[論文レビュー] QLoRA: Efficient Finetuning of Quantized LLMs
QLoRAは量子化された4ビットLMをLow Rank Adaptersで微調整し、16ビットの性能に匹敵するがはるか少ないメモリで、大規模モデルを単一GPUで訓練可能にする。
We present QLoRA, an efficient finetuning approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance. QLoRA backpropagates gradients through a frozen, 4-bit quantized pretrained language model into Low Rank Adapters~(LoRA). Our best model family, which we name Guanaco, outperforms all previous openly released models on the Vicuna benchmark, reaching 99.3% of the performance level of ChatGPT while only requiring 24 hours of finetuning on a single GPU. QLoRA introduces a number of innovations to save memory without sacrificing performance: (a) 4-bit NormalFloat (NF4), a new data type that is information theoretically optimal for normally distributed weights (b) double quantization to reduce the average memory footprint by quantizing the quantization constants, and (c) paged optimziers to manage memory spikes. We use QLoRA to finetune more than 1,000 models, providing a detailed analysis of instruction following and chatbot performance across 8 instruction datasets, multiple model types (LLaMA, T5), and model scales that would be infeasible to run with regular finetuning (e.g. 33B and 65B parameter models). Our results show that QLoRA finetuning on a small high-quality dataset leads to state-of-the-art results, even when using smaller models than the previous SoTA. We provide a detailed analysis of chatbot performance based on both human and GPT-4 evaluations showing that GPT-4 evaluations are a cheap and reasonable alternative to human evaluation. Furthermore, we find that current chatbot benchmarks are not trustworthy to accurately evaluate the performance levels of chatbots. A lemon-picked analysis demonstrates where Guanaco fails compared to ChatGPT. We release all of our models and code, including CUDA kernels for 4-bit training.
研究の動機と目的
- 非常に大きな言語モデル(LLMs)のメモリ効率の高い微調整を動機づける。
- パフォーマンスを維持するために4-bit NF4量子化とLow Rank Adaptersを提案。
- 7B–65Bモデルと複数の指示フォローのベンチマークでスケーラビリティを実証。
- データ品質とデータセットサイズを分析し、人間評価とGPT-4評価を用いてチャットボットの性能を評価。
提案手法
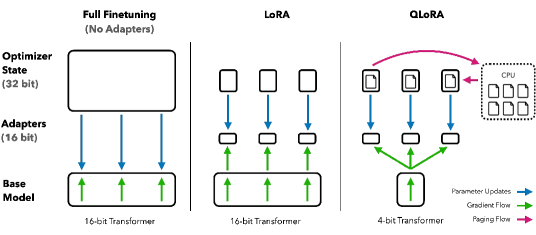
- Double Quantizationを用いて4-bit NF4へ事前学習重量を量子化しメモリフットプリントを削減。
- 量子化された重みに対して勾配を逆伝播し、各トランスフォーマ層に挿入されたLoRAアダプターを学習。
- 訓練中のメモリスパイクを処理するためにPaged OptimizersとNVIDIA unified memoryを使用。
- フォワードとバックワードでBF16へデ量子化の計算パスを維持しつつ、更新はLoRAパラメータのみ。
- 複数のモデルサイズとデータセットに対して全て16-bit微調整と16-bit LoRAのベースラインと比較して評価。
実験結果
リサーチクエスチョン
- RQ1LoRAアダプターと組み合わせた場合、4-bit NF4量子化は完全な16-bit微調整の性能を保てるか?
- RQ2QLoRAはモデルサイズ(7B–65B)と指示データセットでどの程度の精度とメモリ効率を持ってスケールするか?
- RQ3データ品質とデータセットの選択は、指示チューニングとチャットボット機能のデータセットサイズより優先されるか?
- RQ4GPT-4と人間の評価は、Vicuna/OASST1ベンチマークで訓練されたチャットボットのランキングにおいてどのように比較されるか?
主な発見
| モデル / データセット | パラメータ | モデルビット | メモリ | ChatGPT vs Sys | Sys vs ChatGPT | 平均 | 95% CI |
|---|---|---|---|---|---|---|---|
| GPT-4 | - | - | - | 119.4% | 110.1% | 114.5% | 2.6% |
| Bard | - | - | - | 93.2% | 96.4% | 94.8% | 4.1% |
| Guanaco 65B | 65B | 4-bit | 41 GB | 96.7% | 101.9% | 99.3% | 4.4% |
| Alpaca 65B | 65B | 4-bit | 41 GB | 63.0% | 77.9% | 70.7% | 4.3% |
| FLAN v2 65B | 65B | 4-bit | 41 GB | 37.0% | 59.6% | 48.4% | 4.6% |
| Guanaco 33B | 33B | 4-bit | 21 GB | 96.5% | 99.2% | 97.8% | 4.4% |
| Open Assistant 33B | 33B | 16-bit | 66 GB | 91.2% | 98.7% | 94.9% | 4.5% |
| Vicuna 13B | 13B | 16-bit | 26 GB | 91.2% | 98.7% | 94.9% | 4.5% |
| Guanaco 13B | 13B | 4-bit | 10 GB | 87.3% | 93.4% | 90.4% | 5.2% |
| Alpaca 13B | 13B | 4-bit | 10 GB | 63.8% | 76.7% | 69.4% | 4.2% |
| HH-RLHF 13B | 13B | 4-bit | 10 GB | 55.5% | 69.1% | 62.5% | 4.7% |
| Unnatural Instr. 13B | 13B | 4-bit | 10 GB | 50.6% | 69.8% | 60.5% | 4.2% |
| Chip2 13B | 13B | 4-bit | 10 GB | 49.2% | 69.3% | 59.5% | 4.7% |
| Longform 13B | 13B | 4-bit | 10 GB | 44.9% | 62.0% | 53.6% | 5.2% |
| Self-Instruct 13B | 13B | 4-bit | 10 GB | 38.0% | 60.5% | 49.1% | 4.6% |
| FLAN v2 13B | 13B | 4-bit | 10 GB | 32.4% | 61.2% | 47.0% | 3.6% |
- NF4 + Double QuantizationのQLoRAは、学術ベンチマークで16-bitフル微調整と16-bit LoRAの性能に匹敵する。
- NF4はゼロショットと微調整タスクでFP4およびInt4を上回り、Double Quantizationはメモリを削減しつつ性能を劣化させない。
- Guanacoモデル(7B–65B)はVicunaベンチマークでChatGPTに近い性能を達成し、Guanaco 65BはGPT-4評価 Vicuna結果でChatGPTの99.3%に達する。
- 4-bit QLoRAは1つの48GB GPUで65Bモデルの微調整を可能にし、21GBで33Bを可能にするなど、全体の16-bit微調整と比較して大幅なメモリ節約。
- データセットの品質は指示追従とチャットボットの性能においてサイズより重要であり、強力なMMLU性能が必ずしも優れたチャットボット性能を意味しない。
- GPT-4ベースの評価はチャットボットを対戦形式で比較する際に人間の判断と大筋で一致するが、慎重な解釈を要する顕著な意見の相違が存在する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。