[論文レビュー] RealmDreamer: Text-Driven 3D Scene Generation with Inpainting and Depth Diffusion
RealmDreamer は、2D 拡散事前学習、インペインティング、深度拡散を用いて 3D ガウシアンスプラッティングを初期化し、マルチビューデータなしで前方向きの 3D シーンをテキストから生成します。高忠実度のジオメトリとパララックスを実現します。
We introduce RealmDreamer, a technique for generating forward-facing 3D scenes from text descriptions. Our method optimizes a 3D Gaussian Splatting representation to match complex text prompts using pretrained diffusion models. Our key insight is to leverage 2D inpainting diffusion models conditioned on an initial scene estimate to provide low variance supervision for unknown regions during 3D distillation. In conjunction, we imbue high-fidelity geometry with geometric distillation from a depth diffusion model, conditioned on samples from the inpainting model. We find that the initialization of the optimization is crucial, and provide a principled methodology for doing so. Notably, our technique doesn't require video or multi-view data and can synthesize various high-quality 3D scenes in different styles with complex layouts. Further, the generality of our method allows 3D synthesis from a single image. As measured by a comprehensive user study, our method outperforms all existing approaches, preferred by 88-95%. Project Page: https://realmdreamer.github.io/
研究の動機と目的
- シーンスケールでの 3D ガウシアンスプラッティングを用いたテキストから 3D シーン合成の実証。
- ロバストな初期化とマルチビュー一貫性のための 2D 拡散事前学習の活用。
- インペインティングと深度拡散事前学習を取り入れて、disoccluded な領域を埋め、ジオメトリを改善。
- ディテール強調と不透明度正規化を備えたファインチューニング段階を提供し、細部を強化。
提案手法
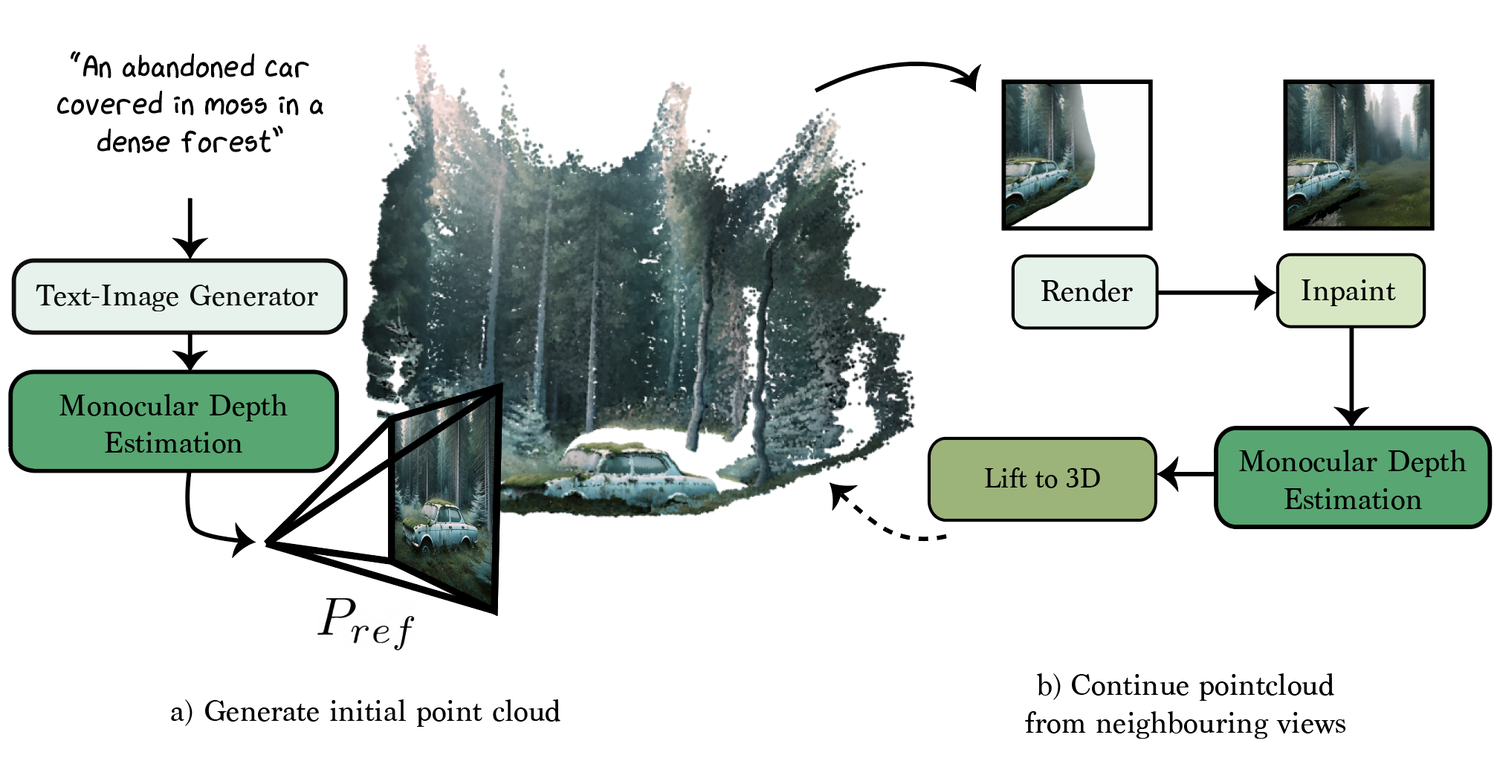
- テキストプロンプトから、2D 拡散事前学習と単眼深度を用いてシーンレベルの 3D ガウシアンスプラッティング表現を初期化; occlusion ボリュームを計算し、点群と組み合わせる。
- テキスト・画像・オクルージョンマスクを条件付けした 2D インペインティング拡散モデルを用いて、シーン完成をインペインティング問題として扱い、潜在空間と画像空間の損失、知覚損失およびアンカー項を組み合わせて最適化する。
- クリンなインペインティングサンプルを条件付けとして使用することで、画像条件付き深度拡散モデルから深度情報を蒸留し、ピアソン相関に基づく深度損失を最適化する。
- 細部をシャープにするファインチューニング段階を、個別のテキスト-to-image 拡散モデルで実施し、不透明度正規化を追加して二値的な不透明度を促進し、最終レンダリング品質を改善するサンプルにシャープニングフィルターを適用する。
- 実装は PyTorch3D、NeRFStudio、Stable Diffusion 2.0、Marigold depth estimation、DepthAnything の絶対深度スケーリングに依存する。
![Figure 2 : Our method, compared to the state-of-the-art ProlificDreamer [ 66 ] , shows significant improvements. ProlificDreamer’s public results, with outward-looking cameras from a scene-independent sphere, result in poor depth quality. Even with a complex training trajectory, ProlificDreamer yiel](https://ar5iv.labs.arxiv.org/html/2404.07199/assets/figures/vsd_failure.png)
実験結果
リサーチクエスチョン
- RQ1テキストプロンプトだけで動画やマルチビューデータなしに、3D シーンレベル生成をどのように実現できるか?
- RQ22D 拡散事前学習(インペインティングと深度)を 3D ガウシアンスプラッティング表現に蒸留して、ビュー間で整合のあるジオメトリを生み出せるか?
- RQ3頑健な初期化とその後のインペインティング/深度蒸留が、シーン忠実度とパララックスリアリズムに与える影響は?
- RQ4ファインチューニングとシャープニング段階は、テキストプロンプトへの整合を保ちつつディテールを向上させるか?
- RQ5提案されたパイプラインを用いて、単一画像から 3D 生成を効果的に拡張できるか?
主な発見
| 私たちの手法 | Text2Room | DreamFusion | ProlificDreamer |
|---|---|---|---|
| 33.14 | 25.10 | 30.28 | 30.69 |
- RealmDreamer は、パララックスと高忠実度のジオメトリを備えたテキストベースの 3D シーン生成において、最先端の定性的結果を達成。
- ベースラインと比較して、より整合性のあるジオメトリとシャープなレンダリングを生成し、クラウドiness や過飽和などのアーティファクトを減少。
- CLIP ベースの評価では、RealmDreamer が Text2Room、DreamFusion、ProlificDreamer よりもシーンごとにプロンプトへの整合性が高いと示された。
- インペインティング拡散、深度事前学習、頑健な初期化、シャープニングの重要性を検証するアブレーション研究。
- この手法は、キャプション付きのプロンプトと組み合わせることで、単一画像からの 3D シーン生成も可能。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。