[論文レビュー] Proto-CLIP: Vision-Language Prototypical Network for Few-Shot Learning
Proto-CLIP は凍結された CLIP バックボーンからの画像プロトタイプとテキストプロトタイプを組み合わせ、適応器とメモリを学習して画像プロトタイプとテキストプロトタイプを整合させ、少数ショット分類を改善します。
We propose a novel framework for few-shot learning by leveraging large-scale vision-language models such as CLIP. Motivated by unimodal prototypical networks for few-shot learning, we introduce Proto-CLIP which utilizes image prototypes and text prototypes for few-shot learning. Specifically, Proto-CLIP adapts the image and text encoder embeddings from CLIP in a joint fashion using few-shot examples. The embeddings from the two encoders are used to compute the respective prototypes of image classes for classification. During adaptation, we propose aligning the image and text prototypes of the corresponding classes. Such alignment is beneficial for few-shot classification due to the reinforced contributions from both types of prototypes. Proto-CLIP has both training-free and fine-tuned variants. We demonstrate the effectiveness of our method by conducting experiments on benchmark datasets for few-shot learning, as well as in the real world for robot perception. The project page is available at https://irvlutd.github.io/Proto-CLIP
研究の動機と目的
- 大規模なビジョン-ランゲージモデル(CLIP)を活用して robotics および一般的なビジョンタスクにおいてわずかな例から新規オブジェクトを認識することを目的とした few-shot 学習の動機付け。
- CLIP エンコーダを few-shot データを用いて適応させる共同の画像-テキストプロトタイプフレームワークを提案。
- クラスごとに画像プロトタイプとテキストプロトタイプを整合させて few-shot 分類を改善。
- Proto-CLIP を標準的な few-shot ベンチマークおよび FewSOL で評価し、実世界のロボット知覚実験を含む。
提案手法
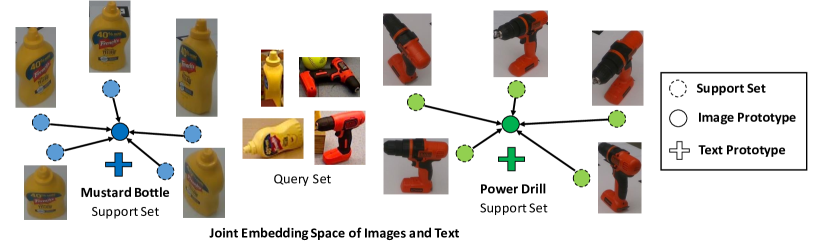
- クラスプロトタイプを形成するために CLIP の画像エンコーダとテキストエンコーダの両方を使用: 画像プロトタイプ c_k^x およびテキストプロトタイプ c_k^y は適応化された埋め込みから計算。
- 凍結された CLIP エンコーダを保ちながら、学習可能な画像メモリ、テキストメモリ、クエリ画像に適用されるアダプターネットワークを用いて CLIP を適応させる。
- クラス条件付き確率を画像ベースの予測とテキストベースの予測の凸結合として計算: P(y=k|x^q,S) = alpha P(y=k|x^q,S_x) + (1-alpha) P(y=k|x^q,S_y)。
- プロトタイプは埋め込みの平均として学習される: c_k^x = (1/M_k) sum φ_Image(x_i^s) および c_k^y = (1/Ṁ_k) sum φ_Text(Prompt_j(y_i^s=k))。
- 共同損失で訓練: クエリ分類の L1 に対し、情報ノイズ対コンテスト損失(InfoNCE)(L2 および L3)で画像プロトタイプとテキストプロトタイプを整合。
- 訓練時には S(サポート)と Q(クエリ)セットは通常 CLIP ベースの few-shot 手法と同じで、画像/テキストエンコーダは凍結され、メモリとアダプタのみ学習。
実験結果
リサーチクエスチョン
- RQ1CLIP の画像エンコーダとテキストエンコーダの共同適応は、単一モードのプロトタイプ手法と比較して few-shot 分類を改善できるか。
- RQ2InfoNCE 目的の下で画像プロトタイプとテキストプロトタイプを整合させることは、few-shot 設定における新規クラスの認識に有益か。
- RQ3学習可能な画像/テキストメモリと異なるアダプタ設計は、さまざまなデータセットで few-shot 性能にどのような影響を与えるか。
- RQ4クエリのデータ拡張とメモリベースの適応の間のトレードオフは Proto-CLIP においてどうなるか。
主な発見
- Proto-CLIP は zero-shot CLIP および複数の CLIP ベースの few-shot ベースラインを、ショット数が増えるほど利得が拡大する形で一貫して改善。
- 対照的な損失(L2、L3)による画像プロトタイプとテキストプロトタイプの整合は性能に利をもたらし、共同埋め込み仮説を裏付け。
- 学習可能な画像/テキストメモリとアダプタを用いると、CLIP フィーチャーをそのまま使用するより適応が向上し、アダプターの選択(MLP 対畳み込み)はデータセットに依存する。
- バックボーンの選択(例:CLIP ViT 対 ResNet)は結果に影響を与え、ビジョン-ランゲージのバックボーンは通常 few-shot でより強力な性能を示す。
- 訓練時にクエリ拡張を適用する Proto-CLIP の変種(Q^T)は、特に高ショット設定で非拡張版より性能が上回ることが多い。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。