[論文レビュー] ProtChatGPT: Towards Understanding Proteins with Large Language Models
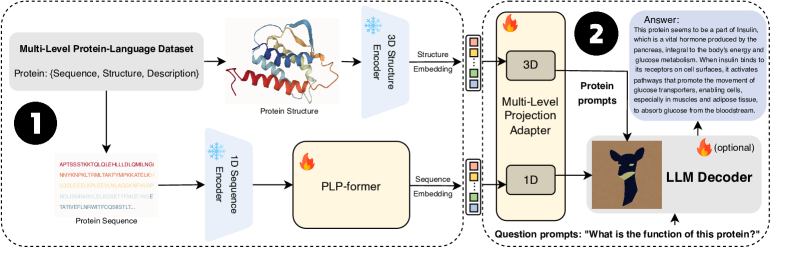
ProtChatGPTは、PLP-formerと多層アダプターを介して凍結されたLLMとタンパク質配列および構造埋め込みを整列させるChatGPT風のシステムで、自然言語クエリを通じたインタラクティブなタンパク質理解と設計を可能にします。
Protein research is crucial in various fundamental disciplines, but understanding their intricate structure-function relationships remains challenging. Recent Large Language Models (LLMs) have made significant strides in comprehending task-specific knowledge, suggesting the potential for ChatGPT-like systems specialized in protein to facilitate basic research. In this work, we introduce ProtChatGPT, which aims at learning and understanding protein structures via natural languages. ProtChatGPT enables users to upload proteins, ask questions, and engage in interactive conversations to produce comprehensive answers. The system comprises protein encoders, a Protein-Language Pertaining Transformer (PLP-former), a projection adapter, and an LLM. The protein first undergoes protein encoders and PLP-former to produce protein embeddings, which are then projected by the adapter to conform with the LLM. The LLM finally combines user questions with projected embeddings to generate informative answers. Experiments show that ProtChatGPT can produce promising responses to proteins and their corresponding questions. We hope that ProtChatGPT could form the basis for further exploration and application in protein research. Code and our pre-trained model will be publicly available.
研究の動機と目的
- タンパク質データと言語のモダリティ幅をQ&Aと設計タスクのために埋める。
- 事前学習済みのタンパク質エンコーダとLLMを活用して、完全なエンドツーエンドのファインチューニングを行わずにインタラクティブなタンパク質会話を実現する。
- タンパク質表現をテキスト記述と整列させるための二段階トレーニング設定(PLP-formerと多層アダプター)を導入する。
- タンパク質理解と設計タスクにおいてシステムを実演し、構成要素の影響を分析する。
提案手法
- シーケンスと構造の埋め込みを得るために二つの事前学習済みタンパク質エンコーダを使用(1D配列にはESM-1b、3D構造にはESM-IF1)。
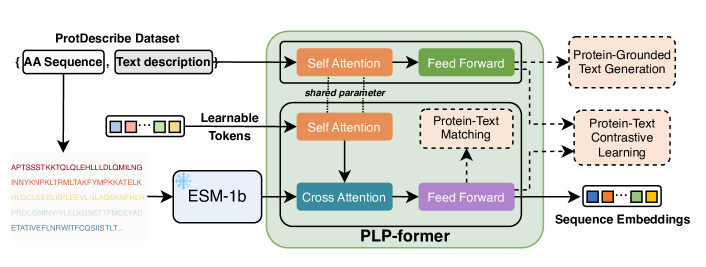
- LLMを凍結したままテキスト記述とタンパク質埋め込みを整列させるPLP-formerを導入する。
- 整列したタンパク質埋め込みをLLMと互換性のあるプロンプトへ翻訳する多層プロジェクションアダプターを開発する。
- タンパク質記述とタンパク質テキスト生成目的を用いた二段階のトレーニング制度でPLP-formerとアダプターを微調整する。
- LLMデコーダとしてVicuna-13bを用い、タンパク質プロンプトをユーザの質問プロンプトと連結して生成を行う。
実験結果
リサーチクエスチョン
- RQ1凍結されたLLMを効果的に導いて、整列された多層タンパク質埋め込みを用いてタンパク質関連の質問に答えられるか。
- RQ2配列のみのエンコードと配列+構造のエンコードが、タンパク質からテキストへの整列の質と生成された説明にどのように影響するか。
- RQ3PLP-formerと多層アダプターが生成されるタンパク質記述の意味的品質に与える影響は何か。
- RQ4ProtChatGPTは自然言語の対話を通じてタンパク質の理解と設計タスクの両方をサポートできるか。
主な発見
| Variant | BLEU-1 | BLEU-4 | ROUGE-L | METEOR | CIDEr | SPICE | PubMed BERTScore |
|---|---|---|---|---|---|---|---|
| w/o structure | 0.457 | 0.311 | 0.405 | 0.237 | 0.504 | 0.231 | 0.335 |
| w/o PLP-former | 0.581 | 0.352 | 0.463 | 0.270 | 0.572 | 0.276 | 0.421 |
| ProtChatGPT | 0.610 | 0.394 | 0.489 | 0.291 | 0.638 | 0.316 | 0.457 |
- ProtChatGPTは、構造やPLP-former要素を欠くアブレーションよりも、複数の指標で意味的評価スコアが高い。
- 二段階トレーニング(PLP-formerとアダプター)は、タンパク質表現をLLMと効果的に整列させ、情報性の高い応答を実現する。
- 定性的な対話では、ProtChatGPTがタンパク質の意味、機能、応用、設計上の考慮事項や変異を含めて議論できることを示す。
- ケーススタディでは、相同タンパク質の区別や相互排他的な機能の文脈的プロンプトによる扱いを実証。
- 1000組のテストタンパク質ペアの定量的テストにより、構造とPLP-formerの両方が性能にとって重要であることを示唆。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。