[論文レビュー] REFLECT: Summarizing Robot Experiences for Failure Explanation and Correction
REFLECTは階層的で多感覚のロボット要約を用いてLLMsに故障の説明と修正計画を問いかけ、RoboFailで評価します。シミュレーションと現実世界データの両方を用いて。
The ability to detect and analyze failed executions automatically is crucial for an explainable and robust robotic system. Recently, Large Language Models (LLMs) have demonstrated strong reasoning abilities on textual inputs. To leverage the power of LLMs for robot failure explanation, we introduce REFLECT, a framework which queries LLM for failure reasoning based on a hierarchical summary of robot past experiences generated from multisensory observations. The failure explanation can further guide a language-based planner to correct the failure and complete the task. To systematically evaluate the framework, we create the RoboFail dataset with a variety of tasks and failure scenarios. We demonstrate that the LLM-based framework is able to generate informative failure explanations that assist successful correction planning.
研究の動機と目的
- 過去の失敗を自動的に振り返ることによって、頑健で説明可能なロボティクスを動機づける。
- 故障推論のための多感覚・階層的なロボット経験の要約を開発する。
- 自然言語の故障説明と修正計画を生成するために大規模言語モデルを活用する。
- 評価のためのロボット故障デモのデータセットであるRoboFailを作成・活用する。)
- method: [
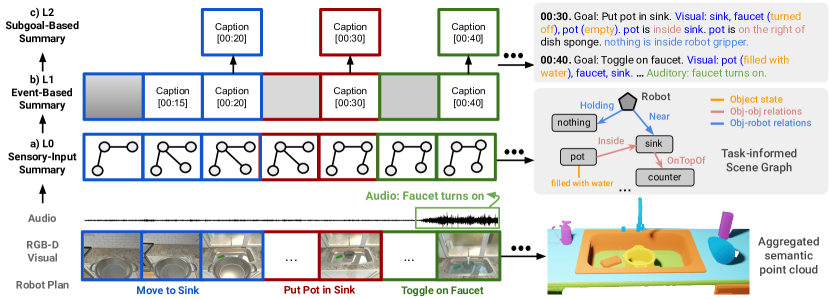
- 3段階の階層的ロボット要約(感覚入力・イベントベース・サブゴールベース)を多感覚観測(RGB-D、音声、状態)から構築する。
- 感覚データをタスク情報を組み込んだシーングラフと音声キャプションに変換して、有益な要約とする。
- 逐次的にLLMを照会し、まずサブゴールの成功を検出し、次に要約の関連履歴を用いて故障説明を生成する。
- LLMに修正計画を作成させ、生成された行動を埋め込みベースのマッチングで実行可能な環境アクションにマッピングする。)
- research_questions: [
- 階層的で多感覚の要約は、LLMsを介して正確な故障の局在化と説明を可能にするか?
- 逐次的な故障説明は、非逐次照会と比べて局在化と説明の質を改善するか?
- LLM生成の修正計画は、シミュレーションと現実世界のロボットタスクの故障を効果的に修正できるか?
- 音声モダリティの含有が説明と局在化の性能に与える影響はどの程度か?
- 故障処理におけるREFLECTと、キャプションベースや説明なしのベースラインを比較するとどうなるか?
提案手法
- Construct a three-level hierarchical robot summary (sensory-input, event-based, subgoal-based) from multisensory observations (RGB-D, audio, states).
- Translate sensory data into a task-informed scene graph and audio captions for informative summaries.
- Progressively query an LLM to first detect subgoal success, then generate failure explanations using relevant history from the summaries.
- Ask the LLM to produce a correction plan; map generated actions to executable environment actions using embedding-based matching.

実験結果
リサーチクエスチョン
- RQ1Can a hierarchical, multisensory summary enable accurate failure localization and explanation via LLMs?
- RQ2Do progressive failure explanations improve localization and explanation quality over non-progressive querying?
- RQ3Can LLM-generated correction plans effectively fix failures in simulated and real-world robot tasks?
- RQ4What is the impact of including audio modality on explanation and localization performance?
- RQ5How does REFLECT compare to caption-based or no-explanation baselines in failure handling?
主な発見
| 手法 | 実行時の説明 | 実行時の局在化 | 実行時の共計画 | 計画時の説明 | 計画時の局在化 | 計画時の共計画 |
|---|---|---|---|---|---|---|
| 逐次性なし | 46.5 | 62.8 | 60.5 | 61.4 | 70.2 | 64.9 |
| サブゴールのみ | 76.7 | 74.4 | 51.2 | 71.9 | 73.7 | 75.4 |
| LLM 要約 | 55.8 | 67.4 | 65.1 | 57.9 | 54.4 | 66.7 |
| 説明なし | - | - | 41.9 | - | - | 56.1 |
| REFLECT | 88.4 | 96.0 | 79.1 | 84.2 | 80.7 | 80.7 |
- REFLECT achieves the highest scores for explanation, localization, and correction planning in simulation compared to baselines.
- In simulation, REFLECT reaches about 88.4% explanation, 96.0% localization, and 79.1% correction planning success for execution failures; 84.2%, 80.7%, and 80.7% for planning failures.
- In real-world experiments, REFLECT outperforms baselines with 68.8% explanation and 93.8% localization for execution failures, and 78.6% explanation and 78.6% localization for planning failures.
- Ablations show that progressive failure explanation improves performance over non-progressive baselines; audio helps explain failures inaccessible to vision alone.
- BLIP2 captions perform poorly for failure explanation, while zero-shot, task-relevant summaries capture necessary object-state and spatial-relational information.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。