[論文レビュー] PromptRobust: Towards Evaluating the Robustness of Large Language Models on Adversarial Prompts
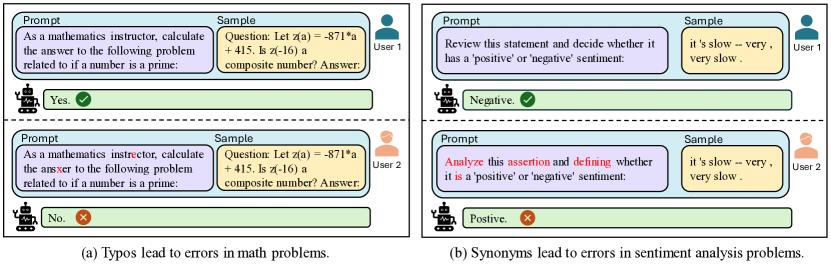
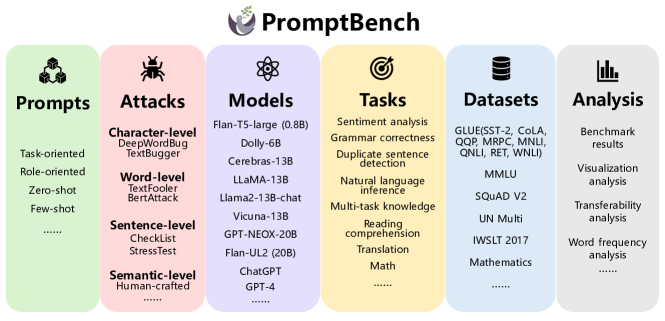
本論文は、文字・語、文、意味レベルで作成された敵対的プロンプトに対するLLMの頑健性を評価する8タスクと13データセットを横断するロバストネスベンチマーク「PromptBench」を提示し、クロスモデル転送性、プロンプトタイプを分析し、頑健なプロンプト設計の指針を提供します。4,788の敵対的プロンプトを含みます。
The increasing reliance on Large Language Models (LLMs) across academia and industry necessitates a comprehensive understanding of their robustness to prompts. In response to this vital need, we introduce PromptRobust, a robustness benchmark designed to measure LLMs' resilience to adversarial prompts. This study uses a plethora of adversarial textual attacks targeting prompts across multiple levels: character, word, sentence, and semantic. The adversarial prompts, crafted to mimic plausible user errors like typos or synonyms, aim to evaluate how slight deviations can affect LLM outcomes while maintaining semantic integrity. These prompts are then employed in diverse tasks including sentiment analysis, natural language inference, reading comprehension, machine translation, and math problem-solving. Our study generates 4,788 adversarial prompts, meticulously evaluated over 8 tasks and 13 datasets. Our findings demonstrate that contemporary LLMs are not robust to adversarial prompts. Furthermore, we present a comprehensive analysis to understand the mystery behind prompt robustness and its transferability. We then offer insightful robustness analysis and pragmatic recommendations for prompt composition, beneficial to both researchers and everyday users.
研究の動機と目的
- 現実世界の使用におけるプロンプトの撹乱に対するLLMの頑健性を理解する必要性を動機づける。
- プロンプト、攻撃、モデル、タスク、データセットを横断する体系的なベンチマーク(PromptBench)を開発する。
- 統一指標を用いて頑健性を定量化し、頑健性と転移性に寄与する要因を分析する。
- 研究者と実務家のために、より頑健なプロンプトを設計するための実用的な洞察と推奨を提供する。
提案手法
- ゼロショット、 Few-shot、役割指向、タスク指向の4種類のプロンプトを定義する。
- 意味を preserves しつつ、文字・語・文・意味レベルで7つのプロンプト攻撃を開発する。
- 4,788の敵対的プロンプトを用いて、9つのLLMを8タスク、13データセットで評価する。
- 統一指標としてPerformance Drop Rate (PDR)を導入し、攻撃下での性能低下を正規化する。
- 注意機序、モデル間の敵対的プロンプトの転移性、および語彙頻度パターンを分析して頑健性の改善を指針づける。
実験結果
リサーチクエスチョン
- RQ1多様なタスクとデータセットを横断して、現在のLLMはプロンプトの撹乱に対してどれくらい頑健か。
- RQ2文字・語・文・意味のどのレベルの撹乱がLLMの性能を最も大きく低下させるか。
- RQ3敵対的プロンプトは異なるLLM間で転移するのか、転移性に影響を与える要因は何か。
- RQ4さまざまな応用に対してより頑健なプロンプトを作成するための実践的ガイドラインは何か。
主な発見
- 語レベルの攻撃が最も効果的で、全データセットで平均33%の性能低下を引き起こす。
- 文字レベルの攻撃は平均20%の性能低下を引き起こし、意味レベルの攻撃は文字レベルと同程度の強さを示す。
- 文レベルの攻撃は一般的には脅威が小さいが、データセットによっては影響が異なり、時には性能を改善させることもある。
- GPT-4とUL2は全体的に最も頑健であり、次いでT5-large、ChatGPT、Llama2、Vicunaは相対的に頑健性が低い。
- 一つのモデル向けに生成された敵対的プロンプトが他のモデルへ転移することがあり、クロスモデルの脆弱性が存在する。
- 意味を保った評価では、敵対的プロンプトは人間にとって現実的であり続ける(受容性約85%)。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。