[論文レビュー] Query-Dependent Video Representation for Moment Retrieval and Highlight Detection
本論文は QD-DETR を提案する。テキストクエリの文脈をビデオ表現に注入するクエリ依存型 DETR で、モーメント検索とハイライト検出に用いられる。ネガティブペア学習と入力適応型顕性予測器を利用する。QVHighlights、TVSum、Charades-STA で最先端の結果を達成している。
Recently, video moment retrieval and highlight detection (MR/HD) are being spotlighted as the demand for video understanding is drastically increased. The key objective of MR/HD is to localize the moment and estimate clip-wise accordance level, i.e., saliency score, to the given text query. Although the recent transformer-based models brought some advances, we found that these methods do not fully exploit the information of a given query. For example, the relevance between text query and video contents is sometimes neglected when predicting the moment and its saliency. To tackle this issue, we introduce Query-Dependent DETR (QD-DETR), a detection transformer tailored for MR/HD. As we observe the insignificant role of a given query in transformer architectures, our encoding module starts with cross-attention layers to explicitly inject the context of text query into video representation. Then, to enhance the model's capability of exploiting the query information, we manipulate the video-query pairs to produce irrelevant pairs. Such negative (irrelevant) video-query pairs are trained to yield low saliency scores, which in turn, encourages the model to estimate precise accordance between query-video pairs. Lastly, we present an input-adaptive saliency predictor which adaptively defines the criterion of saliency scores for the given video-query pairs. Our extensive studies verify the importance of building the query-dependent representation for MR/HD. Specifically, QD-DETR outperforms state-of-the-art methods on QVHighlights, TVSum, and Charades-STA datasets. Codes are available at github.com/wjun0830/QD-DETR.
研究の動機と目的
- MR/HD タスクにおいて真にクエリ駆動のビデオ表現が必要であることを動機づける。
- テキストクエリを動画エンコードに集中的に統合する検出型トランスフォーマーベースのモデルを開発する。
- ネガティブな動画-クエリペアを構築・活用して識別的学習を促す。
- クエリ-動画ペアごとに顕性基準を調整する入力適応型顕性予測器を導入する。
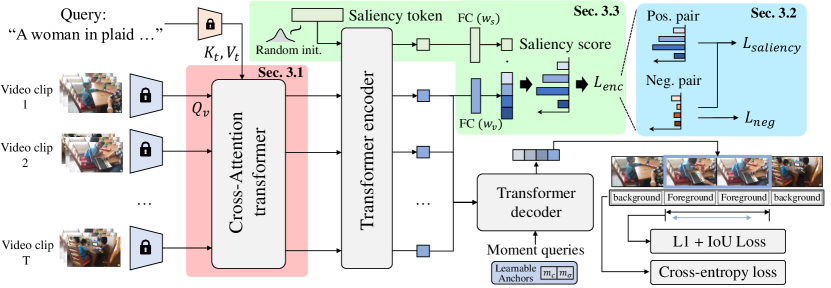
提案手法
- エンコーダ入力にクロスアテンションを挿入し、動画クリップとテキストクエリ特徴を融合する。
- 関連性の低いペアの顕性を抑制するため、ネガティブな動画-クエリペアで訓練する。
- クリップ顕性を計算するため、入力適応型予測子として顕性トークンを用いる。
- 動的アンカーモーメントをクエリとして用いる DETR似のデコーダを実装し、時系列定位を行う。
- MR を L1 損失と一般化 IoU 損失で最適化し、HD をマージンモデルランキングとランク認識型コントラスト損失で最適化する。
- MR/HD 指標を共同・個別に MR/HD ベンチマークで評価する。

実験結果
リサーチクエスチョン
- RQ1クエリ依存型のビデオ表現は、クエリ非依存のベースラインと比較してモーメント検索とハイライト検出を改善するか?
- RQ2ネガティブ動画-クエリペア学習は顕性推定とモーメント定位にどのような影響を与えるか?
- RQ3入力適応型顕性予測器は多様なクエリ間で顕性回帰にどのように影響するか?
- RQ4提案された要素は標準的な MR/HD データセットで最先端の性能を達成するか?
主な発見
| Method | Src | MR | HD | @0.5 | @0.7 | @0.5 | @0.75 | Avg. | mAP | HIT@1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| BeautyThumb | V | - | - | - | - | - | - | - | - | - | |
| DVSE | V | - | - | - | - | - | - | - | - | - | |
| MCN | V | 11.41 | 2.72 | 24.94 | 8.22 | 10.67 | - | - | - | - | |
| CAL | V | 25.49 | 11.54 | 23.40 | 7.65 | 9.89 | - | - | - | - | |
| XML | V | 41.83 | 30.35 | 44.63 | 31.73 | 32.14 | 34.49 | 55.25 | - | - | |
| XML+ | V | 46.69 | 33.46 | 47.89 | 34.67 | 34.90 | 35.38 | 55.06 | - | - | |
| Moment-DETR | V | 52.89 ±2.3 | 33.02 ±1.7 | 54.82 ±1.7 | 29.40 ±1.7 | 30.73 ±1.4 | 35.69 ±0.5 | 55.60 ±1.6 | - | - | - |
| QD-DETR (Ours) | V | 62.40 ${}_{\pm_{1.1}}$ | 44.98 ${}_{\pm_{0.8}}$ | 62.52 ${}_{\pm_{0.6}}$ | 39.88 ${}_{\pm_{0.7}}$ | 39.86 ${}_{\pm_{0.6}}$ | 38.94 ${}_{\pm_{0.4}}$ | 62.40 ${}_{\pm_{1.4}}$ | - | - | - |
| UMT | V+A | 56.23 | 41.18 | 53.38 | 37.01 | 36.12 | 38.18 | 59.99 | - | - | |
| QD-DETR (Ours) | V+A | 63.06 ${}_{\pm_{1.0}}$ | 45.10 ${}_{\pm_{0.7}}$ | 63.04 ${}_{\pm_{0.9}}$ | 40.10 ${}_{\pm_{1.0}}$ | 40.19 ${}_{\pm_{0.6}}$ | 39.04 ${}_{\pm_{0.3}}$ | 62.87 ${}_{\pm_{0.6}}$ | - | - |
- QD-DETR は V 単独入力および V+A 入力で QVHighlights において最先端の手法を上回る。
- QVHighlights では、V を用いた場合 MR mAP が 62.40、HIT@1 が 62.40、さまざまな指標で達成;V+A では MR mR が 63.06、HIT@1 が 62.87 の変種に到達。
- TVSum および Charades-STA では、QD-DETR は baselines を大きく上回り、複数の特徴バックボーンで RS 指標を高く達成。
- アブレーション研究は、クロスアテンシブエンコーディング、ネガティブペア学習、適応的顕性予測器が MR/HD の性能に実質的に寄与することを示し、深い自己注意のみよりも寄与が大きい。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。