[論文レビュー] Q*: Improving Multi-step Reasoning for LLMs with Deliberative Planning
Q*はマルチステップ推論をプラグアンドプレイのQ値モデルによって誘導されるヒューリスティック探索として扱い、LLMsがファインチューニングなしで次のステップを計画できるようにし、数理推論とコード生成タスクの精度を向上させる。
Large Language Models (LLMs) have demonstrated impressive capability in many natural language tasks. However, the auto-regressive generation process makes LLMs prone to produce errors, hallucinations and inconsistent statements when performing multi-step reasoning. In this paper, by casting multi-step reasoning of LLMs as a heuristic search problem, we aim to alleviate the pathology by introducing Q*, a general, versatile and agile framework for guiding LLMs decoding process with deliberative planning. By learning a plug-and-play Q-value model as heuristic function for estimating expected future rewards, our Q* can effectively guide LLMs to select the most promising next reasoning step without fine-tuning LLMs for the current task, which avoids the significant computational overhead and potential risk of performance degeneration on other tasks. Extensive experiments on GSM8K, MATH and MBPP demonstrate the superiority of our method, contributing to improving the reasoning performance of existing open-source LLMs.
研究の動機と目的
- LLMsにおけるマルチステップ推論をマルコフ決定過程(Markov Decision Process)として形式化し、熟慮的な計画を可能にする。
- ファインチューニングなしでLLMのデコードを導くプラグアンドプレイQ-value駆動フレームワークとしてQ*を導入する。
- 有望な次のステップを選択するための学習可能なQ値プロキシを備えたA*ベースの熟慮プロセスを開発する。
- Q*がオープンソースのLLM全体で数理・コードタスクの推論性能を向上させることを示す。
提案手法
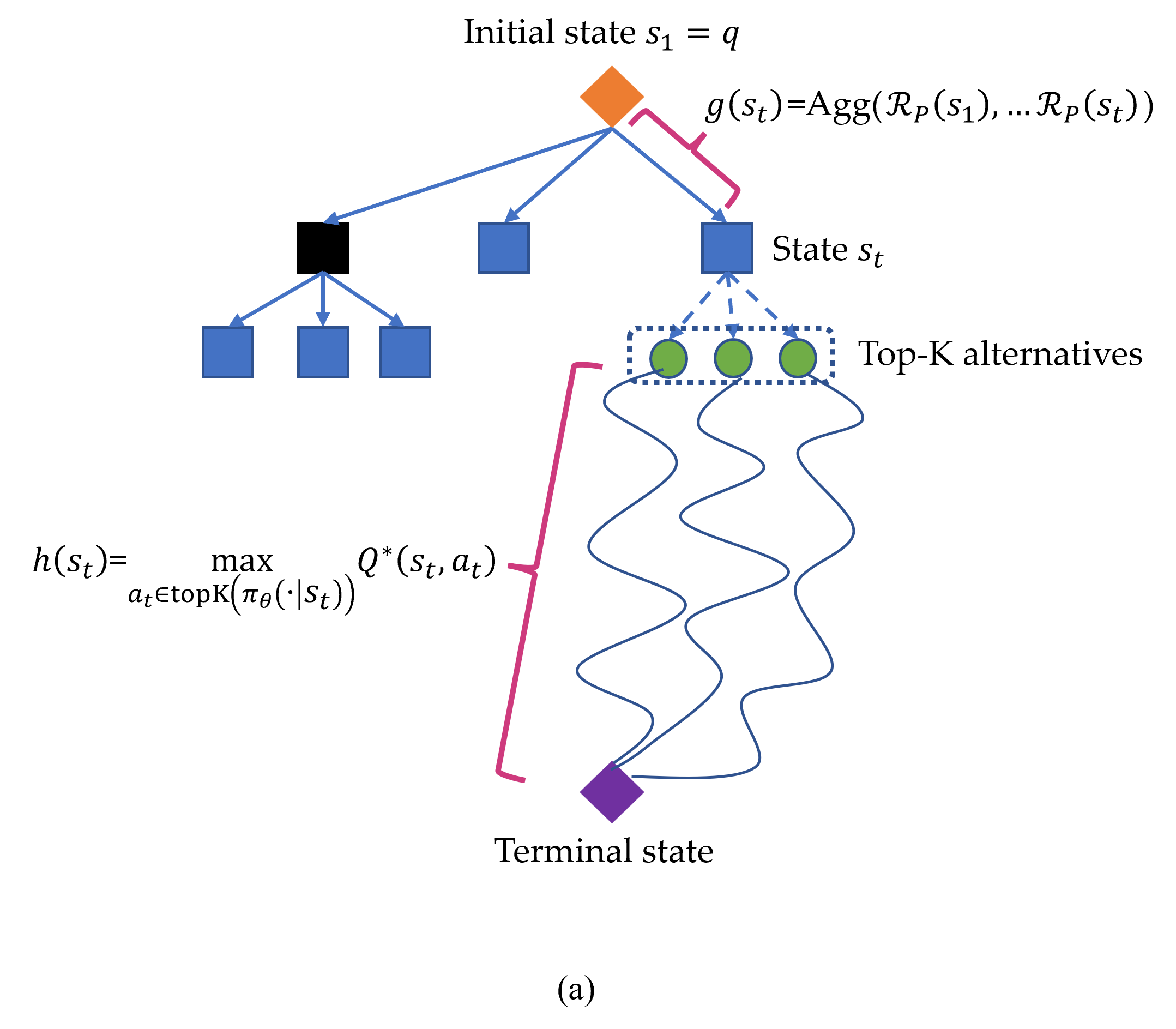
- 推論過程をMDPとしてモデル化し、状態s_tがプロンプトとこれまでの手順を結合する。
- 行動a_tを取ることから得られる将来の報酬の期待値を表すQ関数Q^πθ(s_t,a_t)を定義する。
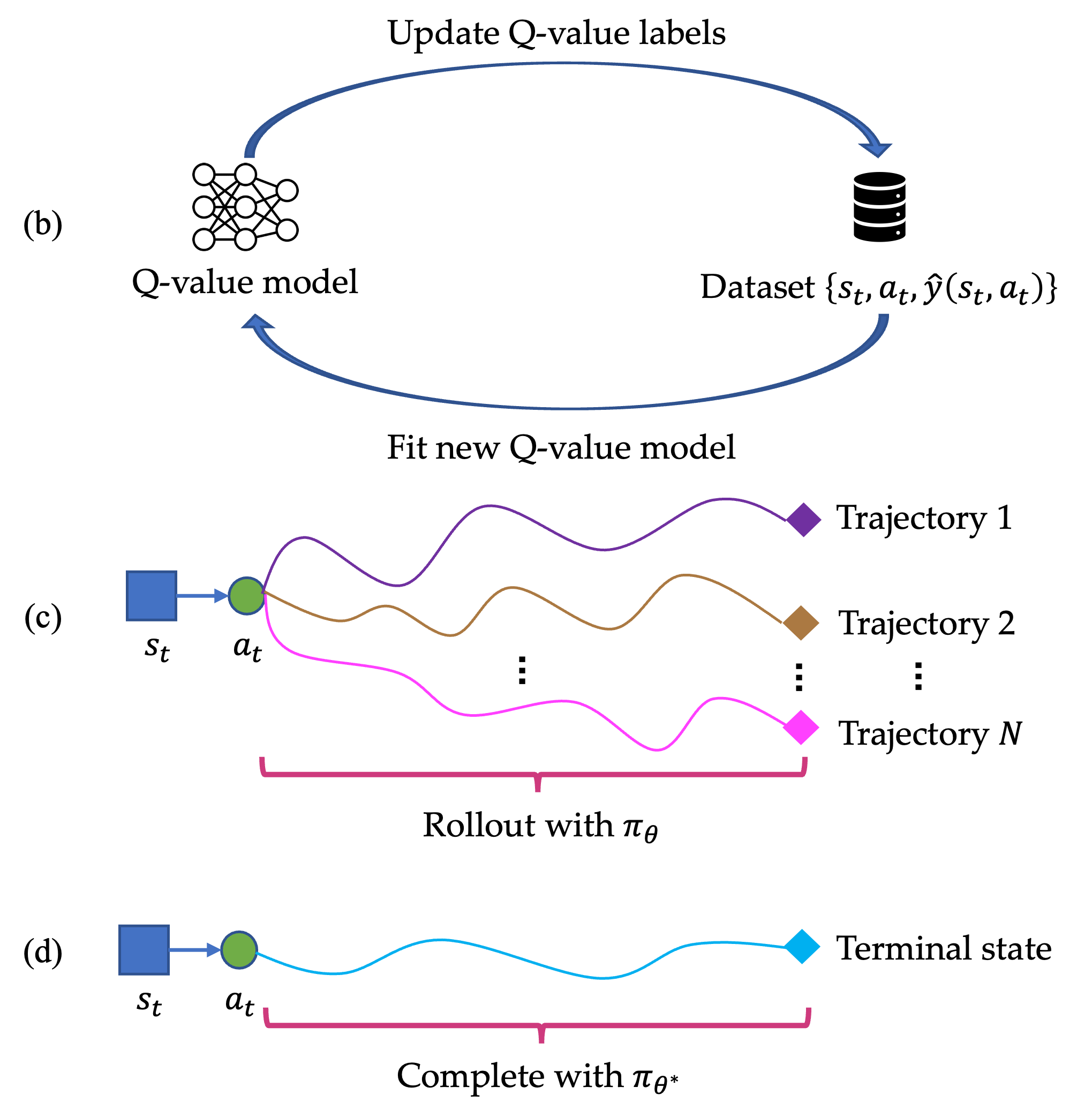
- オフラインRL、 ロールアウト、またはより強力なLLM完了を通じて最適なQ値を推定するプラグアンドプレイ代理Q値モデル Ŷ を使用する。
- f(s_t)=g(s_t)+λ max_a Q*(s_t,a) を用いたA*探索を組み込み、最良優先探索を導く。
- 計画を扱いやすくするため、現在のLLMポリシーから上位K件の候補にアクションを制限する。
- FQI (offline RL)、ロールアウトに基づくラベル、またはより強力なLLM完了といった手法を用いて代理Q値モデルを学習する。
実験結果
リサーチクエスチョン
- RQ1プラグアンドプレイQ値モデルはファインチューニングなしにLLMsがより有望な次の推論ステップを選ぶのを導けるか。
- RQ2マルチステップ推論をヒューリスティック探索として定式化することで、数理推論およびコード生成タスクの精度は向上するか。
- RQ3オフラインQ学習、ロールアウトに基づくラベリング、またはより強力なモデル完了はこの設定で最適なQ値を推定するのにどれほど有効か。
- RQ4Q*のGSM8K、MATH、MBPPでの実証性能は、ベースラインプロンプティングおよび検証手法と比較してどうか。
主な発見
- Q* with QVM/QRM guidance improves performance over Best-of-N baselines across GSM8K, MATH, and MBPP.
- On GSM8K with Llama-2-7b, Q* with PRM+QVM achieves 80.8% accuracy, surpassing several closed and open models.
- On MATH, Q* improves results for multiple base models, with Q* (QVM) and Q* (PRM+QVM) achieving strong gains over baselines.
- On MBPP, CodeQwen1.5-7b-Chat with Q* (PRM+QVM) reaches 77.0% accuracy, outperforming Best-of-N baselines.
- The method remains plug-and-play, avoiding fine-tuning LLMs and reducing risk of degradation on other tasks.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。