[論文レビュー] Rate-Perception Optimized Preprocessing for Video Coding
The paper proposes a rate-perception optimized preprocessing (RPP) that pre-processes frames with a lightweight network and adaptive DCT loss to reduce bitrate while preserving perceptual quality, achieving significant BD-rate savings across AVC, HEVC, VVC, and AV1 without changing encoder/decoder settings.
In the past decades, lots of progress have been done in the video compression field including traditional video codec and learning-based video codec. However, few studies focus on using preprocessing techniques to improve the rate-distortion performance. In this paper, we propose a rate-perception optimized preprocessing (RPP) method. We first introduce an adaptive Discrete Cosine Transform loss function which can save the bitrate and keep essential high frequency components as well. Furthermore, we also combine several state-of-the-art techniques from low-level vision fields into our approach, such as the high-order degradation model, efficient lightweight network design, and Image Quality Assessment model. By jointly using these powerful techniques, our RPP approach can achieve on average, 16.27% bitrate saving with different video encoders like AVC, HEVC, and VVC under multiple quality metrics. In the deployment stage, our RPP method is very simple and efficient which is not required any changes in the setting of video encoding, streaming, and decoding. Each input frame only needs to make a single pass through RPP before sending into video encoders. In addition, in our subjective visual quality test, 87% of users think videos with RPP are better or equal to videos by only using the codec to compress, while these videos with RPP save about 12% bitrate on average. Our RPP framework has been integrated into the production environment of our video transcoding services which serve millions of users every day.
研究の動機と目的
- Motivate preprocessing as a means to improve rate-distortion performance in both traditional and learned video codecs.
- Introduce an adaptive DCT loss to preserve high-frequency details while reducing spatial redundancy.
- Design a lightweight CNN with attention for efficient preprocessing and integrate full-reference IQA for perceptual quality.
- Demonstrate plug-and-play Deployment with standard codecs (AVC, HEVC, VVC, AV1) without encoder changes.
- Quantify bitrate savings (BD-rate) and subjective quality gains on multiple datasets and codecs.
提案手法
- Develop adaptive DCT loss to selectively keep high-frequency components based on DCT coefficient magnitude and a threshold derived from the coefficients.
- Incorporate a rate-perception optimized preprocessor (RPP) as a light-weight fully convolutional network with channel attention and efficient up/downsampling.
- Model image degradation with higher-order degradation to simulate real-world artifacts during training.
- Train with a joint loss combining adaptive DCT loss, MS-SSIM perceptual loss, and L1 reconstruction loss, with tunable weights.
- Deploy as a single-pass preprocessor; the preprocessed frame f_p is encoded by standard codecs without changing encoder/decoder settings.

実験結果
リサーチクエスチョン
- RQ1Can a preprocessing stage improve bitrate without modifying existing codecs?
- RQ2Does an adaptive DCT-based loss better preserve perceptually important high-frequency content while enabling bitrate savings?
- RQ3How does joint optimization with MS-SSIM and degradation modeling affect RD performance across multiple codecs?
- RQ4What is the practical inference efficiency of RPP on common hardware?
- RQ5Is the approach robust across datasets and presets (very fast/medium) for H.264/HEVC/VVC/AV1?
主な発見
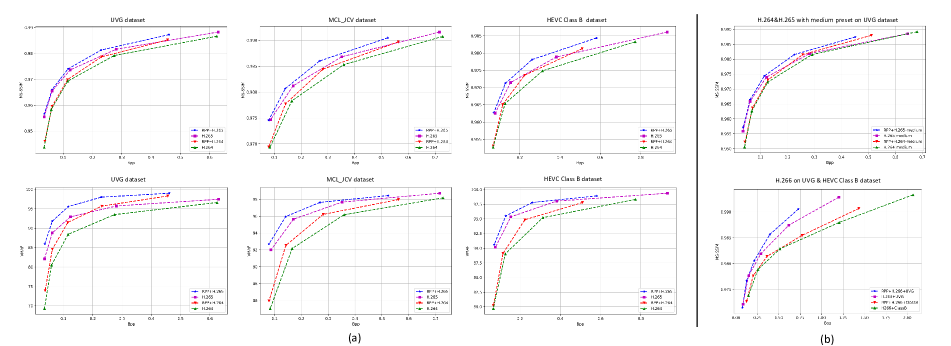
| Dataset | Codec | Metric | BD-Rate |
|---|---|---|---|
| UVG | RPP+H.264(veryfast) | VMAF | -26.92 |
| UVG | RPP+H.264(veryfast) | MS-SSIM | -4.86 |
| UVG | RPP+H.265(veryfast) | VMAF | -39.77 |
| UVG | RPP+H.265(veryfast) | MS-SSIM | -8.70 |
| UVG | RPP+H.264(medium) | VMAF | -27.30 |
| UVG | RPP+H.264(medium) | MS-SSIM | -5.60 |
| UVG | RPP+H.265(medium) | VMAF | -39.24 |
| UVG | RPP+H.265(medium) | MS-SSIM | -9.58 |
| MCL-JCV | RPP+H.264 | VMAF | -11.84 |
| MCL-JCV | RPP+H.264 | MS-SSIM | -11.75 |
| MCL-JCV | RPP+H.265 | VMAF | -14.94 |
| MCL-JCV | RPP+H.265 | MS-SSIM | -19.90 |
| HEVC ClassB | RPP+H.264 | VMAF | -11.84 |
| HEVC ClassB | RPP+H.264 | MS-SSIM | -11.75 |
| HEVC ClassB | RPP+H.265 | VMAF | -14.94 |
| HEVC ClassB | RPP+H.265 | MS-SSIM | -19.90 |
- RPP yields average BD-rate savings around 16.27% across AVC, HEVC, and VVC under multiple metrics.
- Adaptive DCT loss contributes substantial bitrate savings, accounting for over 60% of the overall BD-rate improvement in the ablation study.
- RPP+H.265 consistently provides larger BD-rate reductions than H.264 across datasets and presets.
- Subjective tests show 87% of viewers consider RPP-augmented videos better or equal to codec-only videos, with about 12% bitrate savings on average.
- RPP supports real-time-like inference speeds (e.g., 87.7 FPS for 1080p on RTX 3090 in TensorRT), enabling practical deployment.
- RPP is plug-and-play, requiring only a single forward pass per frame before encoding, and does not require changes to encoder/decoder configurations.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。