[論文レビュー] RA-DIT: Retrieval-Augmented Dual Instruction Tuning
tldr: RA-DIT は 2 段階のファインチューニングプロセスを通じて、取得情報を活用する LM ファインチューニングと関連する結果を返すリトリーバーのファインチューニングを組み合わせ、知識集約型タスクで最先端の結果を達成し、特にゼロショットおよび少数ショット設定で顕著です。
Retrieval-augmented language models (RALMs) improve performance by accessing long-tail and up-to-date knowledge from external data stores, but are challenging to build. Existing approaches require either expensive retrieval-specific modifications to LM pre-training or use post-hoc integration of the data store that leads to suboptimal performance. We introduce Retrieval-Augmented Dual Instruction Tuning (RA-DIT), a lightweight fine-tuning methodology that provides a third option by retrofitting any LLM with retrieval capabilities. Our approach operates in two distinct fine-tuning steps: (1) one updates a pre-trained LM to better use retrieved information, while (2) the other updates the retriever to return more relevant results, as preferred by the LM. By fine-tuning over tasks that require both knowledge utilization and contextual awareness, we demonstrate that each stage yields significant performance improvements, and using both leads to additional gains. Our best model, RA-DIT 65B, achieves state-of-the-art performance across a range of knowledge-intensive zero- and few-shot learning benchmarks, significantly outperforming existing in-context RALM approaches by up to +8.9% in 0-shot setting and +1.4% in 5-shot setting on average.
研究の動機と目的
- 完全な再訓練や事前訓練を要せず、LLM の知識の活用と文脈把握の向上を動機づける。
- 任意の事前訓練済み LLM およびリトリーバーへリトリーバルをレトロフィットする、軽量な二段階ファインチューニング手順を提案する。
- LM-ft と R-ft の結合が知識集約型タスクで相加的な利得を生むことを示す。
- RA-DIT 65B のゼロショットおよび少数ショットベンチマークにおける最先端の性能を実証する。
提案手法
- バックボーンとして事前訓練済みの LLaMA モデルを使用し、Dense retriever として Dragon+ を用いる。
- 各プロンプトに対して top-k のテキストチャンクを取得し、それらを背景フィールドとして指示に先頭に付与して、チャンク間での並列アンサンブリングを可能にする。
- LM fine-tuning (LM-ft): 拡張された背景 c i および指示 x を用いて p(y|c i ∘ x) を最大化するように LLM を訓練し、取得済みの背景情報を活用し、誤解を招く内容を無視するようモデルを導く。
- Retriever fine-tuning (R-ft): クエリエンコーダを訓練して、retriever のスコア pR(c|x) と、LM の尤度 pLM(y|c∘x) に基づく学習済み LM-Supervised Retrieval 分布 pLSR(c|x,y) との間の KL ダイバージェンスを最小化する。
- LM-ft と R-ft を組み合わせて共同の利得を達成し、ファインチューニング中に見られなかった知識集約型タスクで評価を行う。

実験結果
リサーチクエスチョン
- RQ1軽量な二段階ファインチューニングで、完全な事前学習なしに既存の LLM にリトリーバル機能をレトロフィットできるか?
- RQ2LM-ft と R-ft の別個の段階は相加的な利得を生み出すか、組み合わせた場合の相互作用はどうなるか?
- RQ3既製の LLM+リトリーバーアプローチおよび継続的に事前訓練された RALM と比較して、RA-DIT はゼロショットおよび少数ショットの知識集約ベンチマークでどう性能を示すか?
主な発見
- RA-DIT 65B は、ゼロショットおよび少数ショットの知識集約ベンチマークで最先端の結果を達成し、MMLU、NQ、TQA、ELI5 の平均で、0-shot の場合にインコンテキスト RALMs を大幅に上回り、最大で +8.9 ポイント、5-shot では最大で +1.4 ポイント上回る。
- 統合された 64-shot 設定で、8 タスク中 6 タスクにおいて Atlas (64-shot ファインチューニング済みエンコーダ-デコーダ RALM) を平均 4.1 ポイント上回る。
- LM-ft も R-ft も利得に寄与する;最良の結果は両方を組み合わせることで得られ(5-shot では平均約 0.8 ポイント RA-DIT が RePlug を上回す)。
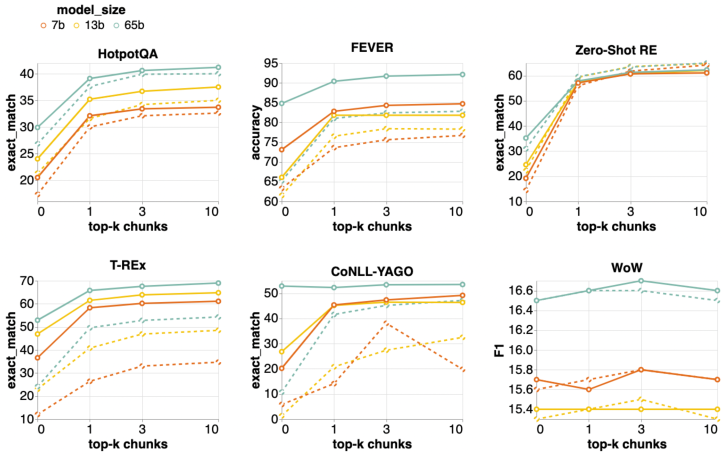
- 検索補強は、top-1 チャンクを1つだけ使用した場合でも 65B パラメータの LLaMA を改善し、より多くのチャンクを使用するとさらなる利得が得られる。
- コーパスデータを用いてリトリーバーをファインチューニングすることは、MTI データだけの場合より一般化性能が高く、クエリエンコーダをファインチューニングする際にドキュメントエンコーダを凍結すると強力な結果となる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。