[論文レビュー] Recommendation as Instruction Following: A Large Language Model Empowered Recommendation Approach
本論文は InstructRec を提案する。これは推奨を指示の遵守として扱うレコメンダーシステムで、3B Flan-T5-XL LLM を微調整し、個人化と一般化を向上させるためにユーザー中心の自然言語指示を大量に用いる。
In the past decades, recommender systems have attracted much attention in both research and industry communities, and a large number of studies have been devoted to developing effective recommendation models. Basically speaking, these models mainly learn the underlying user preference from historical behavior data, and then estimate the user-item matching relationships for recommendations. Inspired by the recent progress on large language models (LLMs), we take a different approach to developing the recommendation models, considering recommendation as instruction following by LLMs. The key idea is that the preferences or needs of a user can be expressed in natural language descriptions (called instructions), so that LLMs can understand and further execute the instruction for fulfilling the recommendation task. Instead of using public APIs of LLMs, we instruction tune an open-source LLM (3B Flan-T5-XL), in order to better adapt LLMs to recommender systems. For this purpose, we first design a general instruction format for describing the preference, intention, task form and context of a user in natural language. Then we manually design 39 instruction templates and automatically generate a large amount of user-personalized instruction data (252K instructions) with varying types of preferences and intentions. To demonstrate the effectiveness of our approach, we instantiate the instruction templates into several widely-studied recommendation (or search) tasks, and conduct extensive experiments on these tasks with real-world datasets. Experiment results show that the proposed approach can outperform several competitive baselines, including the powerful GPT-3.5, on these evaluation tasks. Our approach sheds light on developing more user-friendly recommender systems, in which users can freely communicate with the system and obtain more accurate recommendations via natural language instructions.
研究の動機と目的
- 推奨をLLMsによる指示追従として扱う概念を導入する。
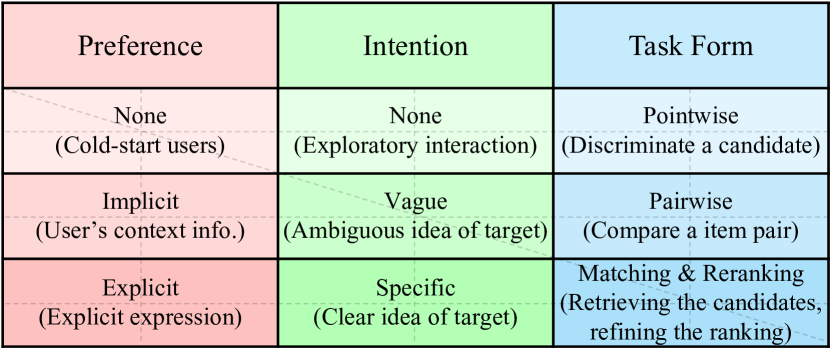
- ユーザーの嗜好、意図、タスク形態、文脈を捉える柔軟な指示形式を設計する。
- 推奨タスクのためにLLMを微調整するための大規模で高品質な指示データセットを生成する。
- 実世界のデータセットとタスクで InstructRec の有効性と一般化を実証する。
提案手法
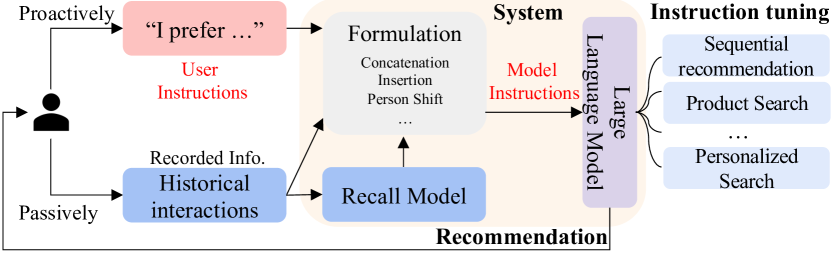
- 嗜好、意図、タスク形態、文脈を含む推奨の統一指示形式を定義する。
- 手動で39の粗粒度指示テンプレートを設計し、GPT-3.5を教師LLMとして使用して252Kの細粒度ユーザー指示を自動生成する。
- 指示データで3B Flan-T5-XLモデルを微調整し、推奨の指示追従を可能にする。
- 訓練済みLLMをリランキングに使用して候補セットから最終的なアイテム順位を生成する。
- 指示の多様性を高める戦略(例:入力出力の入れ替え、CoT推論)を提供し、ユーザーニーズに合わせた整合性を確保する。
実験結果
リサーチクエスチョン
- RQ1推奨タスクは効果的にLLMsの指示追従として定式化できるか。
- RQ2指示形式、データ生成、微調整が推奨品質と一般化にどう影響するか。
- RQ3InstructRec はベースラインを上回り、見たことのないドメイン/指示へ一般化するか。
- RQ4指示の多様性がモデル性能に与える影響は何か。
主な発見
- InstructRec は評価タスクで GPT-3.5 を含むいくつかの競合ベースラインを上回ることができる。
- このアプローチはLLM の能力の多様なユーザーニーズへの対応能力を向上させ、保持していない指示やドメインへの一般化能力を改善する。
- 252K の大規模で高品質な指示データセットは、レコメンダーシステムの効果的な指示微調整を支える。
- 指示形式は推奨を導くために、ユーザーの嗜好、意図、タスク形態、文脈を効果的に捉える。
- 指示の多様性を高め、CoT のような推論を組み込むことで性能をさらに向上させることができる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。