[論文レビュー] Reduce, Reuse, Recycle: Compositional Generation with Energy-Based Diffusion Models and MCMC
本論文は、拡散モデルを MCMC sampling とエネルギー基盤のパラメータ化と組み合わせることで、画像およびテキスト-画像タスク全体で正確な組成生成を可能にし、従来の逆拡散サンプリングをいくつかの設定で上回る方法を示している。
Since their introduction, diffusion models have quickly become the prevailing approach to generative modeling in many domains. They can be interpreted as learning the gradients of a time-varying sequence of log-probability density functions. This interpretation has motivated classifier-based and classifier-free guidance as methods for post-hoc control of diffusion models. In this work, we build upon these ideas using the score-based interpretation of diffusion models, and explore alternative ways to condition, modify, and reuse diffusion models for tasks involving compositional generation and guidance. In particular, we investigate why certain types of composition fail using current techniques and present a number of solutions. We conclude that the sampler (not the model) is responsible for this failure and propose new samplers, inspired by MCMC, which enable successful compositional generation. Further, we propose an energy-based parameterization of diffusion models which enables the use of new compositional operators and more sophisticated, Metropolis-corrected samplers. Intriguingly we find these samplers lead to notable improvements in compositional generation across a wide set of problems such as classifier-guided ImageNet modeling and compositional text-to-image generation.
研究の動機と目的
- 単純な拡散モデルの組成が失敗する理由を動機付け、サンプラーの制限を根本原因として特定する。
- 再学習せずに正しい組成生成を可能にするため、MCMC-based sampling とエネルギー基盤のパラメータ化を提案する。
- 2D、CLEVR風の形状、ImageNet分類器ガイダンス、およびテキストから画像への合成に跨る組成生成の改善を実証する。
- エネルギー基盤の拡散が、積、混合、否定など、より柔軟で洗練された組成演算子を可能にすることを示す。
提案手法
- 拡散モデルをスコアベース/ノイズ除去スコアマッチングの視点で位置づけ、Bayesの定理とガイダンススケールを介した条件付きガイダンスを検討する。
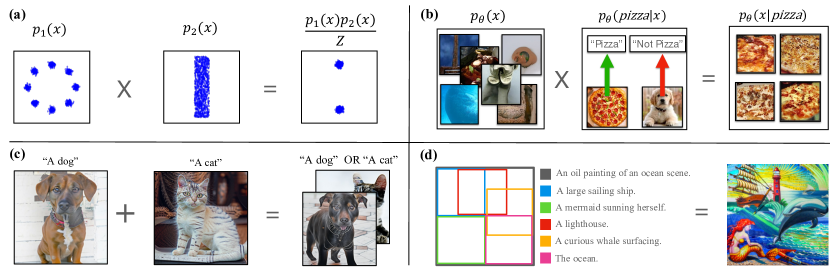
- 組成演算子:積( product )、混合( mixture )、否定( negation )を導入・分析し、ナイーブなスコアベースの結合がなぜ失敗し得るかを示す。
- アニーリングされた MCMC サンプラー(ULA、HMC のバリアント)を提案し、組成分布からのサンプリングを行い、メトロポリス補正付きの派生(MALA、MALA風、HMC)を含む。
- 明示的な未正規化対数密度を得るため、ε_theta(x,t) = -∇x f_theta(x,t) を用いたエネルギー基盤のパラメータ化 f_theta(x,t) を採用し、Metropolis 調整とより豊かな組成を可能にする。
- エネルギー基盤のパラメータ化が、組成分布を忠実にサンプリングする MCMC によるサンプリングを可能にすることを示す。
- このアプローチを、2D 密度、CLEVR風の立方体配置、ImageNet分類器ガイド生成、およびテキスト-to-画像組成に適用し、タペストリー風の多段階コンテンツを含む。
実験結果
リサーチクエスチョン
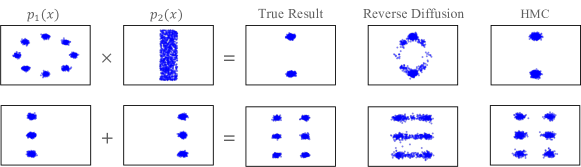
- RQ1標準的な逆拡散を用いて、再学習なしで拡散モデルの組成をサンプル正しく実現できるか。
- RQ2MCMCベースのサンプリング(ULA、HMC、Metropolis 補正の有無を問わず)が組成分布に忠実なサンプルを生み出すか、そしてエネルギー基盤パラメータ化はこれにどう影響するか。
- RQ3さまざまな領域(2D、3D風の形状、ImageNet、テキスト-to-画像)にわたって積( product )・混合( mixture )・否定( negation )といった組成演算子を適用したときの、サンプル品質と忠実度の実務的な改善は何か。
- RQ4エネルギー基盤の拡散モデルは、スコアベースのパラメータ化と比べて、より高度なサンプラーと組成をどのように可能にするか。
主な発見
- ナイーブな逆拡散サンプリングは、拡散モデルのアンサンブルにおいて、組成分布(積/混合)を忠実に実現できない。
- アニーリングされた MCMC サンプリング(ULA、HMC)は、組成モデルからのサンプルを改善し、Metropolis 調整がさらなる改善をもたらす。
- 明示的な対数密度を可能にするエネルギー基盤パラメータ化は、効果的な Metropolis 補正サンプラー(MALA、HMC)を可能にし、組成タスクで顕著な改善をもたらす。
- 2D 密度、CLEVR風の立方体条件付け、ImageNet分類器ガイド生成、およびテキスト-to-画像組成全体において、エネルギー基盤パラメータ化を用いた MCMC ベースのサンプリングは、忠実度と定量指標(RAISE/LL/MMDベースの評価; 分類器ガイド付き ImageNet での Inception Score および FID の改善)で高い成果を示す。
- このアプローチはテキスト-to-画像組成とイメージタペストリー生成を可能にし、結果は組成の成功はモデルだけでなくサンプリング手法にも左右されることを示唆している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。