[論文レビュー] ProxylessNAS: Direct Neural Architecture Search on Target Task and\n Hardware
ProxylessNAS はターゲットタスクとハードウェア上で直接ニューラルアーキテクチャを学習し、メモリと計算量を削減して、大規模な探索空間とハードウェア認識の特化をプロキシタスクなしで実現する。
Neural architecture search (NAS) has a great impact by automatically\ndesigning effective neural network architectures. However, the prohibitive\ncomputational demand of conventional NAS algorithms (e.g. $10^4$ GPU hours)\nmakes it difficult to \\emph{directly} search the architectures on large-scale\ntasks (e.g. ImageNet). Differentiable NAS can reduce the cost of GPU hours via\na continuous representation of network architecture but suffers from the high\nGPU memory consumption issue (grow linearly w.r.t. candidate set size). As a\nresult, they need to utilize~\\emph{proxy} tasks, such as training on a smaller\ndataset, or learning with only a few blocks, or training just for a few epochs.\nThese architectures optimized on proxy tasks are not guaranteed to be optimal\non the target task. In this paper, we present \\emph{ProxylessNAS} that can\n\\emph{directly} learn the architectures for large-scale target tasks and target\nhardware platforms. We address the high memory consumption issue of\ndifferentiable NAS and reduce the computational cost (GPU hours and GPU memory)\nto the same level of regular training while still allowing a large candidate\nset. Experiments on CIFAR-10 and ImageNet demonstrate the effectiveness of\ndirectness and specialization. On CIFAR-10, our model achieves 2.08\\% test\nerror with only 5.7M parameters, better than the previous state-of-the-art\narchitecture AmoebaNet-B, while using 6$\\times$ fewer parameters. On ImageNet,\nour model achieves 3.1\\% better top-1 accuracy than MobileNetV2, while being\n1.2$\\times$ faster with measured GPU latency. We also apply ProxylessNAS to\nspecialize neural architectures for hardware with direct hardware metrics (e.g.\nlatency) and provide insights for efficient CNN architecture design.\n
研究の動機と目的
- proxy tasks を排除して大規模データセット(例:ImageNet)上で直接最適化する NAS を動機付ける。
- ブロックの繰り返しを避けつつ大規模な探索空間を有効にし、メモリと計算量を通常のトレーニング水準へ削減する。
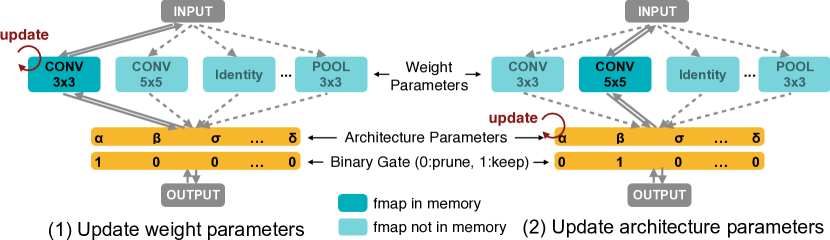
- メモリ使用量を抑えるために2値化されたアーキテクチャパラメータによるパスレベルの剪定を導入する。
- 微分不可能なハードウェア指標(例: レイテンシ)を、微分可能なレイテンシモデリングやREINFORCEベースの方法で扱う。
- レイテンシ認識の目的関数を用いて、GPU、CPU、モバイルなど異なるハードウェア向けのアーキテクチャ特化を実証する。
提案手法
- すべての候補パスを混合演算として含む過パラメータ化ネットワークを構築する。
- アーキテクチャパラメータを2値化して実行時に1つのパスだけを活性化し、メモリを標準的なトレーニング水準へ削減する。
- アーキテクチャパラメータを凍結した状態で重みパラメータを訓練し、2パスサンプリングを介して勾配ベースの推定(BinaryConnectに触発)を用いてアーキテクチャパラメータを更新し、メモリを小さく保つ。
- パスごとのレイテンシを予測して、それを期待値として損失に加える微分可能な正則化項としてレイテンシをモデル化し、レイテンシの重み λ2 を加える。
- 微分不可能なレイテンシ目的を用いる場合に、アーキテクチャパラメータの代替的なREINFORCEベースの更新を提供する。
- CIFAR-10とImageNetで評価し、モバイル、GPU、CPU向けのハードウェア認識探索も含める。

実験結果
リサーチクエスチョン
- RQ1NAS は proxy タスクなしで大規模タスク(例:ImageNet)上で直接アーキテクチャを最適化できるか?
- RQ2すべてのブロックを学習させること(繰り返しモチーフの制限なし)は性能と効率を改善するか?
- RQ3大規模パスベースの探索空間を探索しつつ、メモリと計算量を通常のトレーニング水準に保てるか?
- RQ4レイテンシを微分可能な目的関数としてどれほど効果的に組み込み、ハードウェア認識アーキテクチャを生み出せるか?
- RQ5GPU、CPU、モバイル端末でハードウェア特化アーキテクチャは異なるか、NAS はこれらの違いを捉えられるか?
主な発見
| モデル | パラメータ | テスト誤差(%) |
|---|---|---|
| Proxyless-G (ours) + c/o | 5.7M | 2.08 |
| Proxyless-R (ours) + c/o | 5.7M | 2.30 |
- CIFAR-10 では、ProxylessNAS は 2.08% のテスト誤差で 5.7M パラメータを達成し、約6倍のパラメータを持つ AmoebaNet-B を上回る。
- ImageNet では、Proxyless-G が top-1 精度 75.1%、MobileNetV2 より 1.2× 速いレイテンシ、従来手法より 200× 低い探索コストを達成。
- Proxyless-G (mobile) は top-1 74.6%、モバイルレイテンシ 78 ms で、同等のレイテンシ制約下で MobileNetV2 を上回る。
- Proxyless-NAS は GPU、CPU、モバイル向けのハードウェア特化アーキテクチャを見つけ、プラットフォームごとに異なるアーキテクチャ特性を示す(例:GPU: より浅く広い;CPU: 深く狭い)。
- レイテンシ認識探索(レイテンシ正則化付き)は、レイテンシを素通りする方法より精度-レイテンシのトレードオフが良い。
- この手法はパスの2値化によりメモリを削減し、ブロックを繰り返さずに大規模なアーキテクチャ探索空間を可能にする。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。