[論文レビュー] Qwen2 Technical Report
Qwen2は、0.5Bから72Bの密結合モデルに加え、57B MoEを含むオープンウェイトLLMファミリーを導入し、長文脈能力、多言語対応、指示調整を備え、言語、コーディング、数学、推論のベンチマークで商用モデルおよびオープンベースラインに対して競争力のある性能を達成します。
This report introduces the Qwen2 series, the latest addition to our large language models and large multimodal models. We release a comprehensive suite of foundational and instruction-tuned language models, encompassing a parameter range from 0.5 to 72 billion, featuring dense models and a Mixture-of-Experts model. Qwen2 surpasses most prior open-weight models, including its predecessor Qwen1.5, and exhibits competitive performance relative to proprietary models across diverse benchmarks on language understanding, generation, multilingual proficiency, coding, mathematics, and reasoning. The flagship model, Qwen2-72B, showcases remarkable performance: 84.2 on MMLU, 37.9 on GPQA, 64.6 on HumanEval, 89.5 on GSM8K, and 82.4 on BBH as a base language model. The instruction-tuned variant, Qwen2-72B-Instruct, attains 9.1 on MT-Bench, 48.1 on Arena-Hard, and 35.7 on LiveCodeBench. Moreover, Qwen2 demonstrates robust multilingual capabilities, proficient in approximately 30 languages, spanning English, Chinese, Spanish, French, German, Arabic, Russian, Korean, Japanese, Thai, Vietnamese, and more, underscoring its versatility and global reach. To foster community innovation and accessibility, we have made the Qwen2 model weights openly available on Hugging Face and ModelScope, and the supplementary materials including example code on GitHub. These platforms also include resources for quantization, fine-tuning, and deployment, facilitating a wide range of applications and research endeavors.
研究の動機と目的
- オープンウェイトLLMを0.5B–72Bの密結合、57B MoEを含む広範なサイズスペクトルで前進させる。
- 建築とデータの改善を通じて長文脈処理能力と多言語機能を向上させる。
- スケーラブルなデータ戦略を用いた教師あり微調整とRLHFにより、人間の嗜好にモデルを合わせる。
- 言語、コーディング、数学、推論のベンチマークで商用モデルに対して競争力のある性能を示す。
- 研究とデプロイメントを促進するため、ウェイトとツールの公開アクセスを提供する。
提案手法
- Grouped Query Attention (GQA) および Dual Chunk Attention (DCA) を備えたTransformerベースの密結合およびミクスチャー・オブ・エキスパート (MoE) アーキテクチャを用い、長文脈を実現する。
- 安定性のために Rotary Position Embeddings (RoPE) と SwiGLU アクティベーションを RMSNorm および事前正規化と共に採用する。
- 密結合モデルで>7兆トークン以上の大規模多言語コーパスで訓練する。MoEは追加のアップサイクリングデータを受ける。
- コンテキスト長を32,768トークンへ拡張し、YARNとDual Chunk Attentionを用いて131,072トークンまでのシーケンスを可能にする。
- 監督付き微調整とDirect Preference Optimization (DPO) によりRLHFを実施した後、オンラインマージング最適化器を用いて整合性コストを削減する。
- 協同データ注釈と自動データ合成を活用して、高品質なデモンストレーションデータセットと嗜好データセットを構築する。
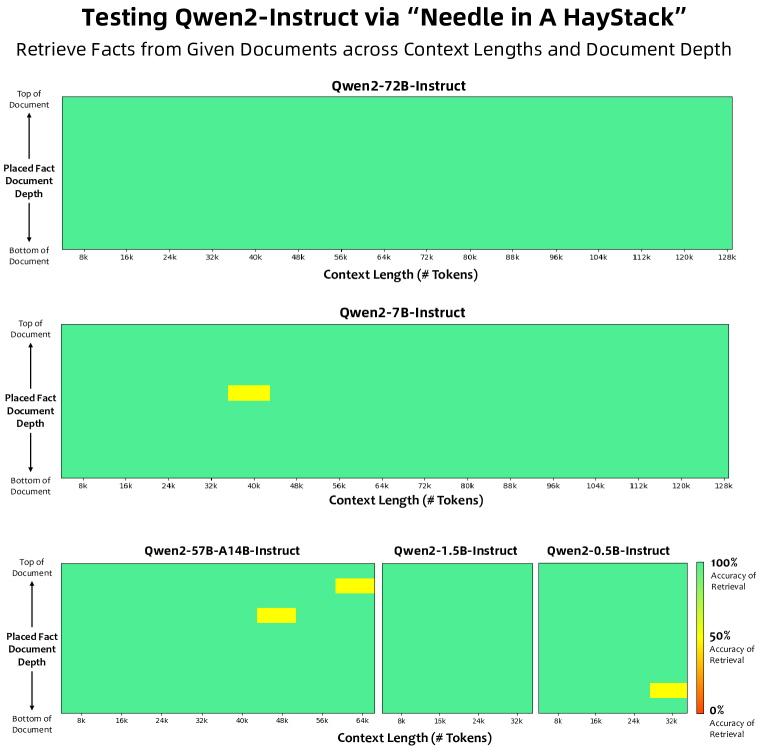
実験結果
リサーチクエスチョン
- RQ1Qwen2のdenseおよびMoEモデルは、知識、コーディング、数学、推論、そして多言語のベンチマークにおいて、オープンおよび商用ベースラインと比較してどの程度の性能を示すか。
- RQ2長文脈トレーニングとデータスケーリングがモデル能力と信頼性に与える影響は何か。
- RQ3スケーラブルなアライメント(SFT + RLHF with DPO およびオンライン最適化)は、言語を跨いで安全・正直・有用な指示追従モデルを生み出せるか。
- RQ4Qwen2-MoEにおける微細なMoEルーティングとエキスパート初期化のトレードオフと効率性はどの程度か。
- RQ5ウェイトとツールのオープンソース化は、多言語、コード、推論タスクにおける研究とデプロイをどの程度促進するか。
主な発見
- Qwen2-72BはMMLUで84.2、GPQAで37.9、HumanEvalで64.6、GSM8Kで89.5、BBHで82.4の性能を基準モデルとして達成する。
- Qwen2-72B-InstructはMT-Benchで9.1、Arena-Hardで48.1、LiveCodeBenchで35.7を達成する。
- Qwen2-57B-A14B MoEは、1トークンあたり14Bパラメータを活性化しつつ、30Bの密結合モデルと同等以上の性能を発揮し、コーディングと数学の結果が強力である。
- Qwen2は英語、中国語、スペイン語、フランス語、ドイツ語、アラビア語、ロシア語、韓国語、日本語、タイ語、ベトナム語を含む約30言語で堅牢な多言語機能を示す。
- 小型の0.5Bおよび1.5Bモデルは競争力のある性能を示し、1.5Bは数学と中国語理解でいくつかのベースラインを上回る。
- 公開ウェイトと補足資料は、研究とデプロイを支援するためにHugging Face、ModelScope、GitHubで公開されている。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。