[論文レビュー] Reasoning before Comparison: LLM-Enhanced Semantic Similarity Metrics for Domain Specialized Text Analysis
本論文はGPT-4を用いて放射線科レポートに臨床的に意味のあるラベルを生成し、埋め込みを用いた意味的類似性を測定する。真の基準データに対して従来の語彙メトリクス(ROUGE/BLEU)を上回る。
In this study, we leverage LLM to enhance the semantic analysis and develop similarity metrics for texts, addressing the limitations of traditional unsupervised NLP metrics like ROUGE and BLEU. We develop a framework where LLMs such as GPT-4 are employed for zero-shot text identification and label generation for radiology reports, where the labels are then used as measurements for text similarity. By testing the proposed framework on the MIMIC data, we find that GPT-4 generated labels can significantly improve the semantic similarity assessment, with scores more closely aligned with clinical ground truth than traditional NLP metrics. Our work demonstrates the possibility of conducting semantic analysis of the text data using semi-quantitative reasoning results by the LLMs for highly specialized domains. While the framework is implemented for radiology report similarity analysis, its concept can be extended to other specialized domains as well.
研究の動機と目的
- Lexical similarity metrics (ROUGE/BLÉU) の医療テキスト分析における限界を動機づけ、解決する。
- GPT-4 が報告からタスクベースのラベルを生成し、意味的に分類する枠組みを提案する。
- 人間が介入する概念を組み込み、ラベルの解釈性と臨床関連性を向上させる。
- MIMIC-CXR の CheXpert/NegBio アノテーションを真の基準とした意味ラベルベースの類似性を評価する。
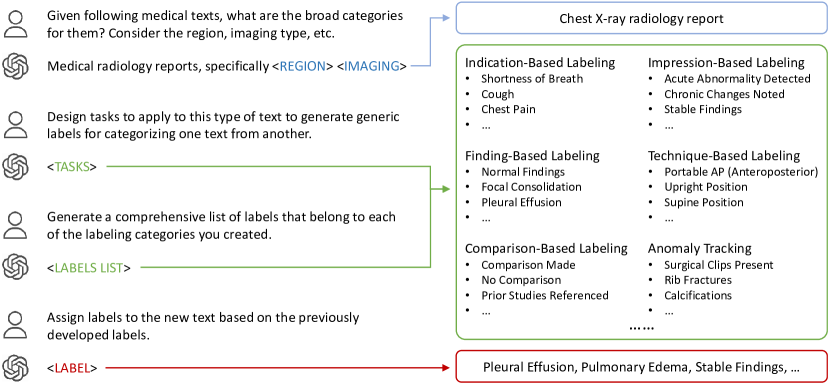
提案手法
- 放射線科レポートのゼロショットテキスト識別にGPT-4を使用する。
- GPT-4 がレポートからタスクと汎用ラベルを生成し、意味的カテゴリ分けを行う。
- 臨床関連性を確保するためにヒューマン・イン・ザ・ループによるラベル作成を行う。
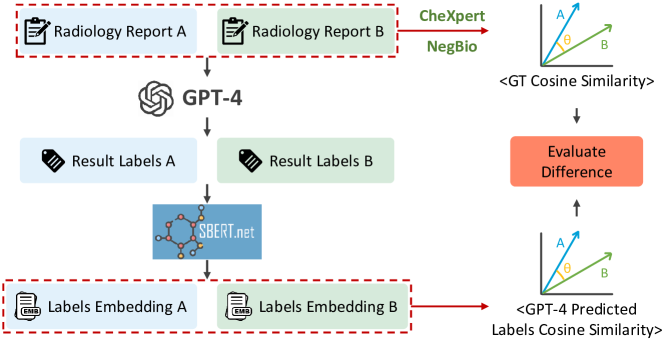
- GPT-4 生成ラベルを all-mpnet-base-v2 に埋め込み、コサイン類似度で意味的類似性を計算する。
- GPT-4 ラベルベースの類似性を CheXpert/NegBio の真の基準および従来の ROUGE/BLEU メトリクスと比較する(62,500 ペアのレポート比較)。
実験結果
リサーチクエスチョン
- RQ1GPT-4 は臨床的に意味のあるラベルを生成し、放射線レポートと真の所見と意味的に整合させることができるか。
- RQ2GPT-4 が生成したラベルの意味的類似性は、従来の語彙メトリクスより真の基準とより密に相関するか。
- RQ3ドメイン特有の医療テキスト分析における意味ラベル類似性と ROUGE/BLEU の相対性能はどうか。
主な発見
- GPT-4 が生成した類似性(GPT_sim)は、ROUGE および BLEU メトリクスよりも真の基準とより近い整合性を示す。
- GPT_sim の CheXpert/NegBio への平均類似度: 0.1768 および 0.1793。
- GT 比較に対する ROUGE-1_F1、ROUGE-2_F1、ROUGE-L_F1 のスコアは 0.3654 から 0.5827 の範囲。
- BLEU スコアはおおよそ 0.6 だが、GPT_sim より真の基準からの乖離が大きい。
- 真の基準ベースの評価には MIMIC-CXR および CheXpert/NegBio ラベルに由来する 62,500 レポートペアの比較を使用。
- この方法論は従来の語彙メトリクスと比較して医療テキストの意味的把握を優位に示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。