[論文レビュー] RAB: Provable Robustness Against Backdoor Attacks
この論文は、訓練データに対するランダム化スムージングを用いたバックドア(ポイズニング)攻撃に対して証明可能な頑健性を持つトレーニングフレームワーク RAB を紹介します。理論的保証と効率的な実装、さらには広範なベンチマークを含みます。
Recent studies have shown that deep neural networks (DNNs) are vulnerable to adversarial attacks, including evasion and backdoor (poisoning) attacks. On the defense side, there have been intensive efforts on improving both empirical and provable robustness against evasion attacks; however, the provable robustness against backdoor attacks still remains largely unexplored. In this paper, we focus on certifying the machine learning model robustness against general threat models, especially backdoor attacks. We first provide a unified framework via randomized smoothing techniques and show how it can be instantiated to certify the robustness against both evasion and backdoor attacks. We then propose the first robust training process, RAB, to smooth the trained model and certify its robustness against backdoor attacks. We prove the robustness bound for machine learning models trained with RAB and prove that our robustness bound is tight. In addition, we theoretically show that it is possible to train the robust smoothed models efficiently for simple models such as K-nearest neighbor classifiers, and we propose an exact smooth-training algorithm that eliminates the need to sample from a noise distribution for such models. Empirically, we conduct comprehensive experiments for different machine learning (ML) models such as DNNs, support vector machines, and K-NN models on MNIST, CIFAR-10, and ImageNette datasets and provide the first benchmark for certified robustness against backdoor attacks. In addition, we evaluate K-NN models on a spambase tabular dataset to demonstrate the advantages of the proposed exact algorithm. Both the theoretic analysis and the comprehensive evaluation on diverse ML models and datasets shed light on further robust learning strategies against general training time attacks.
研究の動機と目的
- バックドア攻撃に対する証明可能な頑健性の不足に対処する。
- 散乱平滑化をトレーニング時の攻撃へ拡張する統一フレームワークを開発する。
- RAB を提案する、バックドアに対して頑健性を証明する頑健なトレーニングパイプライン。
- 理論的境界を提供し、これらの境界の厳密性を示す。
- 多様なモデルとデータセットを横断して基盤的な頑健性のベンチマークを確立する。
提案手法
- テスト入力と訓練データの両方をランダム化するスムージング分類器を定義する。
- Neyman–Pearson の補題を用いて一般的で厳密な頑健性条件(定理1)を導出する。
- ガウス平滑化と一様平滑化でフレームワークを具体化し、バックドア頑健性を証明する(GaussianCorollary 1)。
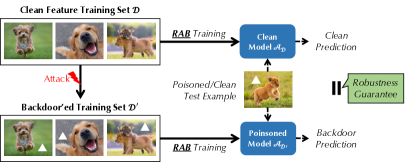
- RAB 訓練を提案する:N 個のスムージングされた訓練セットを生成し、N 個のモデルを訓練し、出力を集約する。
- 頑健性境界が厳密であることを証明する(定理2)。
- K最近傍法のための正確で効率的なスムージングアルゴリズムを開発する(モンテカルロサンプリングは不要)。
実験結果
リサーチクエスチョン
- RQ1MLモデルのバックドア(ポイズニング)攻撃に対して頑健性を証明できるか?
- RQ2スムージング分布をどのように選択すべきか、バックドア頑健性を証明し得るノルム/境界はどうなるか?
- RQ3頑健性境界は厳密か、どの条件下でそうなるか?
- RQ4K-NN のような特定のモデル群について効率的に頑健性を証明するにはどうすればよいか?
- RQ5実データセット上で DNN、SVM、K-NN にまたがる認定済み頑健性境界の適用性はどうなるか?
主な発見
- 一般的なMLモデルに対するバックドア攻撃への初の認定可能な頑健性境界。
- 頑健性境界は厳密である(定理2)。
- サンプリングを回避するK-NNモデル向けの正確で効率的なスムージングアルゴリズムを提供。
- extensive experiments demonstrate robustness bounds on DNNs, SVMs, and K-NN across MNIST, CIFAR-10, and ImageNette, establishing a benchmark for certified backdoor robustness.
- Spambase experiments illustrate advantages of the exact K-NN smoothing algorithm.
- Code and evaluation protocol are publicly released to enable reproducible research.
![Figure 2 : An illustration of the RAB robust training process. Given a poisoned training set $\mathcal{D}+\Delta$ and a training process $\mathcal{A}$ vulnerable to backdoor attacks, RAB generates $N$ smoothed training sets $\{\mathcal{D}_{i}\}_{i\in[N]}$ and trains $N$ different classifiers $\mathc](https://ar5iv.labs.arxiv.org/html/2003.08904/assets/x2.png)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。