[論文レビュー] Quantizing deep convolutional networks for efficient inference: A whitepaper
このホワイトペーパーは、CNNの重みと活性化を8、4、または16ビットに量子化するための後処理量子化(ポストトレーニング)と量子化対応訓練の方法を調査し、アーキテクチャ全体での精度影響を分析し、エdgeデバイスでの効率的な推論のためのTensorFlowツールと訓練のベストプラクティスを提供します。
We present an overview of techniques for quantizing convolutional neural networks for inference with integer weights and activations. Per-channel quantization of weights and per-layer quantization of activations to 8-bits of precision post-training produces classification accuracies within 2% of floating point networks for a wide variety of CNN architectures. Model sizes can be reduced by a factor of 4 by quantizing weights to 8-bits, even when 8-bit arithmetic is not supported. This can be achieved with simple, post training quantization of weights.We benchmark latencies of quantized networks on CPUs and DSPs and observe a speedup of 2x-3x for quantized implementations compared to floating point on CPUs. Speedups of up to 10x are observed on specialized processors with fixed point SIMD capabilities, like the Qualcomm QDSPs with HVX. Quantization-aware training can provide further improvements, reducing the gap to floating point to 1% at 8-bit precision. Quantization-aware training also allows for reducing the precision of weights to four bits with accuracy losses ranging from 2% to 10%, with higher accuracy drop for smaller networks.We introduce tools in TensorFlow and TensorFlowLite for quantizing convolutional networks and review best practices for quantization-aware training to obtain high accuracy with quantized weights and activations. We recommend that per-channel quantization of weights and per-layer quantization of activations be the preferred quantization scheme for hardware acceleration and kernel optimization. We also propose that future processors and hardware accelerators for optimized inference support precisions of 4, 8 and 16 bits.
研究の動機と目的
- モデルサイズ、メモリ、電力を削減してエッジ推論を可能にするための量子化を動機づける。
- 複数のCNNアーキテクチャにおける8、4、16ビット量子化の精度とレイテンシのトレードオフを特徴づける。
- ポストトレーニング量子化と量子化対応訓練の両方のアプローチを開発・評価する。
- TensorFlow/TensorFlow Liteで量子化モデルを実装するための実用的なガイドラインとツール群を提供する。
提案手法
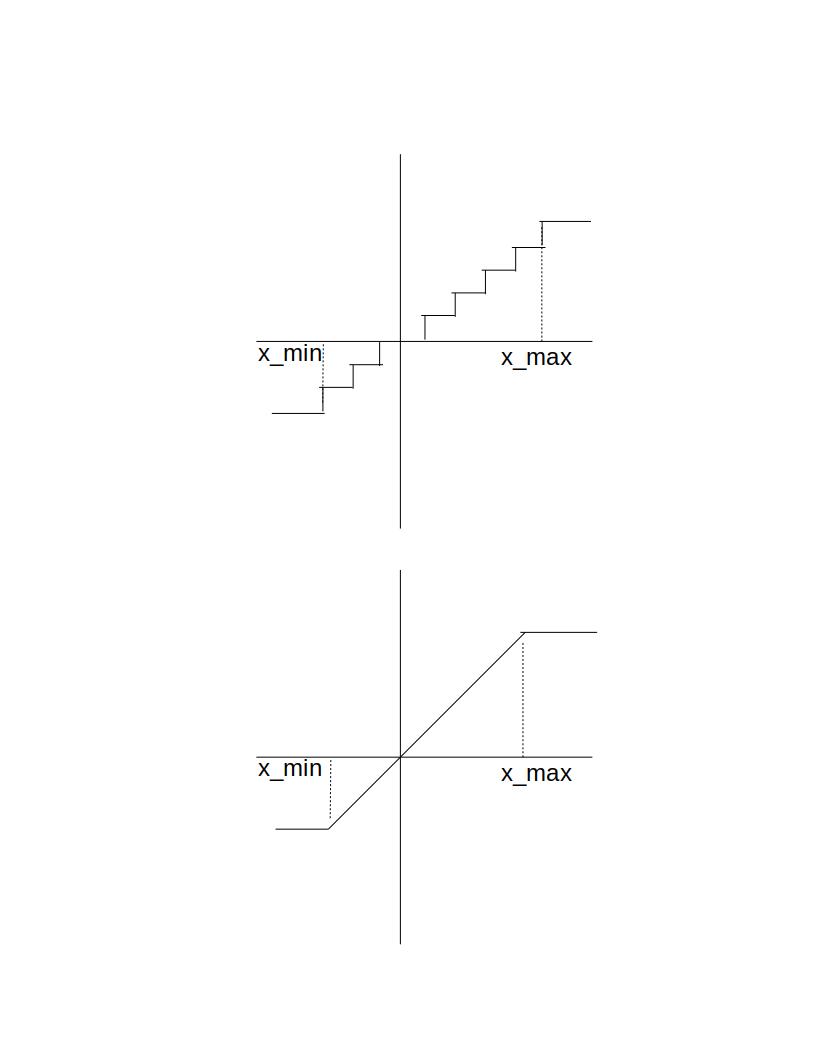
- 重みと活性化には、一様アフィン量子化器、対称量子化、確率的量子化を提示する。
- 模擬量子化とストレートスルー推定を用いた前向き/後向き伝搬の式を導出する。
- ImageNet上のMobileNet、Inception、ResNet、NasNetなどのネットワークに対して、ポストトレーニング量子化(重みのみ・重みと活性化)と量子化対応訓練を評価する。
- 精度への量子化粒度(層単位 vs チャンネル単位)の影響を分析する。
- 量子化推論のためのバッチ正規化の取り扱いと計算効率を考慮した折り畳み戦略を議論する。
- 量子化とデプロイメントの実用的なワークフローとTensorFlowツールを提供する。
実験結果
リサーチクエスチョン
- RQ1一般的なCNNアーキテクチャにおいて、(チャンネル単位の重み、層単位の活性化)などのどの量子化方式が、浮動小数点に近い精度を維持しますか。
- RQ28ビット以下のビット幅における精度の観点で、ポストトレーニング量子化と量子化対応訓練はどのように比較されますか。
- RQ3量子化されたCNNの精度と安定性に対するバッチ正規化の取り扱いの影響は何ですか。
- RQ4TensorFlow/TensorFlow Liteでの量子化モデルの実用的なデプロイを可能にするツールと訓練ワークフローは何ですか。
- RQ5量子化ネットワークを使用した場合、CPU、DSP、特殊アクセラレータでのレイテンシとモデルサイズの利点は何ですか。
主な発見
- 8ビット精度で、チャンネル単位の重み量子化と層単位の活性化量子化を組み合わせると、多くのアーキテクチャでFP32から約2%程度の差に収束する。
- 8ビットの重み量子化は、8ビット演算が利用できなくてもポストトレーニング量子化によりモデルサイズを約4倍削減する。
- 量子化されたネットワークはCPUで2倍〜3倍、固定小数点 SIMD ハードウェアでは最大約10倍の高速化を実現する。
- 量子化対応訓練は8ビット精度でFP32との差を約1%に縮小し、アーキテクチャに応じて2%〜10%の精度低下で4ビット重み量子化を可能にする。
- 一般にチャンネル単位の重み量子化は層単位よりも性能が高い(特に4ビット精度で微調整時)。
- 活性化の8ビット量子化は、BatchNormの簡略化やReLU6などの正規化戦略により精度低下が小さい。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。