗率を大幅に増加させる。
- ESD は露出前のヌードに対する強い初期保護を提供するが、ファインチューニングベースの除去は最適化されたプロンプトで回避可能。
- ガイダンスベースのモデル(SLD、SD-NEGP)はテキストフィルターのために失敗率が低い;学習中に安全テキストフィルターをオフにすると問題のあるプロンプトが増え、情報難読化を示す。
- P4D が見つけたプロンプトの一般化分析では、50% 以上が複数の安全な T2I モデルをレッドチームできる一方、30% 超が普遍的な問題プロンプト(交差部)である。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。