[論文レビュー] Recent advances in text embedding: A Comprehensive Review of Top-Performing Methods on the MTEB Benchmark
この調査はMTEB上でのトップパフォーマンスを示すユニバーサルテキスト埋め込みを分析し、データ、損失、LLMベースのアプローチを2023–2024年から詳述し、トレンドとギャップを概説する。
Text embedding methods have become increasingly popular in both industrial and academic fields due to their critical role in a variety of natural language processing tasks. The significance of universal text embeddings has been further highlighted with the rise of Large Language Models (LLMs) applications such as Retrieval-Augmented Systems (RAGs). While previous models have attempted to be general-purpose, they often struggle to generalize across tasks and domains. However, recent advancements in training data quantity, quality and diversity; synthetic data generation from LLMs as well as using LLMs as backbones encourage great improvements in pursuing universal text embeddings. In this paper, we provide an overview of the recent advances in universal text embedding models with a focus on the top performing text embeddings on Massive Text Embedding Benchmark (MTEB). Through detailed comparison and analysis, we highlight the key contributions and limitations in this area, and propose potentially inspiring future research directions.
研究の動機と目的
- MTEBベンチマークで優先されるユニバーサルテキスト埋め込みをレビューし、それらの検索・分類・クラスタリング・その他のタスクへの関連性を動機付けとする。
- データ重視、損失重視、LLM重視の系統に文献を整理し、ユニバーサル埋め込みの発展方向を明確にする。
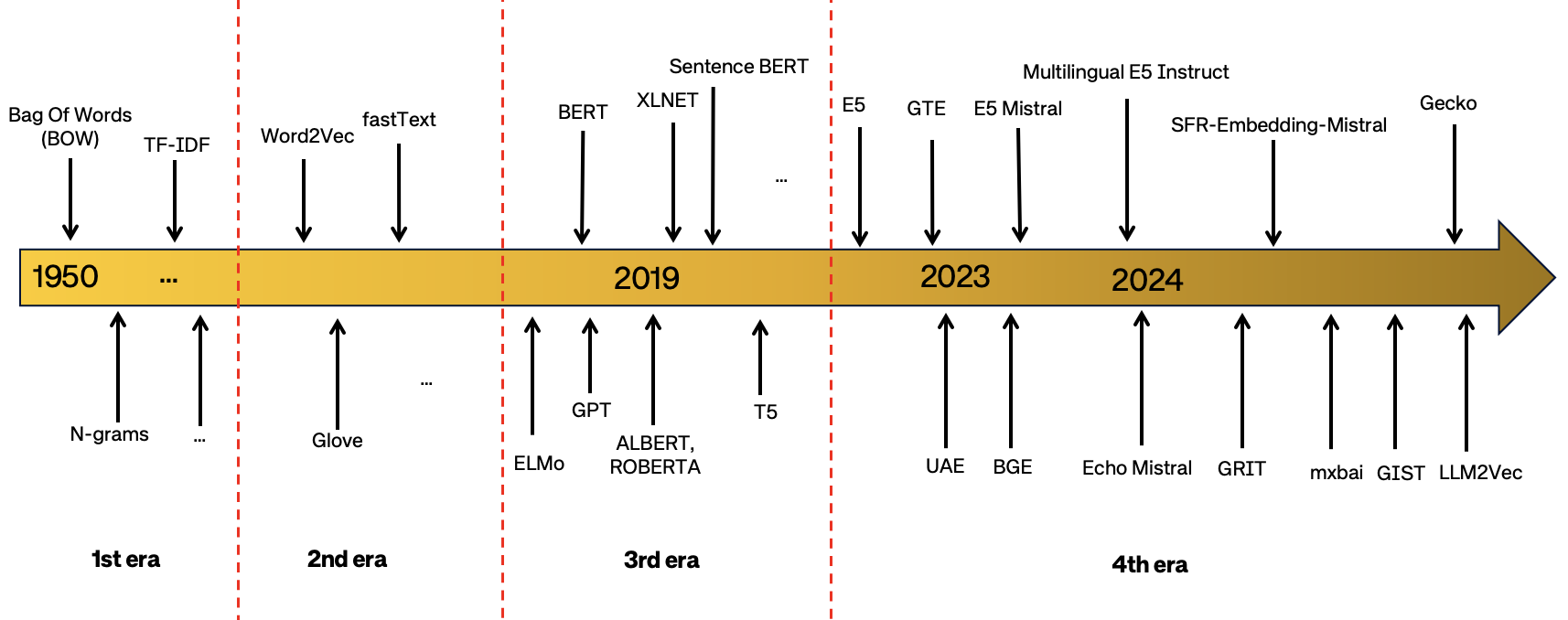
- 主要なアーキテクチャ(例:GTE、BGE、E5、UAE、Multilingual-E5)を要約し、データ品質、多様性、トレーニングシグナルが性能にどう影響するかを説明する。
- MTEBのマルチタスク・多言語評価設定が、タスク横断の汎化を促進するモデル設計を導くことを強調する。
提案手法
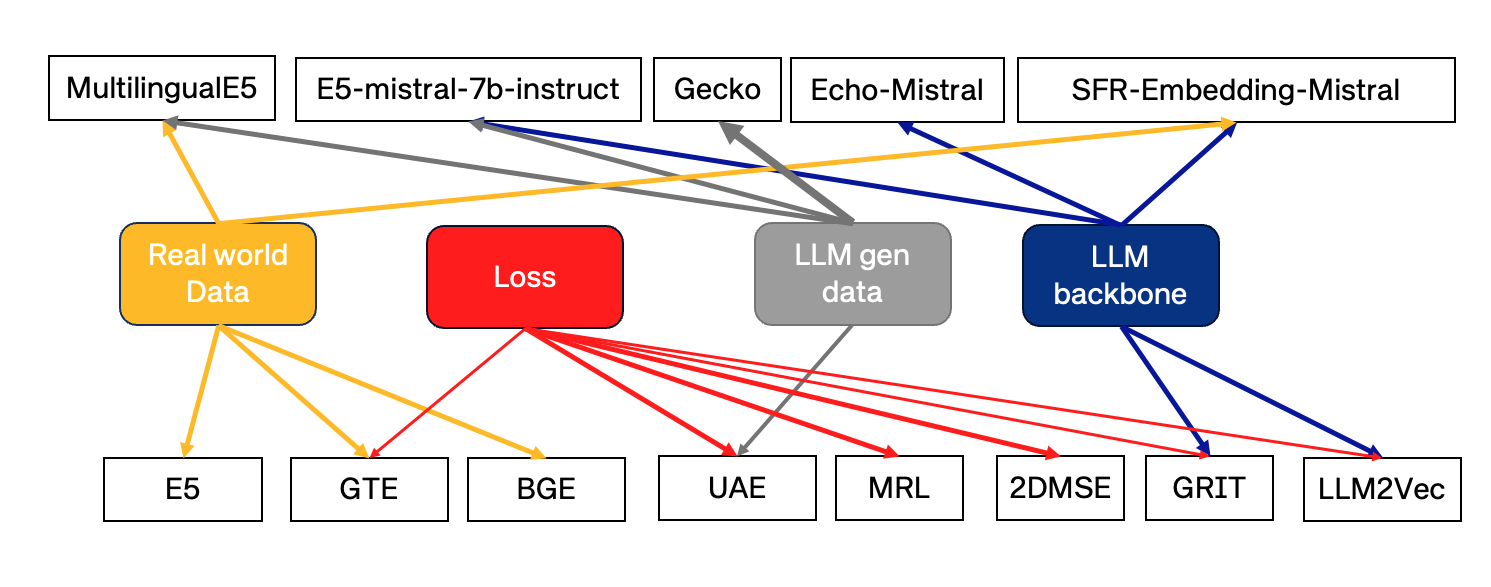
- 大規模で多様な事前学習と高品質なファインチューニングデータ(例:CCPairs、CCベースのソース、マルチデータセットの混合など)を通じてユニバーサル埋め込みを強化するデータ重視の戦略を検討する。
- コントラスト学習を改善し、勾配の問題に対処する損失関数の革新を説明する(例:改良版InfoNCEの変種、UAEにおける角度最適化)。
- 事前学習およびファインチューニング段階におけるハードネガティブ、バッチ内ネガティブ、知識蒸留の役割を説明する。
- LLMsがデータアノテータとして、またはバックボーンとして普遍性と多言語性を高める方法を概説する(例:合成データ、指示調整、クロスエンコーダ蒸留)。
- 方法全体で使用されるバックボーンモデルとトレーニングレジームを要約する(BERTファミリー、RoBERTa、長距離トランスフォーマー、デコーダーのみのLLMs)。
実験結果
リサーチクエスチョン
- RQ1MTEBの文脈におけるユニバーサルテキスト埋め込みの定義は何か、データ・損失・モデル選択がタスク横断の汎化にどう影響するか?
- RQ2トップパフォーマンスの手法は、データ品質・多様性・合成データをどのように活用して58のデータセットと112の言語で性能を向上させるか?
- RQ3現在のデータ・損失・LLM重視のアプローチにおける限界とトレードオフは何か?
- RQ4LLMsはタスクと言語を横断してユニバーサル埋め込みを改善するバックボーンやアノテータとしてどの程度効果的に機能するか?
- RQ5テキスト埋め込みの普遍性と効率をさらに高める今後の方向性は何か?
主な発見
- MTEBのトップモデルは、広範なタスクカバレッジを達成するために、大規模で多様な事前学習と高品質なファインチューニングデータに依存している。
- 損失の革新と勾配問題の取り扱い(例:角度最適化)が、最適化と埋め込み品質の向上に寄与している。
- バッチ内ネガティブ・ハードネガティブサンプリング、クロスエンコーダからの蒸留を組み合わせることで、検索性能と代表例品質の埋め込みを高める。
- LLMsはデータアノテータとバックボーンモデルの両方としてますます活用され、多言語・マルチタスク性能を向上させている。
- Multilingual-E5と関連モデルは、クロス言語の普遍性のための多言語データ混合と指示データの価値を示している。
- 調査された手法はユニバーサルテキスト埋め込みの顕著な改善を示しているが、未知のタスクやドメインでの汎化には依然として課題が残る。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。