[論文レビュー] RAFT: Adapting Language Model to Domain Specific RAG
RAFTは、ドメイン調整済みLLMを訓練して、オープンブックかつドメイン内設定でリトリーブ拡張生成を実行する。 distractorsとチェーン・オブ・思考を引用付きで含めることで、Biomedical、General QA、APIドキュメンテーションのデータセット全体でQAを改善する。
Pretraining Large Language Models (LLMs) on large corpora of textual data is now a standard paradigm. When using these LLMs for many downstream applications, it is common to additionally bake in new knowledge (e.g., time-critical news, or private domain knowledge) into the pretrained model either through RAG-based-prompting, or fine-tuning. However, the optimal methodology for the model to gain such new knowledge remains an open question. In this paper, we present Retrieval Augmented FineTuning (RAFT), a training recipe that improves the model's ability to answer questions in a "open-book" in-domain settings. In RAFT, given a question, and a set of retrieved documents, we train the model to ignore those documents that don't help in answering the question, which we call, distractor documents. RAFT accomplishes this by citing verbatim the right sequence from the relevant document that would help answer the question. This coupled with RAFT's chain-of-thought-style response helps improve the model's ability to reason. In domain-specific RAG, RAFT consistently improves the model's performance across PubMed, HotpotQA, and Gorilla datasets, presenting a post-training recipe to improve pre-trained LLMs to in-domain RAG. RAFT's code and demo are open-sourced at github.com/ShishirPatil/gorilla.
研究の動機と目的
- 事前に学習済みのLLMをドメイン特化の retrieval-augmented generation (RAG)へ適応させる動機付け。
- 無関係な取得文を無視しつつ、正確な passagesを引用するようモデルを訓練するファインチューニング手法を提案する。
- distractorsと推論を含めることが、ドメイン内のRAG性能を向上させることを示す。
- 複数データセットにおいて、取得文の数やテスト時の distractor の割合の変化に対するロバスト性を示す。
提案手法
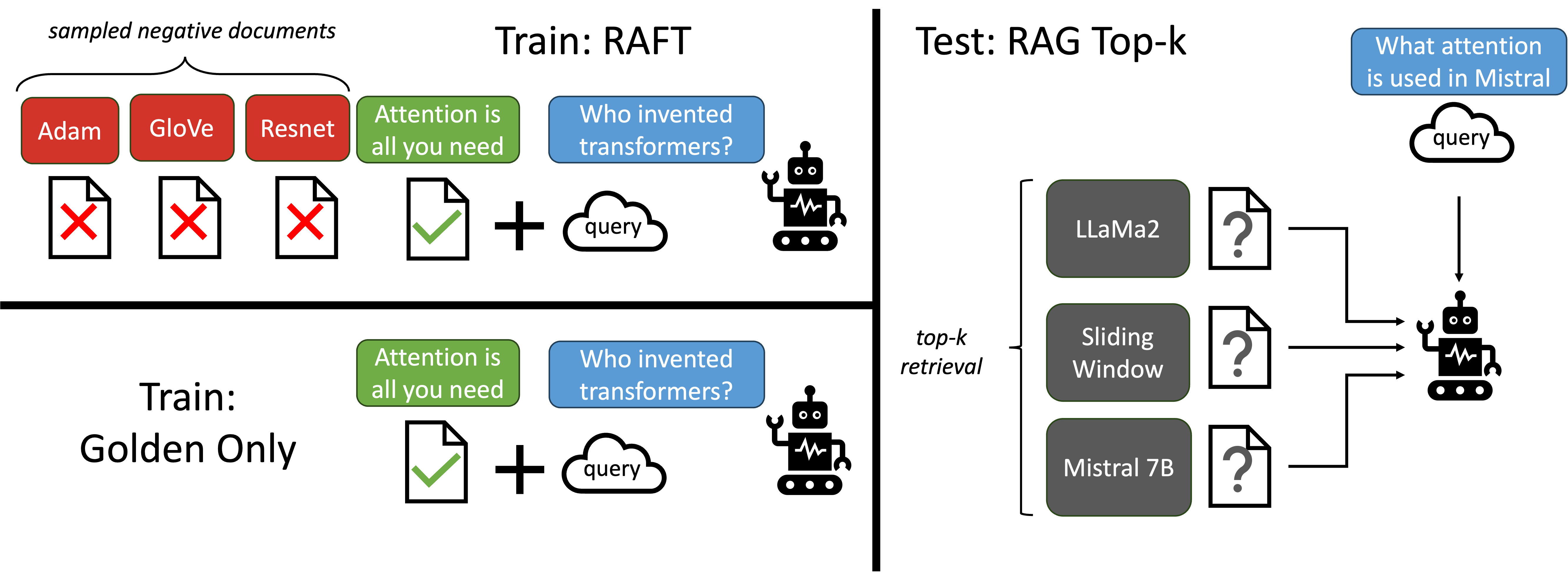
- RAFTを、質問、取得済み文の集合、引用付きのChain-of-Thoughtスタイルの回答を用いる、リトリーブ認識のファインチューニング戦略として導入する。
- 各例が質問 Q、文書集合 Dk、解答 A* を持ち、oracle D* と distractors Di を含む訓練データを作成する。
- データの P 分の割合で oracle 文書を distractors とともに含める;(1-P) 分の割合では oracle を省略して文脈からの記憶を促す。
- CoT 推論と引用付きで、QとDkからA*を生成するよう、監視付きファインチューニング (SFT) を用いてモデルを微調整する。
- RAFTがリトリーバーに依存しないことを示し、ドメイン内のRAG性能を向上させる。
- 訓練時およびテスト時の distractors の数 k と oracle コンテキストの割合 P の影響を検討する。

実験結果
リサーチクエスチョン
- RQ1 supervised fine-tuningをどのように適応させて、オープンブックQAのドメイン特化取得文を取り込むことができるか。
- RQ2 distractorsとCoT推論を用いた訓練は、標準のDSFまたはDSF+RAGベースラインと比較してドメイン内RAG性能を改善するか。
- RQ3訓練/テスト時の distractors の数と oracle コンテキストの有無は、ドメイン間で性能にどのように影響するか。
主な発見
| モデル | PubMed | HotpotQA | HuggingFace | Torch Hub | TensorFlow Hub |
|---|---|---|---|---|---|
| GPT-3.5 + RAG | 71.60 | 41.5 | 29.08 | 60.21 | 65.59 |
| LlaMA2-7B | 56.5 | 0.54 | 0.22 | 0 | 0 |
| LLaMA2-7B + RAG | 58.8 | 0.03 | 26.43 | 8.60 | 43.06 |
| DSF | 59.7 | 6.38 | 61.06 | 84.94 | 86.56 |
| DSF + RAG | 71.6 | 4.41 | 42.59 | 82.80 | 60.29 |
| RAFT (LLaMA2-7B) | 73.30 | 35.28 | 74.00 | 84.95 | 86.86 |
- RAFTは、PubMed、HotpotQA、Gorillaデータセット全体でドメイン特化RAG性能を一貫して向上させる。
- ベースラインと比較して、RAFTは顕著な利得を達成。例:HotpotQAで最大35.25%、Torch Hub評価で最大76.35%。
- Chain-of-Thought (CoT) 推論を組み込むと、複数データセットで訓練の頑健性と精度が著しく向上する。
- oracle文書と distractor文書の混合で訓練すると、テスト時の文書数の変動に対する頑健性が向上する。
- RAFTはDSF+RAGあり・なしのいずれでも改善し、同じ設定の下でGPT-3.5+RAGのような大規模モデルを上回ることが多い。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。