[論文レビュー] Ray: A Distributed Framework for Emerging AI Applications
Ray は動的なタスク/アクター模型とスケーラブルで障害耐性のある実行エンジンを備え、強化学習ワークロードのトレーニング、シミュレーション、サービングを統合します;それは millions of tasks per second にスケールし、RL タスクにおいて専門化されたシステムを上回ります。
The next generation of AI applications will continuously interact with the environment and learn from these interactions. These applications impose new and demanding systems requirements, both in terms of performance and flexibility. In this paper, we consider these requirements and present Ray---a distributed system to address them. Ray implements a unified interface that can express both task-parallel and actor-based computations, supported by a single dynamic execution engine. To meet the performance requirements, Ray employs a distributed scheduler and a distributed and fault-tolerant store to manage the system's control state. In our experiments, we demonstrate scaling beyond 1.8 million tasks per second and better performance than existing specialized systems for several challenging reinforcement learning applications.
研究の動機と目的
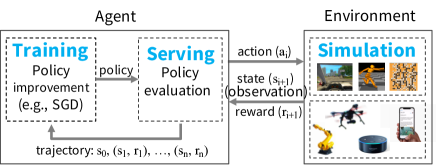
- 動的な環境で RL ワークロード(トレーニング、シミュレーション、サービング)を扱う統一フレームワークの必要性を喚起する。
- タスク並列とアクター ベースの計算の双方をサポートする単一の動的実行エンジンを提案する。
- 制御状態と系譜を管理するための分散スケジューラとメタデータストアを備えた、スケーラブルで障害耐性のあるシステムを設計する。
提案手法
- タスク(ステートレスなリモート関数)とアクター(ステートフルなオブジェクト)のための統一APIを導入する。
- 入力が利用可能になったときに自動で計算を開始する動的タスクグラフ実行モデルを実装する。
- 低遅延とスケーラビリティを達成するために、グローバルコントロールストア、ボトムアップ分散スケジューラ、インメモリオブジェクトストアを備えた Ray を設計する。
- 分割されたメタデータと系譜追跡によって制御状態と計算を分離し、障害耐性を確保する。
- ネストされたリモート関数とリソース認識スケジューリングを有効にして異種のワークロードに対応する。
実験結果
リサーチクエスチョン
- RQ1シミュレーション、分散トレーニング、ポリシーサービングを要する RL ワークロードを1つのフレームワークで効率的にサポートするにはどうすればよいか。
- RQ2動的で異種のタスクに対してミリ秒レベルの遅延、高スループット、障害耐性を実現するためのアーキテクチャ選択は何か。
- RQ3統合されたアクター/タスクモデルは、RL アプリケーションにおける組み合わせ型のマルチシステム手法を上回れるか。
主な発見
- Ray は 実験で 1.8 million tasks per second を超えるスケールを達成した。
- Ray は bottom-up distributed scheduler と sharded metadata store によりミリ秒レベルの遅延を実現する。
- The Global Control Store は stateless コンポーネントとスケーラブルな障害耐性のある系譜追跡を可能にする。
- Ray は局所性配慮型のタスク配置と大規模クラスターでほぼ線形のスケーラビリティを提供する。
- Ray はいくつかの RL アプリケーション(トレーニング、サービング、シミュレーション)で既存の特化システムよりも高い性能を示す。
- The object store は高いスループットを達成し、書き込みスループットが 15 GB/s を超え、同一ノード上でゼロコピーのデータ共有を可能にする。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。