[論文レビュー] Redefining "Hallucination" in LLMs: Towards a psychology-informed framework for mitigating misinformation
この論文は、LLMのエラーに対する一般用語『hallucination(幻覚)』が誤解を招くと主張し、心理学に基づく分類法(source amnesia、recency、availability、suggestibility、cognitive dissonance、confabulation)とメタ認知に基づく緩和戦略を提案する。
In recent years, large language models (LLMs) have become incredibly popular, with ChatGPT for example being used by over a billion users. While these models exhibit remarkable language understanding and logical prowess, a notable challenge surfaces in the form of "hallucinations." This phenomenon results in LLMs outputting misinformation in a confident manner, which can lead to devastating consequences with such a large user base. However, we question the appropriateness of the term "hallucination" in LLMs, proposing a psychological taxonomy based on cognitive biases and other psychological phenomena. Our approach offers a more fine-grained understanding of this phenomenon, allowing for targeted solutions. By leveraging insights from how humans internally resolve similar challenges, we aim to develop strategies to mitigate LLM hallucinations. This interdisciplinary approach seeks to move beyond conventional terminology, providing a nuanced understanding and actionable pathways for improvement in LLM reliability.
研究の動機と目的
- Critically assess the term 'hallucination' in LLMs and its adequacy for describing model outputs.
- Propose a psychology-based taxonomy mapping LLM errors to cognitive biases and memory phenomena.
- Suggest concrete mitigation strategies inspired by human metacognition and source monitoring.
- Advocate for targeted mitigation pathways that leverage psychological constructs to improve LLM reliability.
提案手法
- Review and synthesize existing definitions and taxonomies of LLM hallucinations.
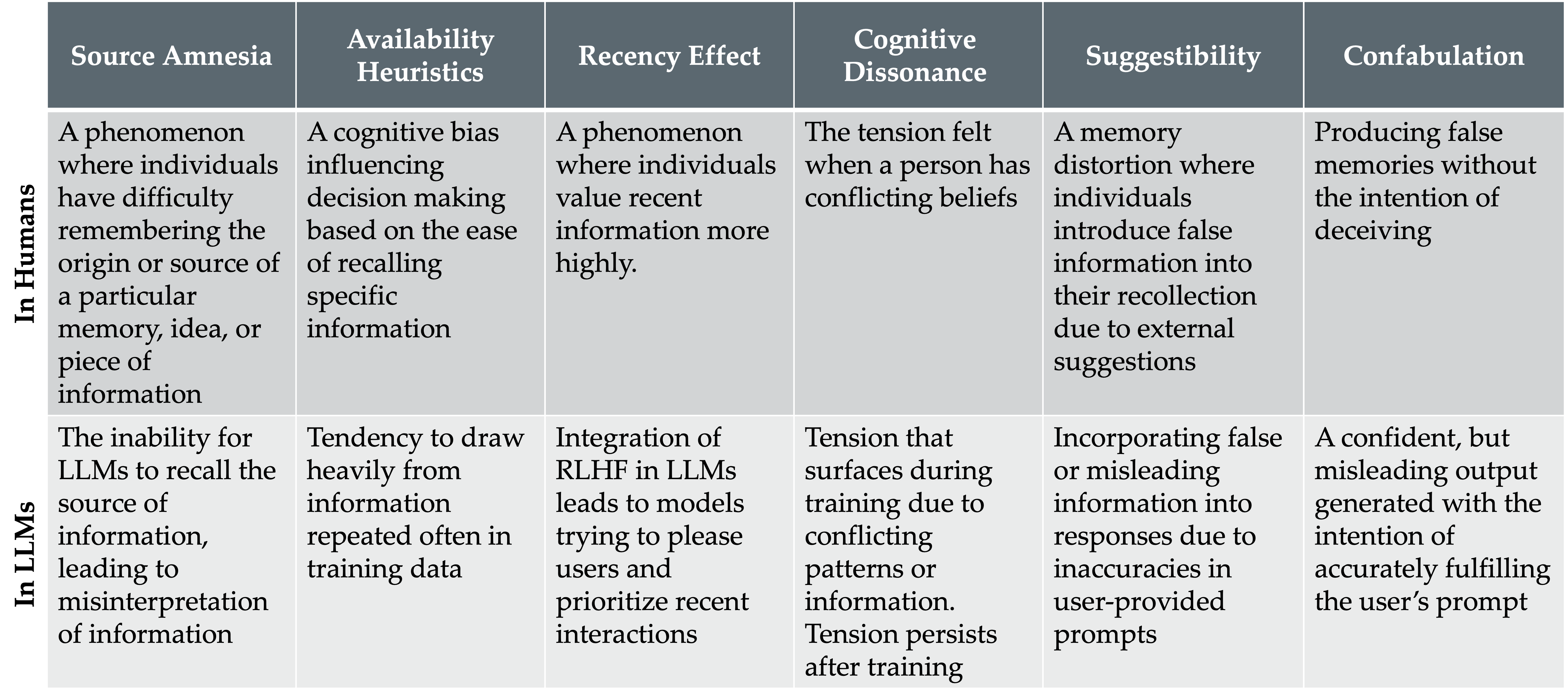
- Map identified phenomena to psychological concepts: source amnesia, recency effect, availability heuristics, suggestibility, cognitive dissonance, confabulation.
- Argue for and describe a psychology-informed taxonomy as an alternative to task-specific hallucination labels.
- Discuss potential metacognitive-inspired strategies (enhanced source attribution, source monitoring, reflective processing, artificial metacognition).
- Cite related works on self-reflection and self-inquiry as parallels to proposed mitigations.

実験結果
リサーチクエスチョン
- RQ1How well does the term 'hallucination' capture the phenomena observed in LLM outputs?
- RQ2Can a psychology-based taxonomy more precisely categorize LLM errors than existing intrinsic/extrinsic or task-specific labels?
- RQ3What mitigation strategies inspired by human metacognition could reduce LLM misinformation?
- RQ4Which psychological constructs best align with different error types in LLMs to inform targeted fixes?
主な発見
- A psychology-informed taxonomy aligns LLM error types with known cognitive biases and memory phenomena.
- Source amnesia, recency effect, availability heuristics, suggestibility, cognitive dissonance, and confabulation map to distinct but overlapping LLM failure modes.
- Metacognition-inspired strategies (source attribution, monitoring, reflective processing) are proposed as practical avenues to mitigate misinformation in LLMs.
- Self-reflection and self-inquiry approaches from related works demonstrate potential for reducing hallucination-like outputs.
- The paper argues for moving beyond 'hallucination' terminology to enable more precise, targeted mitigation.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。