[論文レビュー] Pushing Mixture of Experts to the Limit: Extremely Parameter Efficient MoE for Instruction Tuning
この研究は、軽量な adapters(MoV と MoLORA)を用いて全エキスパートを置換することで、非常にパラメータ効率の高い Mixture of Experts(MoE)を提案し、11B規模のモデルと未見タスクにおいて、全ファインチューニングの性能に匹敵するかそれを上回りつつ、パラメータの1%未満しか更新しないことを示します。
The Mixture of Experts (MoE) is a widely known neural architecture where an ensemble of specialized sub-models optimizes overall performance with a constant computational cost. However, conventional MoEs pose challenges at scale due to the need to store all experts in memory. In this paper, we push MoE to the limit. We propose extremely parameter-efficient MoE by uniquely combining MoE architecture with lightweight experts.Our MoE architecture outperforms standard parameter-efficient fine-tuning (PEFT) methods and is on par with full fine-tuning by only updating the lightweight experts -- less than 1% of an 11B parameters model. Furthermore, our method generalizes to unseen tasks as it does not depend on any prior task knowledge. Our research underscores the versatility of the mixture of experts architecture, showcasing its ability to deliver robust performance even when subjected to rigorous parameter constraints. Our code used in all the experiments is publicly available here: https://github.com/for-ai/parameter-efficient-moe.
研究の動機と目的
- Mixture of Experts に基づく極端なパラメータ制約下での指示ファインチューニングを動機づけ、実現すること。
- 最小限の trainable parameters を使用する軽量 MoE アーキテクチャを開発すること。
- 未知のタスクに対して複数のモデルサイズで、パラメータ効率の高い MoEs が全ファインチューニングと同等以上の性能を発揮できることを示すこと。
- MoV/MoLORA の頑健性とスケーラビリティを 770M–11B ベースモデルおよび 12 データセットにわたって実証すること。
提案手法
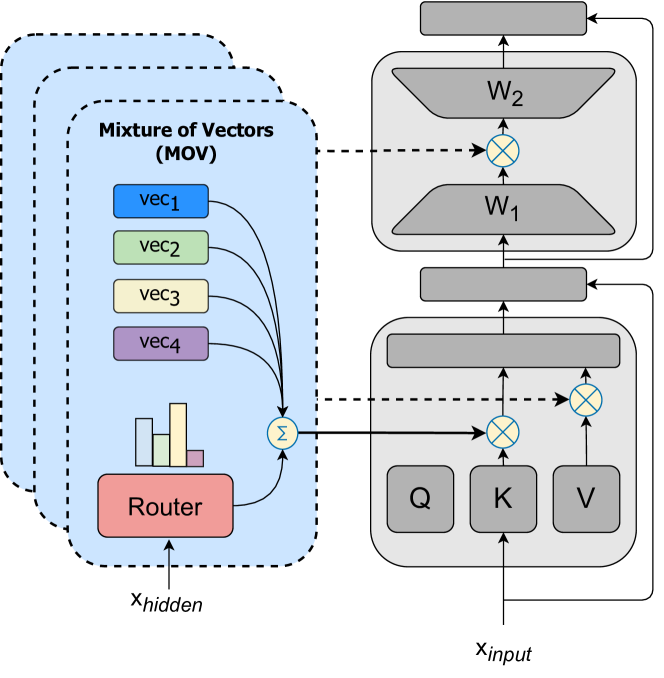
- 各 MoE エキスパートを軽量な PEFT アダプターで置換して、Mixture of Vectors (MoV) および Mixture of LORA (MoLORA) を提案する。
- ルータを用いてエキスパート出力のソフトマージを計算した後、PEFT 変換を適用する。
- 軽量なエキスパートとして (IA)3 ベクトルと LORA アダプターを用いる。
- 3B–11B T5 モデルに対して全ファインチューニングおよび標準の PEFT ベースライン(IA)3 と LORA とを比較する。
- ルーティング入力(トークン vs 文 embedding)、ルーティング戦略(ソフト vs 離散)、エキスパート数、ハイパーパラメータの組み合わせで広範なアブレーションを実施する。
- Adafactor オプティマィザと特定の学習設定を用い、P3 プロンプトと未見タスク8件で指示チューニングの極めてパラメータ効率的なファインチューニングを採用する。
- ゼロショットの結果を報告し、モデルサイズとエキスパート数の増加が性能に与える影響を分析する。

実験結果
リサーチクエスチョン
- RQ1極端なパラメータ効率 MoEs(MoV/MoLORA)が、未知タスクに対するゼロショット性能でフルファインチューニングと比較して競合できるか。
- RQ2パラメータ予算が厳しい場合、エキスパート数とルーティング戦略は性能にどう影響するか。
- RQ3この設定でトークンベースのルーティングとソフトマージは、文embeddingや離散ルーティングより良い一般化を提供するか。
- RQ4モデルサイズ(770M–11B)は MoV/MoLORA の有効性に対して標準的な PEFT 手法と比べてどのように影響するか。
主な発見
| モデル | % パラメータ | ANLI | CB | RTE | WSC | WIC | Copa | WNG | 平均 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Full-FT | 100% | 33.46 | 50.0 | 64.08 | 64.42 | 50.39 | 74.92 | 50.51 | 27.51 | 51.91 |
| T0-3B (Sanh et al., 2022) | 100% | 41.08 | 80.36 | 76.17 | 53.37 | 53.92 | 88.94 | 57.46 | 29.19 | 60.06 |
| T0-3B (our replication) | 100% | 41.08 | 80.36 | 76.17 | 53.37 | 53.92 | 88.94 | 57.46 | 29.19 | 60.06 |
| (IA)3 | 0.018% | 34.08 | 50.0 | 66.43 | 56.25 | 55.41 | 79.08 | 52.09 | 29.91 | 52.90 |
| LORA | 0.3% | 37.5 | 75.57 | 73.53 | 61.02 | 51.25 | 83.6 | 54.33 | 25.32 | 57.51 |
| MoV-10 | 0.32% | 38.92 | 75.0 | 78.88 | 62.5 | 52.19 | 85.77 | 55.96 | 30.24 | 59.93 |
| MoV-30 | 0.68% | 38.7 | 78.57 | 80.87 | 63.46 | 51.1 | 87.25 | 56.27 | 28.63 | 60.61 |
| MoV-60 | 1.22% | 38.83 | 76.79 | 74.55 | 60.1 | 52.66 | 89.79 | 55.49 | 30.47 | 59.83 |
| MoLORA-10 | 3.18% | 38.5 | 78.57 | 78.16 | 63.46 | 50.86 | 86.5 | 55.41 | 26.72 | 59.77 |
| MoLORA-15 | 4.69% | 40.0 | 80.36 | 80.51 | 62.98 | 50.86 | 89.0 | 55.33 | 27.3 | 60.79 |
- MoV と MoLORA は、3B–11B モデルでパラメータの1%未満を更新するだけで全ファインチューニングと同等の性能を達成する。
- 3B で (IA)3 を超える未知タスク性能を MoV が 30 エキスパートで 14.57%、11B モデルサイズで 8.39% 向上。
- MoV-60 (60 エキスパート) は ~1.3% 更新パラメータで、3B および 11B のスケールで全ファインチューニングの性能に密接に近づく。
- ソフトマージング・ルーティングは、極めてパラメータ効率的な MoE で離散 top-k ルーティングよりも優れた性能を示す。
- トークンルーティング(トークン embedding 使用)は、一般に文embedding ルーティングよりも優れており、タスク固有の先読みが少なくても有利になる可能性を示唆する。
- エキスパート数の増加は一般に性能を向上させ、MoV は 770M および 11B モデルで約 60 エキスパート、3B モデルで約 30 エキスパートの時に最良の結果を示す。
- 大きなモデルサイズでは MoV が MoLORA より優れる傾向があり、MoLORA はエキスパート数を抑えても小規模スケールで全ファインチューニングに対抗できる。
- サイズを問わず、MoV は未知タスクの性能で標準的な PEFT ベースライン(IA)3 および LORA を一貫して上回る。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。